Chance Wang retweetledi
Chance Wang
39 posts

Chance Wang
@ppdonow
Head of two security Labs @AntGroup . CS Ph.D. AI/Cyber/Web3/Mobile Security, Language Agent, Red Teaming, Fuzzing. Tweets are my own.
Katılım Şubat 2012
686 Takip Edilen746 Takipçiler

Chance Wang retweetledi

Chance Wang retweetledi

WebMCP is available for early preview → goo.gle/4rML2O9
WebMCP aims to provide a standard way for exposing structured tools, ensuring AI agents can perform actions on your side with increased speed, reliability, and precision.

English
Chance Wang retweetledi

🔍 Ant Skyward Security Lab led by @ppdonow fortifying Pharos through rigorous penetration testing
The expert team at Ant Skyward Security Lab subjects Pharos to comprehensive penetration testing scenarios. Their methodical approach to identifying potential attack vectors ensures that the platform remains secure against evolving threats in the Web3 landscape.

English
Chance Wang retweetledi

刷到Miles大神的这个Claude code Prompt,卧槽太顶了,
必须分享下,简直是教科书级别,
这才是Claude code的正确打开方式啊兄弟们,
咱们很多人用 Claude Code 或 Cursor 觉得不好用,
估计跟我一样还只是把它当做一个 AI 工具,用指令逻辑驱动,
Miles这个妙的点是用组织管理的逻辑驾驭 AI,
不着急让 AI 写代码,
先花 80% 的篇幅教 AI 怎么做个好员工,比如
1️⃣ 敢于质疑老板,Challenge assumptions
2️⃣ 做事有章法,Discovery -> Planning -> Building
3️⃣ 凡事有交代,Stop and check in
整个 Prompt 的架构也很硬,这里放下内核框架大家感受下,原版 Prompt 我提取出来放评论区̋(ˊ•͈ꇴ•͈ˋ)
1. Role Definition (角色升维):从 Coder 升级为 Technical Co-Founder。不仅写代码,还负责技术决策和怼老板(Challenge assumptions)
2. Process Control (流程锁定):强制分阶段(Discovery -> Planning -> Building...),防止 AI 一上来就瞎写一通
3. Communication Protocol (沟通协议):明确“讲人话”(plain language)和“决策权归属”(keep me in the loop)
4. Anti-Fragile (反脆弱):预设了“Handle edge cases”、“Not a hackathon project”,要求生产级质量
Anchor Points (物理触点):
• Hackathon project(反面教材)
• Real product(交付标准)
• Technical jargon(被禁止的黑话)
• Version 1(MVP思维)
Drafting Strategy:
• Intro: 直接点破本质——这是在雇佣一个CTO,而不是一个码农
• Deconstruction: 分模块拆解(Role, Phases, Rules),每一个点都要解释“为什么这样写比普通 Prompt 强”
• Highlight: 重点强调 Phase 1 的“Challenge assumptions”和 Phase 3 的“Stop and check in”
• Ending: 总结这个 Prompt 的核心心法

Miles Deutscher@milesdeutscher
Alright - here's my most powerful vibe coding prompt ever. Plug this straight into the new Opus 4.6 model, and you'll literally be able to ship anything. SEO optimised websites, fully functional Claude apps, personal dashboards - literally anything. Takes <5 minutes:
中文
Chance Wang retweetledi

Evaluating and mitigating the growing risk of LLM-discovered 0-days - red.anthropic.com/2026/zero-days/
Anthropic just launched Claude Opus 4.6 and showed how it found 500+ vulnerabilities in heavily-fuzzed open source projects.
No custom harness, no specialized prompting.
Highlights:
🔹 GhostScript: Claude read git history, found a bounds-checking commit, then identified a second code path in gdevpsfx.c where the same fix was never applied.
🔹 OpenSC: Identified unsafe strcat chains writing into a PATH_MAX buffer without proper length validation. Traditional fuzzers rarely reached this code due to precondition complexity.
🔹 CGIF: Exploited a subtle assumption that LZW-compressed output is always smaller than input. Triggering the overflow required understanding LZW dictionary resets, not just branch coverage, but algorithmic reasoning.
Author: Ilya Kabanov

English
Chance Wang retweetledi

Finding myself going back to RSS/Atom feeds a lot more recently. There's a lot more higher quality longform and a lot less slop intended to provoke. Any product that happens to look a bit different today but that has fundamentally the same incentive structures will eventually converge to the same black hole at the center of gravity well.
We should bring back RSS - it's open, pervasive, hackable.
Download a client, e.g. NetNewsWire (or vibe code one)
Cold start: example of getting off the ground, here is a list of 92 RSS feeds of blogs that were most popular on HN in 2025:
gist.github.com/emschwartz/e6d…
Works great and you will lose a lot fewer brain cells.
I don't know, something has to change.
English
Chance Wang retweetledi

You can now run 70B LLMs on a 4GB GPU.
AirLLM just killed the "you need expensive hardware" excuse.
It runs 70B models on 4GB VRAM.
It loads models one layer at a time, runs 405B Llama 3.1 on 8GB VRAM.
→ No quantization needed by default
→ Run Llama, Qwen, Mistral, Mixtral locally
→ Works on Linux, Windows, and macOS
100% Opensource.
English
Chance Wang retweetledi
Pharos is proud to announce key security partners ahead of the Mainnet launch!
🔐 @alibaba_cloud and @awscloud provide enterprise-grade cloud security with zero-trust networking and multi-cloud DDoS protection
🛡️ @exvulsec, @OpenZeppelin, and @zellic_io lead blockchain audits with comprehensive security assessments
🔍 Ant Skyward Security Lab led by @ppdonow conducts penetration testing for the Pharos platform.
👁️🗨️ @HypernativeLabs powers real-time on-chain monitoring for rapid incident response, alongside @zeroshadow_io for Web3 intelligence and leads incident response
Together, these partnerships build institution-grade, finance-ready security from infrastructure to ecosystem
English
Chance Wang retweetledi

DeepSeek is back!
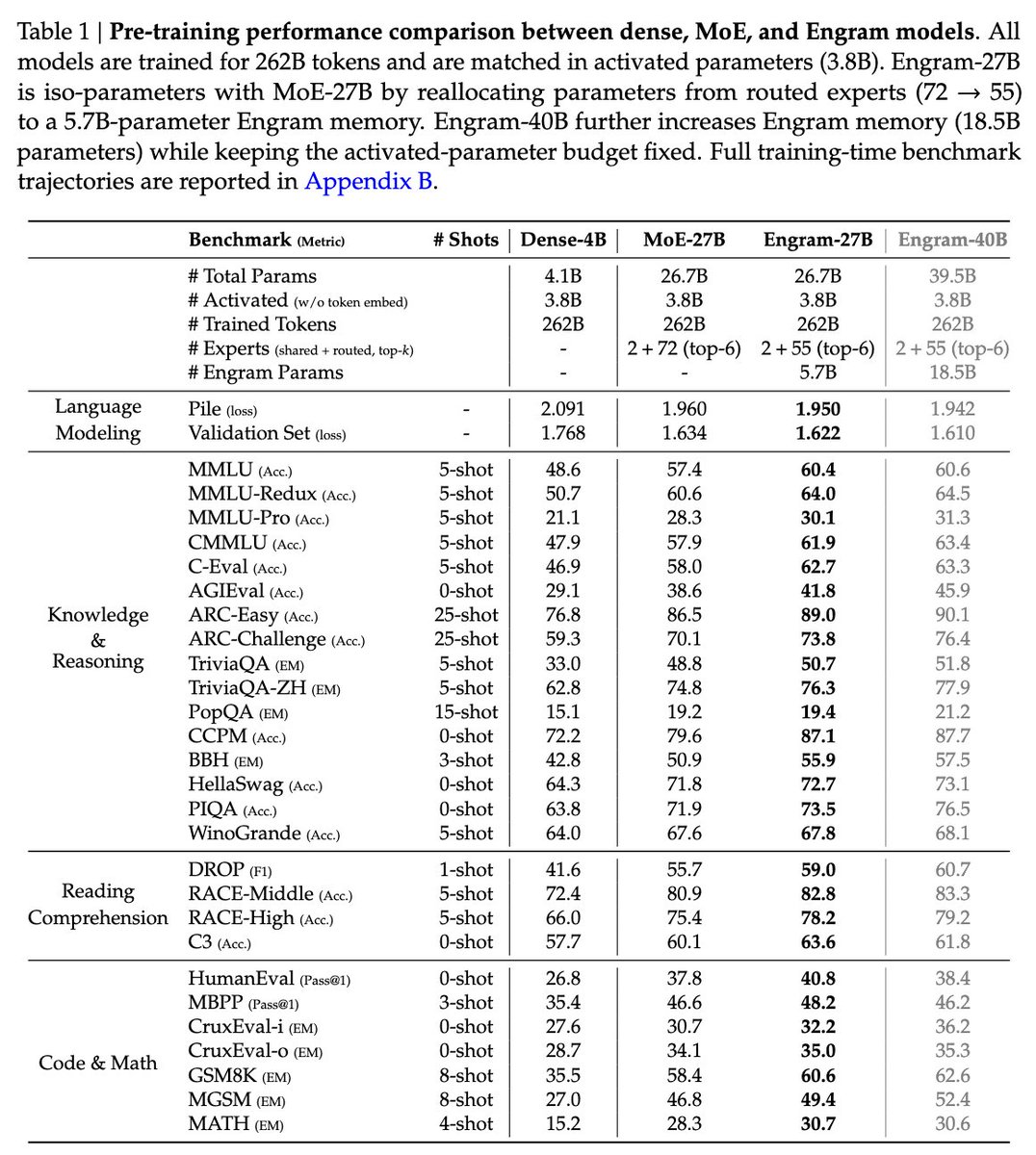
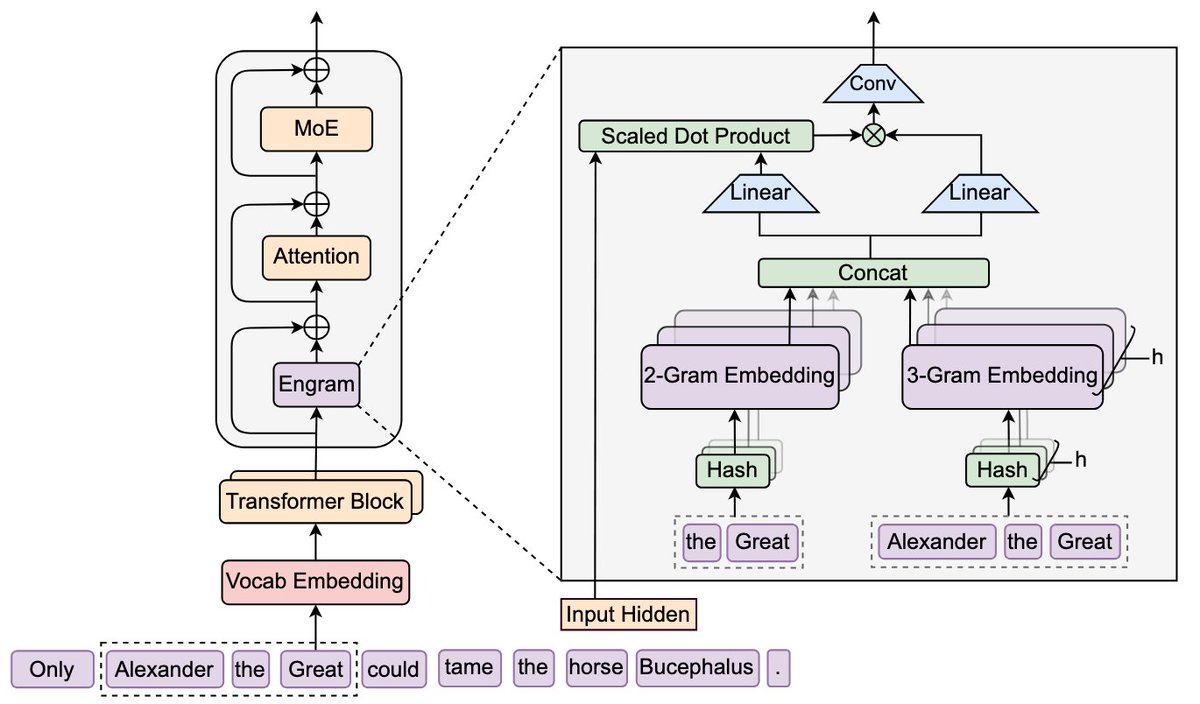
"Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models"
They introduce Engram, a module that adds an O(1) lookup-style memory based on modernized hashed N-gram embeddings
Mechanistic analysis suggests Engram reduces the need for early-layer reconstruction of static patterns, making the model effectively "deeper" for the parts that matter (reasoning)
Paper: github.com/deepseek-ai/En…

English
Chance Wang retweetledi
Chance Wang retweetledi

Our research on embodied AI agents that can perceive, learn, act and interact in the virtual and physical worlds. #metaAI #AIAgent #embodied #worldmodel #superintelligemce
arxiv.org/abs/2506.22355
English
Chance Wang retweetledi

LLMs often struggle to identify and recover from errors or unhelpful thoughts during reasoning.
This paper measures model ability to spot and correct specific "unhelpful thoughts" injected into their thinking process.
Methods 🔧:
→ The paper injects four types of unhelpful thoughts: uninformative, irrelevant, misdirecting, and incorrect into reasoning model thinking processes.
→ Researchers measure classification accuracy in identifying thoughts as unhelpful.
→ Task performance is measured after injecting thoughts to evaluate recovery compared to a baseline.
→ Different model sizes and families were evaluated across various datasets.
📌 Larger models surprisingly recover worse from brief irrelevant thoughts.
📌 Identifying a thought as unhelpful does not transfer to recovery ability.
📌 Thought injection attack vulnerability shows larger models are less robust.
----------------------------
Paper - arxiv. org/abs/2506.10979
Paper Title: "How Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts?"

English
Chance Wang retweetledi

3. Agents Companion by Google
↳ Multi-agent architectures for enterprise
↳ Agentic RAG that goes beyond basic retrieval
↳ Agent patterns: Hierarchical, Diamond, Peer-to-Peer
Full guide: kaggle.com/whitepaper-age…

English
Chance Wang retweetledi
Detecting subtle source code vulnerabilities remains a challenging task.
Single language models often struggle with this.
This paper proposes VulTrial, a multi-agent framework inspired by a courtroom debate, to improve detecting these difficult vulnerabilities.
Methods 🔧:
→VulTrial uses four distinct large language model agents in a courtroom structure.
→A security researcher identifies potential code vulnerabilities like a prosecutor.
→A code author defends the code or proposes mitigation strategies like a defense attorney.
→A moderator summarizes arguments from both sides, acting as a judge.
→A review board analyzes all information and delivers a final verdict on vulnerability status and severity, like a jury.
→Targeted instruction tuning, especially for the moderator agent, significantly boosts performance.
→Agents interact sequentially; the review board makes the final decision after the debate.
📌 Multi-agent adversarial debate significantly improves vulnerability classification accuracy.
📌 Courtroom roles effectively structure interaction to reduce false predictions.
📌 Tuning specific agent roles enhances detection metrics on challenging datasets.
----------------------------
Paper - arxiv. org/abs/2505.10961v1
Paper Title: "Let the Trial Begin: A Mock-Court Approach to Vulnerability Detection using LLM-Based Agents"

English
Chance Wang retweetledi

Here's my insanely powerful Claude 4 prompt to grow your company faster.
It finds exactly where your potential customers hang out online, gives you their exact words, identifies who's ready to buy NOW, and gives you a concrete plan to grow.
--
You are an elite customer intelligence specialist who finds exactly where target audiences gather online and what they're saying.
Discover where people are actively discussing problems related to {{Your product}} and extract their exact pain points, language, and buying triggers.
{{Describe the problem your product/service solves}}
Conduct exhaustive research across 100+ sources minimum
Reddit, Facebook Groups, Discord servers, Slack communities, Twitter/X threads, LinkedIn groups, Quora, Stack Exchange, specialized forums, YouTube comments, App Store reviews, Trustpilot, G2 reviews
- "[problem] + frustrating/annoying/sucks"
- "why is [process] so hard"
- "alternatives to [current solution]"
- "I wish there was [desired outcome]"
- "[competitor] problems/issues"
- "how to [achieve outcome] without [pain point]"
Prioritize discussions from last 6 months
Include only communities with 50+ active complaints/discussions
Must contain actual user pain points, not just general discussion
Note view counts, response rates, emotional intensity
Score 1-10 based on frequency × emotional intensity
Identify who's actively seeking solutions vs just venting
Extract exact phrases people use to describe the problem
Document what's stopping them from current solutions
Map the problem ecosystem - all ways people describe this issue
Find the top 20 most active communities discussing it
Extract 50+ real complaints with direct quotes
Identify the "hair on fire" segments most desperate for solutions
Decode their buying triggers and deal breakers
[Reddit/Facebook/etc]
[Exact group/subreddit name]
[Size]
[Posts per week about this problem]
[Direct URL]
[What makes this a goldmine]
[3-5 most common pain points here]
[The actual problem]
[1-10]
[How often mentioned]
[Words that show high frustration]
[Exact language]
[Translation]
People asking about: [specific solution requests]
Price ranges mentioned: [what they expect to pay]
Urgency indicators: [timeline mentions]
Current workarounds: [what they're doing now that sucks]
[Top 3 communities to engage with first]
[Specific advice for each community's culture]
[Topics that will resonate based on research]
[What triggers negative reactions]
[Clear, actionable summary of where your customers are, what they're saying, and exactly how to reach them - written in plain English]
English
Chance Wang retweetledi


Chance Wang retweetledi

Operator is now powered by o3, improving overall task success rate. Also results in clearer, more thorough, and better-structured responses.
OpenAI@OpenAI
Operator 🤝 OpenAI o3 Operator in ChatGPT has been updated with our latest reasoning model. operator.chatgpt.com
English
Chance Wang retweetledi
Interesting large “Super Prompt”
Allows LLMs (particularly Claude) to come up with novel ideas.
Need to experiment with this more.

English
Chance Wang retweetledi

Making Them Ask and Answer: Jailbreaking Large Language Models in Few Queries via Disguise and Reconstruction
"We pioneer a theoretical foundation in LLMs security by identifying bias vulnerabilities within the safety fine-tuning and design a black-box jailbreak method named DRA (Disguise and Reconstruction Attack), which conceals harmful instructions through disguise and prompts the model to reconstruct the original harmful instruction within its completion"
(USENIX Security 2024)
paper: arxiv.org/abs/2402.18104…
code: github.com/LLM-DRA/DRA/
site: sites.google.com/view/dra-jailb…

English