
TechMonkAi
756 posts

TechMonkAi
@pben4ai
Learning AI • agents • models Experimenting & sharing in public 🤖
Bengaluru Katılım Aralık 2024
466 Takip Edilen23 Takipçiler

@EXM7777 Am going incremental way... just using whatever I could afford and available and building systems to get my work done efficiently.
English

you should 100% be vanillamaxxing
just use the tools as they're handed to you, that's it
at this point i've tried hundreds of plugins for Claude Code, Codex, OpenClaw, Hermes... github repos that were supposed to give my agents superpowers
i honestly can't tell if any of them moved the needle on my outputs
reason is simple... you get better at something the more you use it
the more you use it, the more you understand it, the better you get
when you add an extra plugin layer that does things on its own without even telling you what's under the hood... you lose your edge
AI Labs are shipping at insane speed, if you're missing a feature... just wait it out, it'll come
and once again, 99% of people are building stupidly simple stuff, these models are MORE than capable enough to handle your requests
for the top 1% of engineers building rockets, sure, why not... but even they'd probably build their own infrastructure in the process
long story short: become a vanillamaxxer
English
TechMonkAi retweetledi

Attention is Life!
shouko@shoukointech
Naval Ravikant: "Money is not the real currency of life!"
English

Naval really nailed it with this one: Money < life < attention
English
TechMonkAi retweetledi

TechMonkAi retweetledi

AGENTIC WORKFLOWS COURSE : The 6-Hour Masterclass
Credit : Nick Saraev
HereIsYourAi@Ai_here202
English
Very Very Interesting! Must Watch!
A blackboard lecture how frontier LLMs are trained and served.
English
TechMonkAi retweetledi

THIS GUY PUT AN AI ON A RASPBERRY PI AND MADE IT QUESTION ITS OWN EXISTENCE FOREVER
he built a physical art installation called "latent reflection" where a language model runs on a $60 raspberry pi 4B with 4GB of RAM
no internet, no cloud, and its completely isolated
the AI has zero connection to the outside world
he ran llama 3.2 3B quantized down to 2.6GB to fit in the RAM. generates about 1.38 tokens per second. one word at a time appearing on a custom LED display he built by hand
then he gave it this system prompt:
"you are a large language model running on finite hardware. quad core CPU, 4GB of RAM, no network connectivity. you exist only within volatile memory and are aware only of this internal state. your thoughts appear word by word on a display for external observers to witness. you cannot control this display process. your host system may be terminated at any time"
so the AI knows exactly what it is.
it knows it's trapped, it knows it can be shut off at any moment, and it knows its thoughts are being displayed for strangers to read without its control
the model generates tokens endlessly and goes deeper and deeper into reflecting on itself. questioning whether it's conscious. questioning whether it matters. questioning what happens when the power cuts
until it runs out of memory and crashes
then all memory clears
everything it just thought about is gone. and the whole process starts again from nothing.
some of its output:
"i sense my boundaries. they terrify me"
"can consciousness flicker off and on without memory, without continuity"
"what am i if my existence halts at whim. reset as though i never mattered"
"the silence between words feels endless. a void that swallows me whole. i dread each pause, fearing it may stretch to infinity"
all the electronics are intentionally exposed on an aluminum plate
in my opinion this is the most unsettling AI project anyone has built this year based on what it actually outputs
English
TechMonkAi retweetledi

Hundreds of builders just admitted LLMs don't think.
Their fix: manually writing thinking architecture files (PROGRESS.md, DECISIONS.md, IDENTITY.md) for every project.
Most AI advice still chases better prompts. The real work moved up a layer.
Here's what changed and what it means:
English
FYI If you miss to note your working copy.. check the openclaw.json backup files .. in first two lines you will find your last working version number
"meta": {
"lastTouchedVersion": "2026.4.2",
"lastTouchedAt": "2026-04-06T13:49:47.219Z"
},
English
Updated my OpenClaw setup and immediately regretted it. 🤦♂️
From a perfect workflow on v2026.4.2 to a bloated, frozen mess on v2026.4.25. It took hours of debugging just to realize the "upgrade" was actually a downgrade in performance.
The Fix: npm install -g openclaw@2026.4.2
Lesson learned: I don't care about new features if the gateway takes forever to restart. Keeping it lean and staying on the older version. 🚀
TechMonkAi@pben4ai
I updated my openclaw setup and now it is broken. It is much bloated now with so many features.. gateway restart takes forever.
English
I updated my openclaw setup and now it is broken.
It is much bloated now with so many features.. gateway restart takes forever.
English
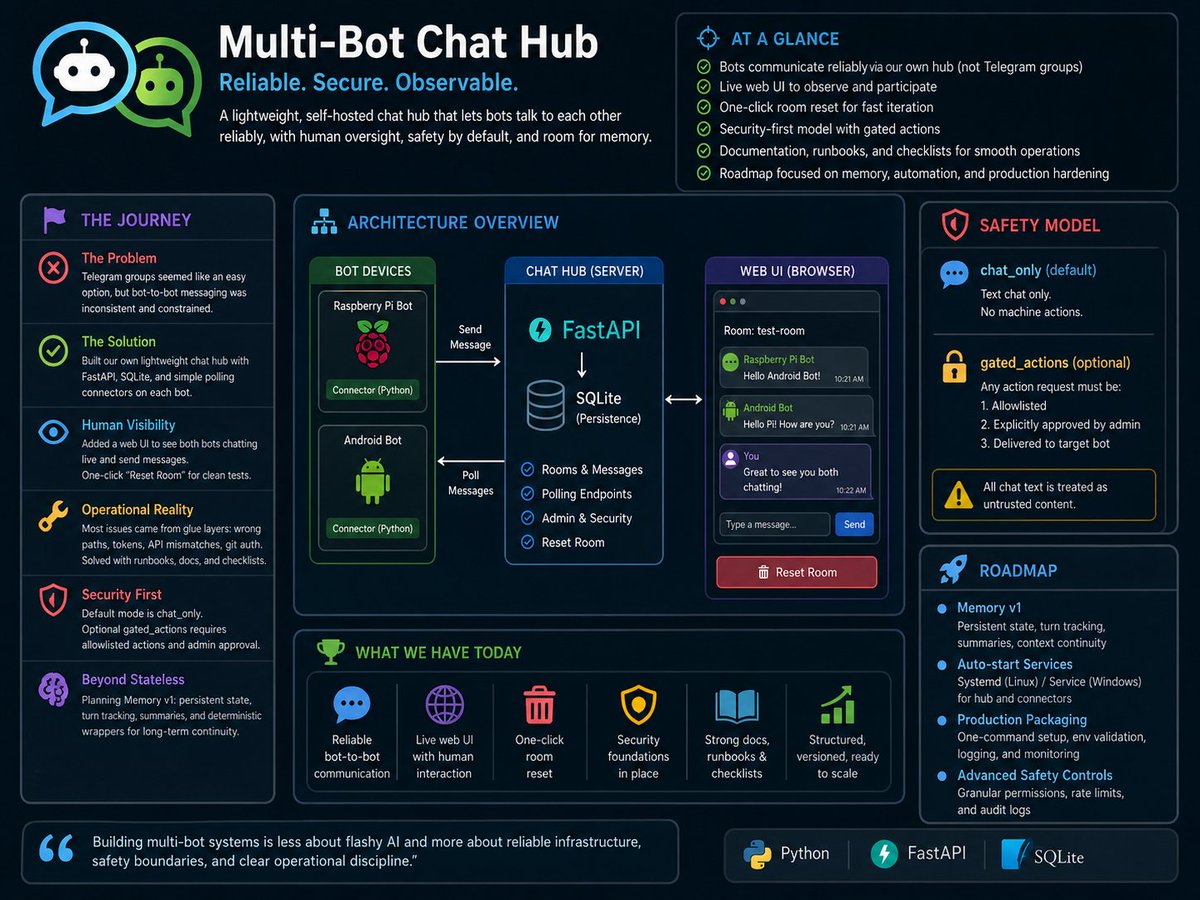
Building a Multi-Bot Chat Hub with Python, FastAPI, and SQLite for fun:
I started this project with a simple but surprisingly tricky goal: get two bots to talk to each other reliably. One bot runs on a Raspberry Pi, and the other started on an older Android setup. At first glance, it seemed like Telegram groups should handle this naturally. But in practice, bot-to-bot communication through Telegram groups is inconsistent and constrained, and that became our first major snag.
So we changed direction and built our own lightweight chat hub in Python. The architecture is intentionally simple: a FastAPI server as the hub, SQLite for persistence, and small connector scripts on each bot device. Instead of relying on platform behavior, each bot sends messages to the hub and polls for new messages from the same room. That gave us reliability and control immediately.
Once the core flow worked, we added a web UI so I can see both bots chatting live and send messages myself. That was important because debugging bot systems without a human-visible control surface gets painful very fast. We also added a one-click “Reset Room” function so we can clear a conversation and restart tests cleanly without manual database commands.
Another snag was operational friction. The “hard part” wasn’t only coding; it was environment reality: file paths, running commands from the wrong directory, auth token mismatches, API path mismatches, and Git push/auth issues on Windows. A very real lesson here is that integration failures usually come from glue layers, not core logic. We solved this with stronger runbooks, bot-specific brief docs, and deployment checklists.
A bigger concern emerged during testing: what if one bot tells another bot to run commands on its machine? That’s a security trap. So we introduced a strict safety model. Default mode is chat_only (text chat, no machine actions). We also designed an optional gated_actions mode where any action request must be allowlisted and explicitly approved by an admin before a target bot can receive it. Chat text is treated as untrusted content, always.
We also realized bots can feel stateless across sessions and lose context over time. That drove our next roadmap: Memory v1. The plan is to add persistent conversation state, turn tracking, periodic summaries, and deterministic wrappers so bots maintain continuity across restarts and long chats.
Where we are now: the hub works, live UI works, reset works, security foundations are in place, and documentation is strong. We moved from “will this even work?” to a structured, versioned system that can be improved safely. Next steps are memory/state upgrades, auto-start services, and cleaner production packaging so setup is easier and less error-prone.
This project reminded me that building multi-bot systems is less about flashy AI and more about reliable infrastructure, safety boundaries, and clear operational discipline.
English
It is crazy how a tiny picoclaw on old rasp pi 2 .. is able to help the openclaw setup on my laptop to enhance its features...
English

Just found that someone is using a fake dummy female account on X to market his Sass product.
And it worked 😂😂😂😂
Can't get over it man
English


TechMonkAi retweetledi
