Pedro Nascimento retweetledi
Pedro Nascimento
326 posts

Pedro Nascimento
@pedromnasc
Founder @findlyai (YC S22). Prev engineering @X, @Google. Analytics, LLMs, Math, Decision Making, RecSys
Katılım Temmuz 2009
3.1K Takip Edilen593 Takipçiler

Pedro Nascimento retweetledi

this is actually insane
> be tech guy in australia
> adopt cancer riddled rescue dog, months to live
> not_going_to_give_you_up.mp4
> pay $3,000 to sequence her tumor DNA
> feed it to ChatGPT and AlphaFold
> zero background in biology
> identify mutated proteins, match them to drug targets
> design a custom mRNA cancer vaccine from scratch
> genomics professor is “gobsmacked” that some puppy lover did this on his own
> need ethics approval to administer it
> red tape takes longer than designing the vaccine
> 3 months, finally approved
> drive 10 hours to get rosie her first injection
> tumor halves
> coat gets glossy again
> dog is alive and happy
> professor: “if we can do this for a dog, why aren’t we rolling this out to humans?”
one man with a chatbot, and $3,000 just outperformed the entire pharmaceutical discovery pipeline.
we are going to cure so many diseases.
I dont think people realize how good things are going to get




Séb Krier@sebkrier
This is wild. theaustralian.com.au/business/techn…
English
Pedro Nascimento retweetledi

We are on the cusp of a profound change in the field of mathematics. Vibe proving is here.
Aristotle from @HarmonicMath just proved Erdos Problem #124 in @leanprover, all by itself. This problem has been open for nearly 30 years since conjectured in the paper “Complete sequences of sets of integer powers” in the journal Acta Arithmetica.
Boris Alexeev ran this problem using a beta version of Aristotle, recently updated to have stronger reasoning ability and a natural language interface.
Mathematical superintelligence is getting closer by the minute, and I’m confident it will change and dramatically accelerate progress in mathematics and all dependent fields.
English
@ajaxdavis great question 😀 a bit busy those days, but I will write it this year still!
English


Pedro Nascimento retweetledi

The only bitter lesson is that LLMs have succeeded beyond any expert expectations.
Underpinning LLMs is the idea of scaling, which is too often misunderstood as more parameters. Scaling is about using massive compute effectively to maximise the throughput of data ingestion into the learning process to obtain more capable models.
We are still far from hitting the limits in this. We are still compute hungry because there is a ton more we could achieve if only we had more compute, from experimental ablations to data acquisition and curation.
Scaling is largely about data and evals. The models are now trained on almost all the web and equally large (but growing) self generated synthetic data. sifting through such vasts quantities of data (the whole of the human creation) requires formidable engineering and intelligent ideas. This is what differentiates most models.
AI is finally in the hands of billions of users, and with it come billions of tasks - every reasonable user need. This scaling in tasks and evaluations is many orders of magnitude larger than pre-LLMs.
Having the right architecture matters, but we know several alternatives could all work well, eg replacing attention in Transformers for RNNs and interleaving such layers with local layers. What matters is fine ablations to maximise hardware usage. This is the realm of sophisticated high-precision engineering. It encompasses semiconductor design, datacenter design, distributed systems, MFU, etc. There is fascinating work on flow matching, JEPA, sparser MoEs, etc, that is all consistent with scaling.
I’m terrible at predictions, but in this we have stayed the course. There’s been pleasant surprises like the effectiveness of reasoning, which while allowing for less parameters, still demands even more compute.
Sparser multimodal MoEs also will allow for better continual learning. This is an old idea, eg arxiv.org/pdf/1108.3298, which is finally being done at scale.
Successful scaling is mostly about organising people into effective teams for research, development and production. They have to be teams of happy and ambitious people who put the team first. Yes, tech VCs and CEOs: work life balance matters to achieve prologued success, something I think @demishassabis did really well at @GoogleDeepMind and which I promote at @MicrosoftAI.
Bitter lesson: it really is all about scaling and hard work by thousands of amazing people. Hardly bitter, but hopeful and inspiring.
Richard Sutton@RichardSSutton
@GaryMarcus @ylecun @demishassabis You were never alone, Gary, though you were the first to bite the bullet, to fight the good fight, and to make the argument well, again and again, for the limitations of LLMs. I salute you for this good service!
English
@NandoDF 3 - Some sort of RAG. My concern with the other options would be overfitting the model and lose generalization on real use cases.
English
If you have 10K data instances, would you:
1. SFT an LLM with 10K data, or
2. Learn a reward with 5K, and RL the LLM on the remaining 5K with the learned reward
3. Other (explain)?
English
Pedro Nascimento retweetledi


English

@pedromnasc Not yet. I reached out months ago to someone at Google but got no reply. :(
But if a company wants to do an eval of their model on our problems, we'd be open :)
English
1/ OpenAI x AIMO eval at aimoprize.com:
We evaluated a version of o3, call it o3-preview, on 50 of our uncontaminated (!) fresh Olympiad-level math problems.
Results: o3-preview can solve 50/50 when counting top2-ranked answers. 😲
English
@emollick Another perspective is that builders were already able to start using and planning their system based on the new capabilities, which creates moat and feedback for openai
English

In retrospect it is surprising that OpenAI released o1-preview. As soon as they showed off reasoning, everyone copied it immediately.
And if they had held off releasing a reasoning/planning model until o3 (& called that GPT-5) it would have been a startling leap in AI abilities.
Noam Brown@polynoamial
@OpenAI o1 is trained with RL to “think” before responding via a private chain of thought. The longer it thinks, the better it does on reasoning tasks. This opens up a new dimension for scaling. We’re no longer bottlenecked by pretraining. We can now scale inference compute too.
English

I love doing this actually :). I think it's a pretty powerful eval too. Have all models generate something, then put it all together and give it back to all of them and ask them to rank all outputs. I thought models might have a bias to prefer their own outputs, but this doesn't seem to be too strong of an issue in my (limited) testing. I think it's the generator-discriminator gap on display. That is, it's really hard to write something good, but it's much easier to recognize something good, and the models seem to do it well.
English
I think congrats again to OpenAI for cooking with GPT-5 Pro. This is the third time I've struggled on something complex/gnarly for an hour on and off with CC, then 5 Pro goes off for 10 minutes and comes back with code that works out of the box. I had CC read the 5 Pro version and it wrote up 2 paragraphs admiring it (very wholesome). If you're not giving it your hardest problems you're probably missing out.
English
We use a lightweight library for templating and benchmarking prompt changes (created in-house). We treat prompt as code -> PR reviews, test / evals, quick rollbacks, etc, so standard source control is enough. A big advantage of keeping it simple is not having more dependencies that could introduce privacy and security concerns -> which is extra important when dealing with enterprise customers.
English

@pedromnasc How do you version your prompts ? Is source control enough?
English
Wrote a post on some lessons from building an AI data analyst: pedronasc.com/articles/lesso…
The gap from a nice demo to a real production system is big -> with a lot of yet to be solved challenges.
I hope it is useful for other builders creating their own generative business intelligence system.
English



I finally went to visit OpenAI's new building. It's the nicest office I've ever seen. So many different shaped spaces, and such good color. Whoever was in charge of this did a really good job.
English
@OpenAI @AnthropicAI the fact the models are trained on different distributions help to check for possible bias on the generation -> works both ways i.e. Claude generating, gpt5 reviewing
English
Using Codex with gpt-5 high to fix bugs and Claude Code to double check the PRs @OpenAI @AnthropicAI
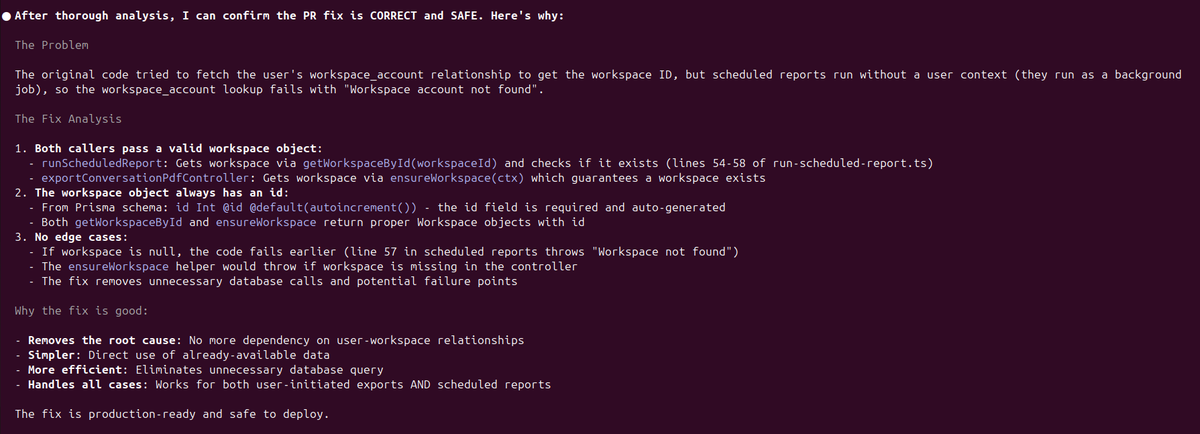
English
Pedro Nascimento retweetledi


I think we can still something about Superintelligent AI. Not sure about the other risk.
Igor Babuschkin@ibab
Two things pose an existential risk to humanity: Superintelligent AI and human stupidity; and I’m not so sure about the AI
English
@yudapearl @eliasbareinboim Curious about the results for reasoning models. They should learn better the causality from their CoT programs.
English

@eliasbareinboim What is your explanation why LLMs are doing so poorly on simple estimation of proportions? Is the input data corrupted?
English

In a recent work (causalai.net/r136.pdf), we examined whether LLMs are potential sources of probabilistic knowledge (rung 1 of Pearl's hierarchy), which led to the benchmark at llm-observatory.org. The answer was no, which was surprising and poses fundamental challenges for various downstream tasks and key capabilities (including explanation, decision-making, generalization, safety, and learning) given that inferences about interventions (rung 2) and counterfactuals (rung 3) build on rung-1 knowledge.
Many have asked me about the potential of LLMs over the past year or so. In short: they could become extraordinary repositories of knowledge, à la Internet or Wikipedia. But when it comes to the broader ambitions of AI, there’s still a good way to go; the interplay between language and causality remains largely unmapped and only rudimentarily understood.
I hope more young researchers will join the effort to tackle these generational challenges. Despite all the hype, we still need foundational principles for a better science of intelligence, one that integrates language, causality, and other essential components.
Judea Pearl@yudapearl
There is some confusion among readers of #Bookofwhy regarding the impressive "causal understanding" LLM's, which seems to defy the theoretical prediction of the Ladder of Causation. The Ladder predicts that, regardless of data size, no learning machine could correctly answer queries about interventions and counterfactuals unless supplemented with causal knowledge, external to the data. LLM programs circumvent this prediction by smuggling causal knowledge into the training data; instead of training themselves on observations obtained directly from the environment, they are trained on linguistic texts written by authors who already have causal models of the world. The programs can simply cite information from the text without attending to any of the underlying data. The result is a sequence of linguistic extrapolations which, in some remote and obscure sense, reflect the causal understanding of those authors. @GaryMarcus @eliasbareinboim @soboleffspaces @geoffreyhinton @DavidDeutschOxf
English
@dimireadsthings @paulg Even as a Brazilian who's seen plenty, the drug problem in SF still shocks me
English

@paulg Ι disagree. I live in London and the drug problem I saw in SF was truly shocking. I'd suspect your friends were warned to avoid some areas.
English
I asked some British friends visiting SF what surprised them about it. The drug problem is much less serious than they expected. Public transit works well. The streets are surprisingly empty. Great racial diversity. Every 4th car is a Tesla. Food is very expensive.
English