
This low latency for computer use is unreal. Beyond just Cerebras inference, a smaller model maybe? Layer pruning?
Ari Weinstein@AriX
This is the first time I've ever seen an LLM operate a GUI as fast as a person, and it's surreal.
English
Phani Srikanth
626 posts

@phanisrikanth33
❤️ @nimishasureka01. Principal Scientist & Director of Applied AI @NetApp. Prev @Microsoft. Views mine.
This is the first time I've ever seen an LLM operate a GUI as fast as a person, and it's surreal.




If you take a single, you eliminate the possibility of a regular time loss. So then it's a 50% chance to go to a super over, and a 50% chance that you win. And if it goes to a super over, then there is again a 50% chance you could win. So if you take a single there is 25% chance of losing after a super over and a 75% chance of winning either outright or after the super over. Now if you do not take the single, there is a 33.33% chance you win, 33.33% chance you go to a super over, and a 33% chance you lose. If you add the odds of the super over, it is a pure 50-50 chance. Granted, this does not bring the skill of the batter into the picture and that of the non-striker and their current form. But if you played the odds, the single was the most logical choice.
The Claude Mythos Preview system card is available here: anthropic.com/claude-mythos-…


this gets even better when you look at the y axis
What most people think happened: engineering got easier because AI agents can handle much of the coding. What actually happened: we are shipping a lot more, a lot faster, and engineers need to build robust systems to ensure nothing breaks. From what I'm seeing, engineering has become much more intense with AI, not less.
We estimate that Claude Opus 4.6 has a 50%-time-horizon of around 14.5 hours (95% CI of 6 hrs to 98 hrs) on software tasks. While this is the highest point estimate we’ve reported, this measurement is extremely noisy because our current task suite is nearly saturated.




what’s the highest you guys got to on the divergent vocabulary test
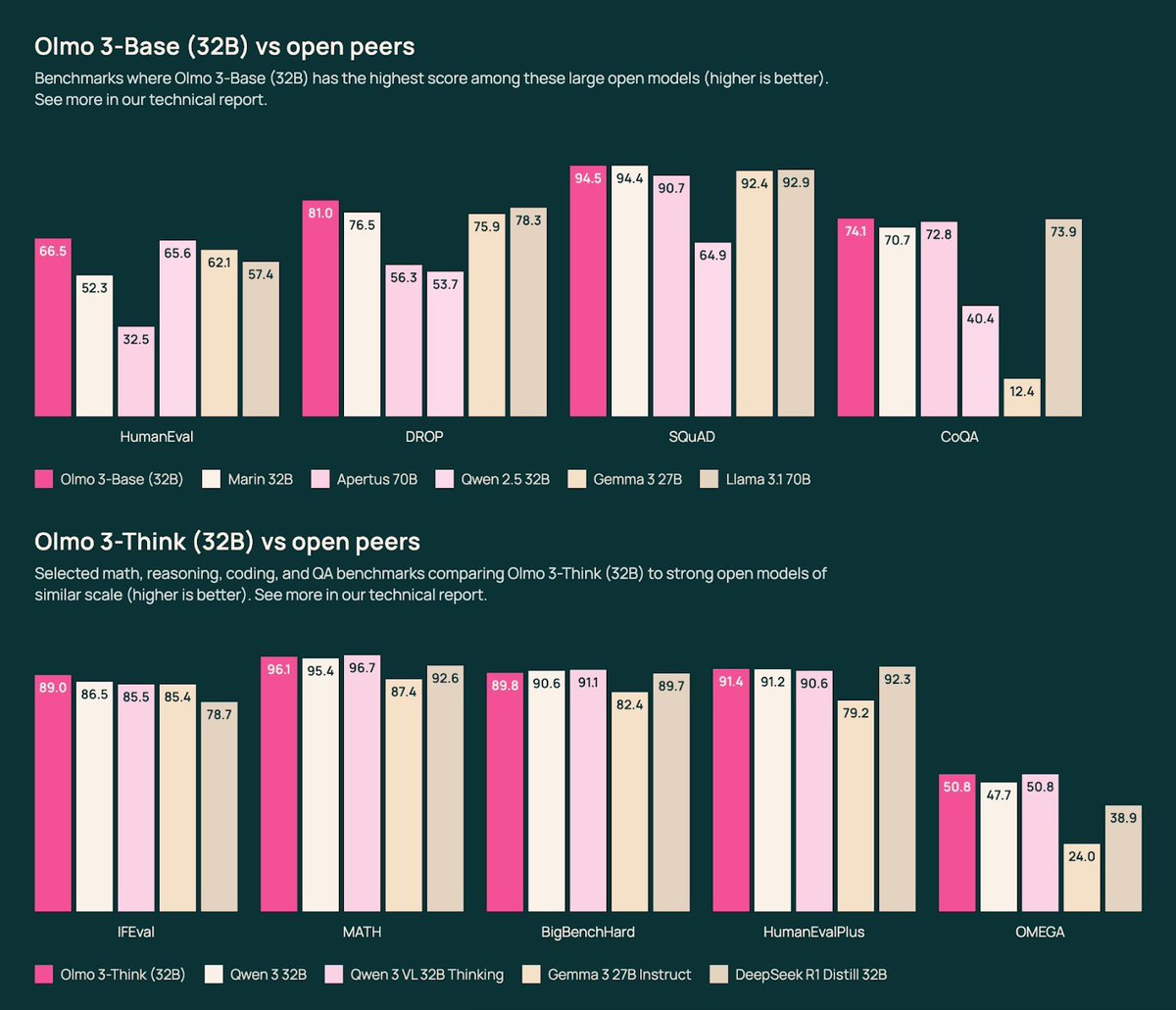
With fresh support of $75M from @NSF and $77M from @NVIDIA, we’re set to scale our open model ecosystem, bolster the infrastructure behind it, and fast‑track reproducible AI research to unlock the next wave of scientific discovery. 💡