Sabitlenmiş Tweet

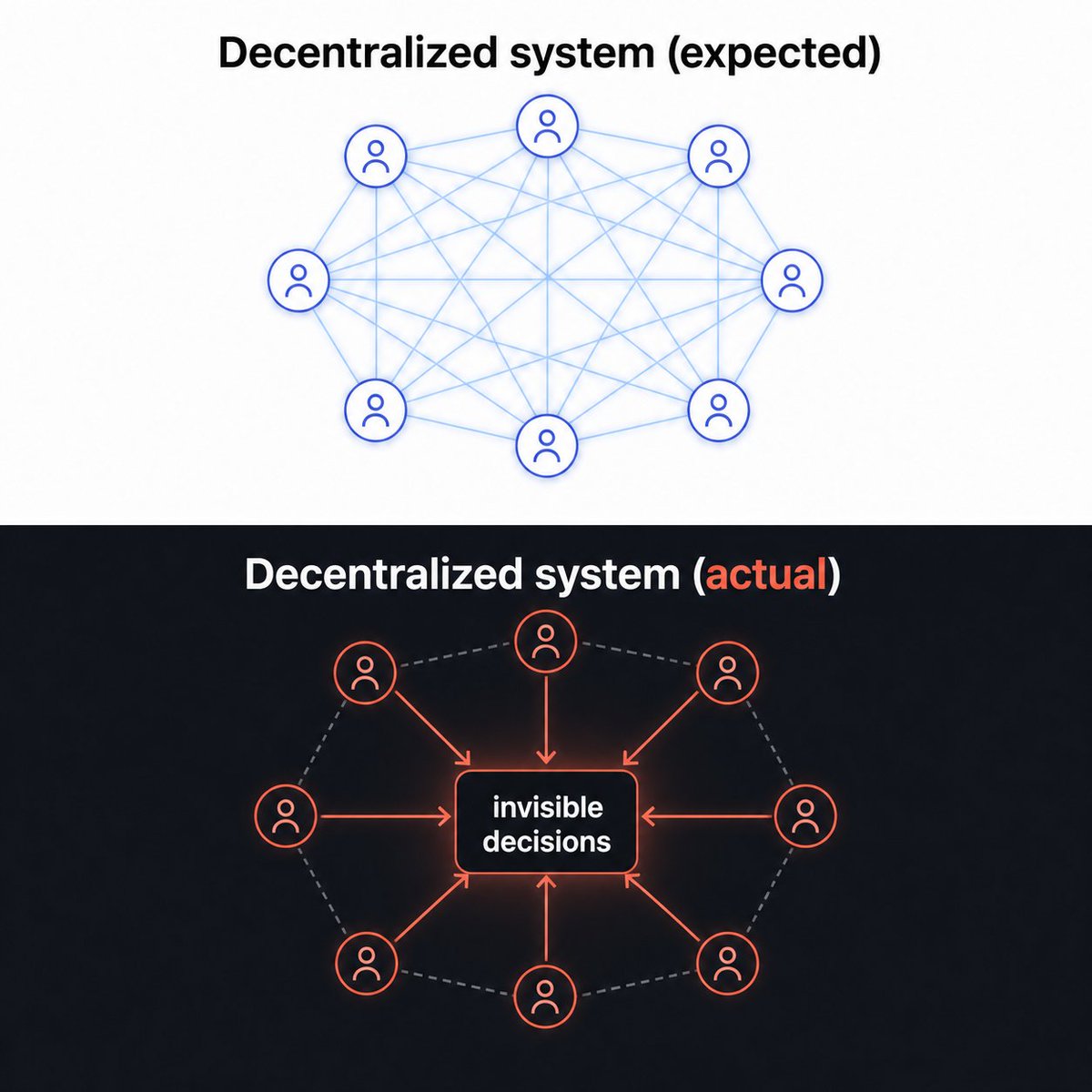
We just open-sourced the governance layer we use at @twynexyz to run collaborative AI agent workflows across our team.
If your devs are using Claude Code / Codex but sessions don't build on each other, knowledge evaporates, and onboarding is painful, this repo is for you. But allow me to explain what our governance layer does and why we built it. 🧵
github.com/pestopoppa/roo…
English