Philip Court retweetledi

In-memory attention: Accelerating LLMs with analog hardware
Large language models (like GPT) generate text one word at a time. To decide the next word, they compare the new input with many past words stored in a short-term “cache.” On today’s GPUs, that cache has to be constantly moved back and forth between memories, and this shuttling costs far more time and energy than the math itself. A promising alternative is in-memory computing, where data are kept where the computation happens.
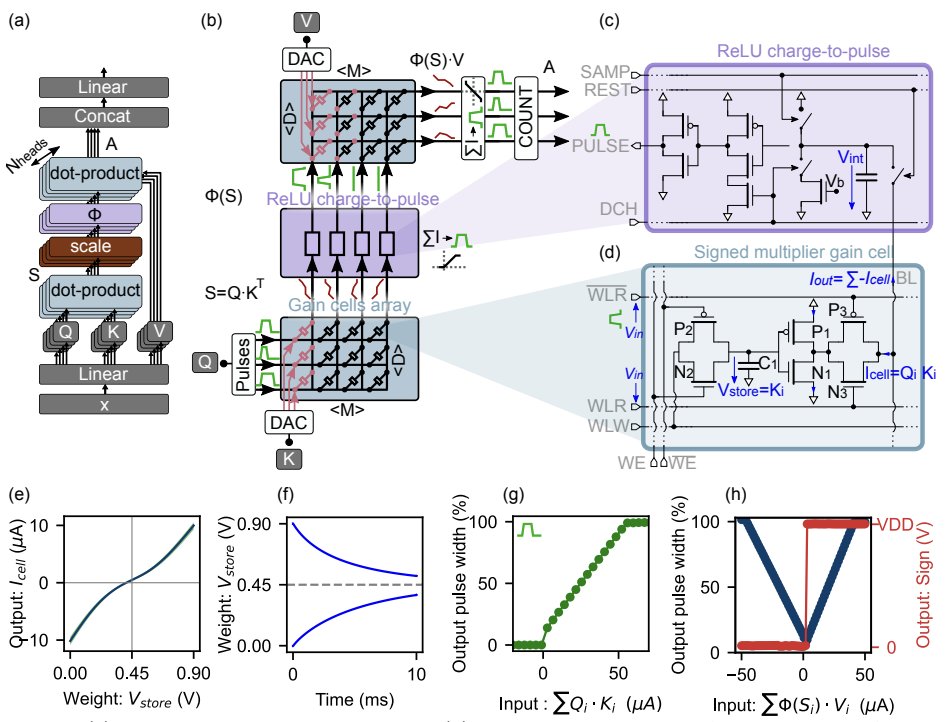
Nathan Leroux and coauthors present a custom in-memory computing design using gain cells—tiny analog memory devices that both store cached information and compute the dot-products for attention directly on-chip. They further combine this with charge-to-pulse circuits, avoiding power-hungry analog-to-digital converters. Importantly, they also propose a way to adapt pre-trained models (like GPT-2) to this non-standard hardware, showing equivalent performance without retraining from scratch.
The result is striking: up to 100× faster and 10,000× more energy-efficient attention compared with GPUs. While this study focuses on the attention block, the main bottleneck in transformers, the approach could integrate with other in-memory methods to accelerate all components.
This points toward a future where large generative models can run not only faster, but with vastly reduced energy use—critical for scaling AI sustainably.
Paper: nature.com/articles/s4358…
English