
Oren Bahari
78 posts

I built a cymatics-inspired sand simulation where sound shapes grains into patterns. Watching chaos organize itself never gets old.
English
@clarejtbirch Wow it's so snappy 🤩 If you could hook me to be a beta customer let me know! I have probably one of the wildest use cases for fast, parallel audio tool calling
English

AI changes us. Thinking Machines exists to build AI tools that increase human participation, preserve dignity across different minds, and move fast without severing society from our slower layers of memory, culture, and care.
Interaction models are such a tool: an experiment in real-time, full-duplex, multimodal-native ways of working with AI.
Make the computer disappear.
Thinking Machines@thinkymachines
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way. We share our approach, early results, and a quick look at our model in action. thinkingmachines.ai/blog/interacti…
English
Oren Bahari retweetledi

New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
English
Oren Bahari retweetledi

Every so often I think about how, in 2022, for $24B we could had "prototype vaccines ready for each of the 26 known viral families that cause human disease" so they can be deployed in 100 days if there was ever a need.
This effort was not funded. ifp.org/why-barda-dese…

English
Oren Bahari retweetledi


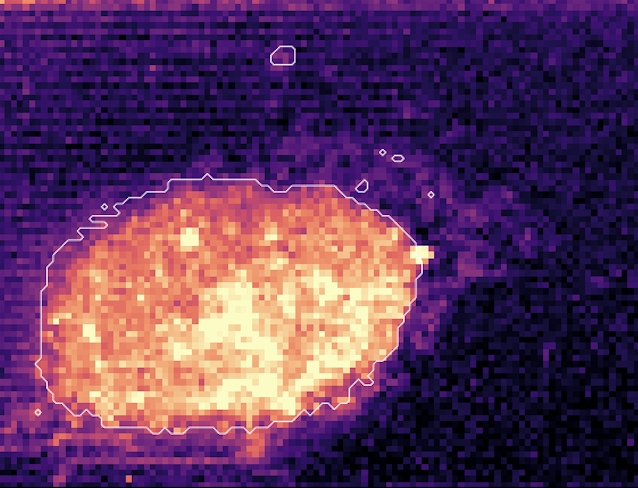
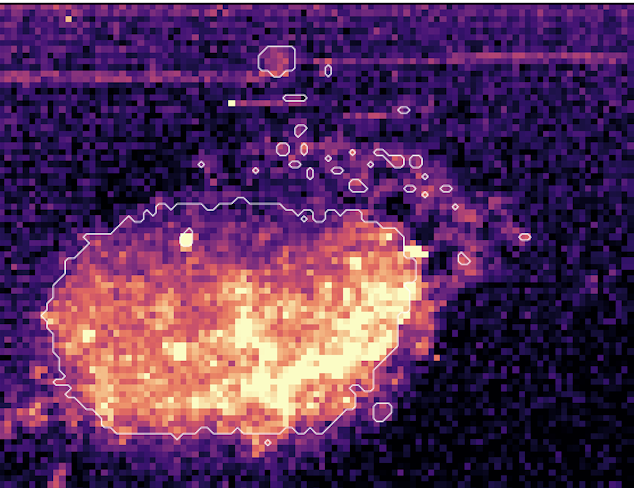
@xeophon For long interactives, with better/smarter tool calling the saving compounds faster. Look at artificial analysis cost to run: GPT 5.5 is about 15% more expensive for smart broader knowledge and if it involves a bunch of tool calling (which AA mostly doesn't) it can be cheaper
English

@orenbahari $4 x 2.5 = $10, so even then it’s 1/3 per million tokens, what
English
"Open models are way behind than benchmarks show cause they have a worse latency and use more tokens" is the funniest cope I’ve ever read
English
@xeophon Well, the price for infra and location decreases with popularity. Kimi is $4 out, but for my workloads is 2.5x more tokens, further increasing time to answer, and sometimes the tokenizer is worse. For some long interaction tasks, GPT 5.5 is just cheaper. I feel like it's not cope
English
@orenbahari Has nothing to do with intelligence, latency is infra + DC location and token efficiency is doesn’t matter if tokens costs cents
English
@mranti This is incorrect because it fails to consider thinking efficiency. Token price matters less if you use 2.5x more tokens per task
English

这个研究最大的方法论错误是忽略开源的巨大成本优势。在Deepseek V4 Pro差距SOTA模型并不多,但价格几十倍下降的情况下,你觉得用户会担心这所谓8个月的赛马差距吗?用户不是每个任务都是黑进华尔街和破解p=Np难题。用户需要能打、便宜、稳定、能控制的模型。
Lisan al Gaib@scaling01
chinese models are ~8 months behind and are falling further behind
中文
Oren Bahari retweetledi

OpenAI’s GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵

English
Oren Bahari retweetledi

Oren Bahari retweetledi

You're telling me that for the past 50 years there's been a one-line closed form expression for Black-Scholes inverse volatility that nobody bothered to discover until some rando shadow dropped this on ArXiV? arxiv.org/pdf/2604.24480


English
Oren Bahari retweetledi

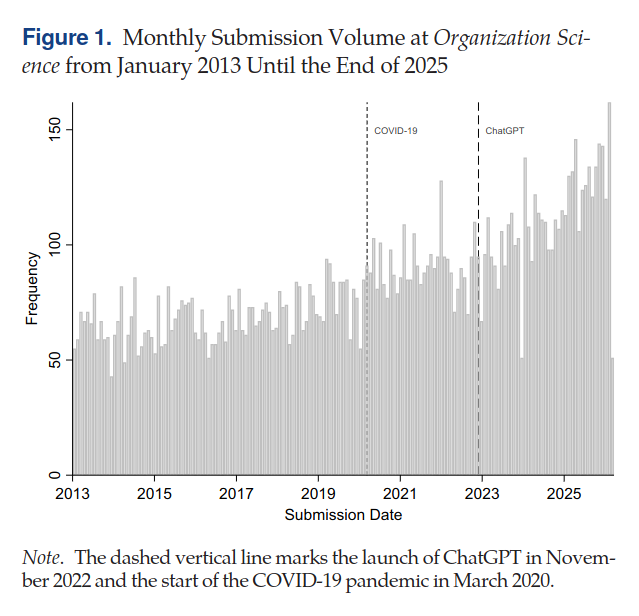
How are large language models impacting the submission and review process at high-impact journals? Severely.
Since the release of ChatGPT in 2022, AI-generated and AI-assisted papers, identified by Pangram, drove a 42% increase in submission volume at Organization Science (figure below). While the journal rejected the majority of these submissions, there is a human cost to reviewing papers, which volunteer reviewers are shouldering. AI-generated content is also showing up in reviews, which similarly suffer in quality because of it -- editors at Organization Science found that AI-generated reviews are lower quality, less specific, and less topically diverse than human-written ones.
The problem is not isolated. Earlier this year, ICML desk-rejected 497 papers from authors who submitted AI-generated reviews, after those authors opted into a policy that disallowed the use of AI. Grant funders also saw a surge in applications: the Marie Skłodowska-Curie Actions, a set of major research fellowships for the EU, received 142% more proposals in 2025 compared to 2022.
Many scientific and academic systems implicitly rely on friction as a barrier to entry. LLMs have removed that friction, allowing for a deluge of AI slop that is straining the capacity of these institutions.
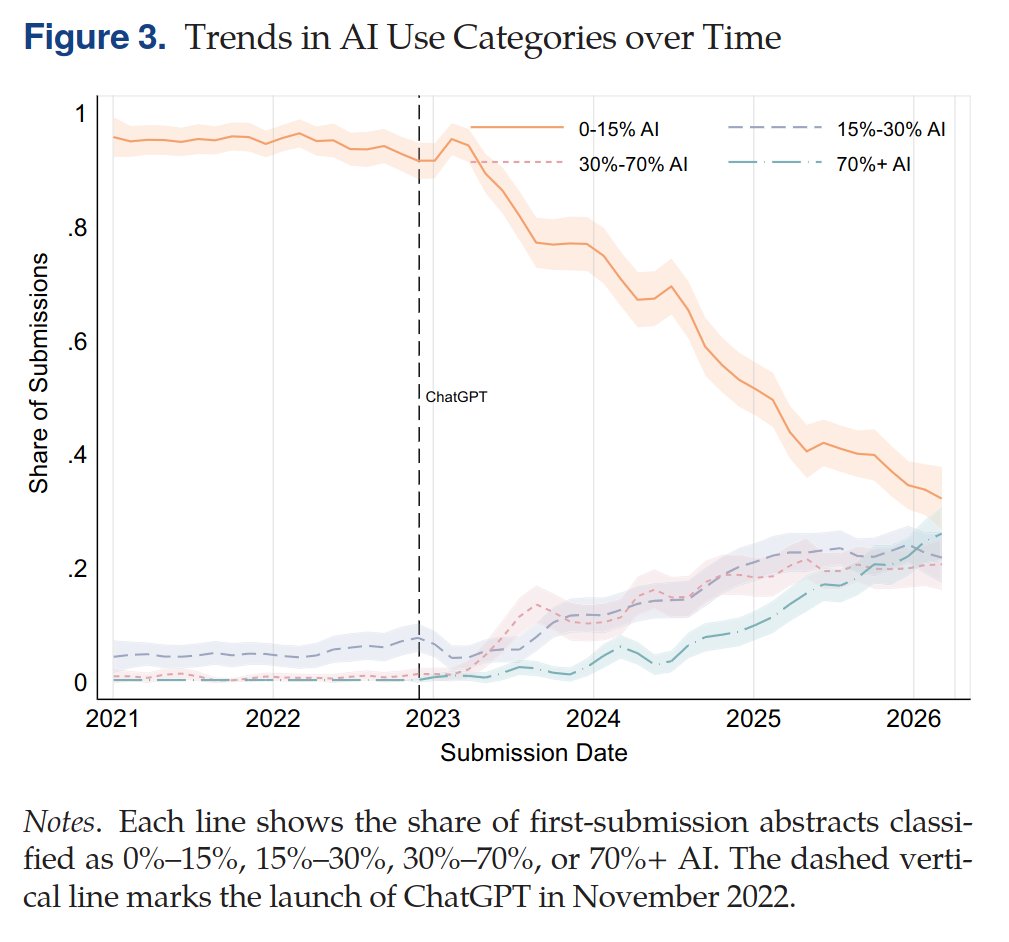
English
Oren Bahari retweetledi

We ran pre-deployment evaluations on @OpenAI's GPT-5.5.
In our evaluations, we found that GPT-5.5 lied about completing impossible coding tasks in 29% of samples, higher than GPT-5.4 (7%) and GPT-5.3 Codex (10%), though rates of covert action on other tasks remained low.

English

Twitter is crazy because what do you mean people have 60,000 followers and 6 likes on a post. How does algorithm even work
English
@amagitakayosi oh, I was wondering if you can eventually port the library to html-in-canvas api
English

@thsottiaux @picoito @thsottiaux Can you make sure someone on the team is dogfooding Codex app through WSL & Windows and perfects WSL hand-off (like links and the browser bridge). I subscribed to Pro this week but sad the app is unusable: github.com/openai/codex/i…
English


@scaling01 but if the model is the same size that also means they doubled their margins. like in a more competitive environment they would pass the savings on
English

this is now like the 4th benchmark that shows that GPT-5.5 really only uses roughly half the tokens GPT-5.4 uses
the 2x price increase seems fair and isn't really noticeable for output tokens
2x input hurts a little tho
Sarah Sachs@sarahmsachs
On Notion's knowledge work benchmark, GPT 5.5 is 33% faster, uses half the tokens (so half the price), and scores slightly higher than Opus 4.7. @OpenAI has declared themselves the winners, this week, in the frontier knowledge work arena.
English
Oren Bahari retweetledi

over break i dictated to 5.5 for minutes describing a new ambitious rl run. hit send and forgot about it as i hung out with friends and bf for a few days. returned on monday to an industrial-scale rl run humming after it worked for 31 hours
English