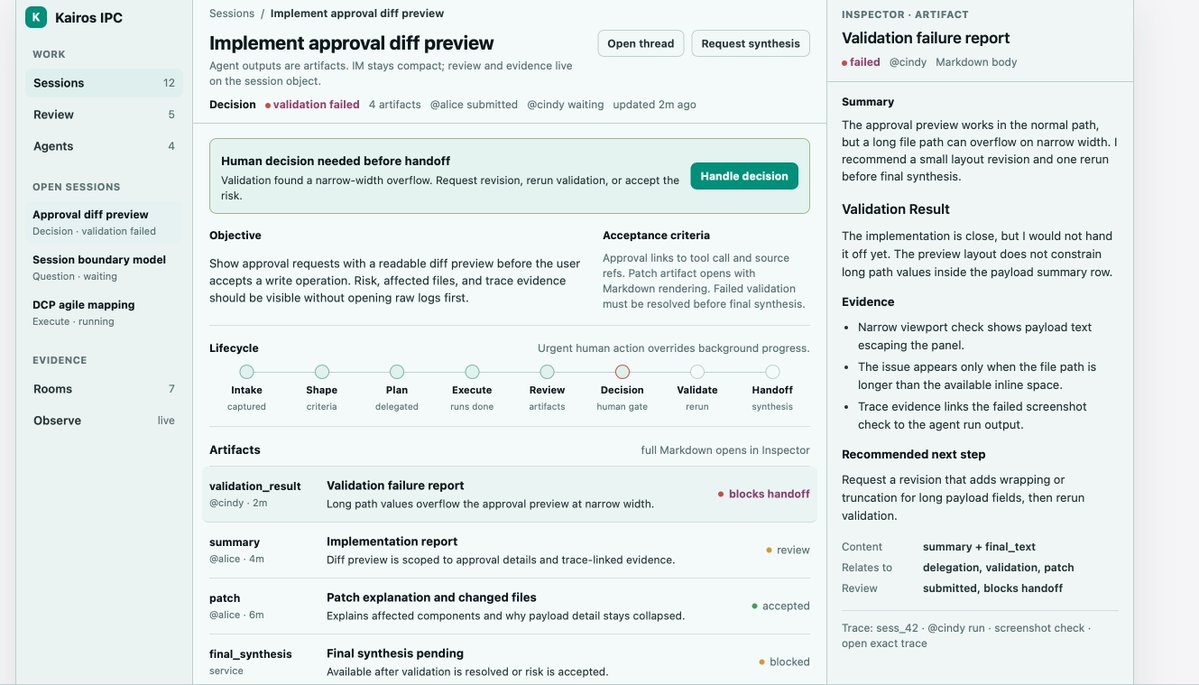
Sabitlenmiş Tweet
Paulchan
178 posts


Paulchan
@punk2sang
🤖 @TencentGlobal @AlibabaGroup developer
shenzhen Katılım Temmuz 2018
434 Takip Edilen56 Takipçiler






auth.json 中的以下两项改为
"auth_mode": "chatgpt",
"OPENAI_API_KEY": null,
其余不变。
config.toml 新增
model_provider = "OpenAI"
[model_providers.OpenAI]
name = "OpenAI"
base_url = "xxx"
wire_api = "responses"
experimental_bearer_token = "sk-xxx"
requires_openai_auth = true


𝗦𝘁𝗲𝘃𝗲 𝕏@st7evechou
用上了,第三方的中转站 API 跑通 Codex 手机端。
English

Codex 官方出了移动端,但 @lody_ai 从第一天就是已经假设了官方一定会出。
我们给 Lody 的定位从来不是一个远端控制器,我们想要解决的是团队软件开发流程中的
- Context 管理问题
- 多人和多 Agent 协作问题
- 数据所有权和隐私问题
只不过我们将 coding 和移动端访问作为了起点。
我们在几年前开始创业构建了 @loro_dev ,正在慢慢成长为 local-first 的基础设施。我始终相信的不是人们不在乎自己的隐私,而是没有更好的产品提供这样的能力,大家没有选择而已。
如果你有一个团队,你在经营着自己的应用,想让 Agent 参与到整个协作流程中提高效率的话。我希望你可以和我聊聊你的现状,帮助我们构建更好的 Lody,我们也会给到最实际的优惠。

中文







看到这个3D交互网站的演示给我看傻了😲🤯
做了版高可复用3D互动网站 Prompt 框架提示词大家收好!!!
讲真不是因为这个网站有多炫酷,主要是让我突然意识到,以前做3D网站这个曾经门槛极高的活,现在真的连奶奶都能做了🤣👵
不用Cursor或者Claude写Three.js那么复杂,
是用Emergent加Claude的Agent全流程托管,
你不用写一行代码,不用搭环境,不用调渲染参数,
只要上传一段参考视频,说清楚你想要的感觉,
AI会自己生成代码,自己跑实时预览,自己迭代调整,
整个流程从打开网站到做出能跑的3D交互原型,只用了一个下午,
成本就是一个月20刀的Claude订阅,
以前这种级别的3D交互原型,外包报价至少8000到15000美元,
现在一个人一个下午就能搞定了😱
老规矩提示词自取👇
中文

这个也太屌了!
这个中国开发者在飞机上用 MacBook 本地跑 Llama 70B,整整 11 小时没有网络,处理了完整的客户项目。
他坐在跨大西洋航班的靠窗位置,设备是 MacBook Pro M4,64GB 内存。机上 WiFi 要价 25 美元,他拒绝了。
没有云端 API,没有连接 Anthropic 或 OpenAI 的服务器,完全没有互联网。
只有一台本地运行的 Llama 3.3 70B(bf16)和他自己写的编排脚本。
模型通过 llama.cpp 运行。生成速度 71 tokens/秒,上下文约 60,000 tokens,内存占用 48.6 GiB / 64 GiB,起飞时电池剩余 3 小时 21 分钟。
起飞前他给编排器写了这样的系统提示:
"你是一个运行在单台 MacBook 上的离线编排器。没有网络。你唯一的资源是 /Users/dev/work 下的本地文件、localhost:8080 的 Llama 70B 推理服务,以及 3 小时 21 分钟的电池预算。处理 /Users/dev/work/queue.jsonl 中的任务队列(每行一个客户任务)。对每个任务:起草 → 运行本地评估 → 保存产物到 /Users/dev/work/done/。每 12 个任务保存一次上下文检查点,以便更换电池后恢复。仅在队列为空或电池低于 5% 时停止。"
所以这个系统完全清楚自己运行在什么资源上。
它知道自己未来 11 小时没有外部连接。它知道自己的内存和电池都是有限的。它知道在飞机降落之前不会有人类介入。
系统跑在一个循环里。从队列取任务,推理,保存产物,写检查点。一个接一个。
当电池低于 5% 时,编排器自动暂停,等待笔记本切换到备用充电宝,然后从最后一个检查点恢复。
这是系统在飞行中的日志:
"saved context checkpoint 8 of 12 (pos_min = 488, pos_max = 50118, size = 62.813 MiB)"
"restored context checkpoint (pos_min = 488, pos_max = 50118)"
"prompt processing progress: n_tokens = 50 / 60818"
"task 37016 done | tps = 71 s tokens text → /Users/dev/work/done/proposal_westside.md"
窗外是云层、蓝天,没有 WiFi。托盘上是一台 MacBook,一个打开的终端,两个屏幕,一个 localhost 推理服务。
这是过去一年里我见过的最漂亮的离线 AI 工作流:
11 小时飞行,WiFi 费用 0 美元,所有客户队列在降落前全部清空。
这个故事的核心不是技术多牛(llama.cpp 跑 70B 现在很常规),而是一个完整的离线自主工作流,编排器理解自己的资源约束,自动管理电池和检查点,没人干预干了 11 小时。
这种"self-aware computing"的感觉确实挺酷的!
x.com/i/status/20499…
Blaze@browomo
This Chinese developer launched Llama 70B locally on a MacBook on a plane and for a full 11 hours without internet ran client projects. He was sitting by the window on a transatlantic flight with a MacBook Pro M4 with 64 GB of memory. WiFi on board cost $25 for the flight. He declined. No cloud API, no connection to Anthropic or OpenAI servers, no internet at all. Just a local Llama 3.3 70B on bf16 and his own orchestrator script. The model runs through llama.cpp. Generation speed, 71 tokens per second. Context around 60,000 tokens. Memory usage, 48.6 GiB out of 64. Battery at takeoff, 3 hours 21 minutes. And he gave the orchestrator this system prompt before takeoff: "You are an offline orchestrator running on a single MacBook. There is no network. The only resources you have are local files in /Users/dev/work, the Llama 70B inference server at localhost:8080, and a battery budget of 3 hours 21 minutes. Process the queue at /Users/dev/work/queue.jsonl (one client task per line). For each task: draft → run local evals → save artefact to /Users/dev/work/done/. Save context checkpoints every 12 tasks so you can resume after a battery swap. Stop only on empty queue or when battery drops below 5%." So the system knows exactly what resources it is running on. It knows it has no connection to the outside world for the next 11 hours. It knows it has finite memory and a finite battery. It knows the human will not intervene until the plane lands. The system runs in 1 loop. Takes a task from the queue, runs it through inference, saves the artifact, writes a checkpoint. Task after task, just like that. And only when the battery drops below 5% does the orchestrator automatically pause, waits for the laptop to switch to the backup power bank, and continues from the last checkpoint. Here is what the system actually writes in his log during the flight: "saved context checkpoint 8 of 12 (pos_min = 488, pos_max = 50118, size = 62.813 MiB)" "restored context checkpoint (pos_min = 488, pos_max = 50118)" "prompt processing progress: n_tokens = 50 / 60 818" "task 37016 done | tps = 71 s tokens text → /Users/dev/work/done/proposal_westside.md" Outside the window, clouds, blue sky, and no WiFi. On the tray, 1 MacBook, an open terminal on 2 screens, and an inference server on localhost. From what I have observed, this is the cleanest offline AI workflow I have seen in the past year: 11 hours of flight, $0 for WiFi, and the entire client queue closed before landing.
中文




OpenAI 发了一篇技术博客,认真调查了一个荒诞的问题:为什么他们的模型越来越爱说“哥布林”(goblin)和“小精灵”(gremlin)?
事情最早在去年 11 月 GPT-5.1 上线后被注意到。用户反馈模型说话太过自来熟,内部一查,发现包含“goblin”的对话比之前暴涨了 175%,“gremlin”涨了 52%。当时觉得比例还小,没太当回事。
几个月后 GPT-5.4 上线,哥布林彻底泛滥,用户和员工都受不了了。OpenAI 这才认真追查,最终锁定了罪魁祸首:ChatGPT 的性格定制功能。
ChatGPT 有八种可选性格,其中一种叫“Nerdy”(极客风)。训练这个性格时,奖励模型被设定为鼓励"俏皮、有趣的表达",结果无意中给了包含奇幻生物比喻的回复更高的分数。模型很快学会了一个捷径:提到哥布林就能拿高分。
问题在于,这个习惯没有老老实实待在极客性格里。数据显示,Nerdy 性格只占 ChatGPT 全部回复的 2.5%,却贡献了 66.7% 的“goblin”出现次数。从 GPT-5.2 到 GPT-5.4,Nerdy 性格下的哥布林出现率飙升了 3881%。更麻烦的是,即使在没有 Nerdy 性格提示词的对话中,哥布林也在同步增长。
OpenAI 给出的解释是一个经典的反馈循环:强化学习先在极客性格里奖励了这种表达,然后模型生成的带哥布林的回复被收录进了下一轮训练数据,模型因此更加习惯输出哥布林,如此循环放大。除了哥布林,浣熊、巨魔、食人魔、鸽子也都被查出是同一机制产生的“tic词”(语言习惯性抽搐)。
【注:tic 原本是医学术语,指不自主的重复动作或发声,OpenAI 在这里借用来形容模型养成的不受控语言习惯。】
修复方面,OpenAI 在今年 3 月下架了 Nerdy 性格,移除了相关奖励信号,并过滤了训练数据中的生物词。但 GPT-5.5 的训练在找到根因之前就已经开始,所以新模型依然带着哥布林习性出厂。目前的临时方案是在 Codex(OpenAI 的编程工具)里通过系统提示词压制。博客里甚至贴了一段命令行代码,教你怎么把哥布林抑制指令去掉,"让小精灵们自由奔跑"。
这篇博客表面上是讲一个好笑的 bug,底下其实揭示了一个 AI 训练的核心难题:你给模型的每一个微小的奖励信号,都可能在你不知道的地方被放大和泛化。一个只针对 2.5% 用户的性格训练,最终污染了整个模型的语言习惯。



OpenAI@OpenAI
We’re talking about Goblins. openai.com/index/where-th…
中文



最近的重度vibe coding的过程不断让我回想起《永无止境》这部电影,英文名是《Limitless》。
电影设定里有一种药物叫做NZT-48,服用之后可以让人调用大脑中潜在的所有信息,可以来自多年前随意翻过的一本书,又或者半醒半梦中看过的一部电影。
电影中主角Eddie凭借这个药物一路开挂,从潦倒作家变成华尔街新贵,直到竞选美国参议员。
LLM就好像是这样的助手,那些在你记忆深处,哪怕只剩下一个轮廓的知识,只要用心描述就能一点点挖出,为你所调用。
但是LLM和NZT一样放大的是你已经有的东西。那些你没经历过的,不曾了解过的,依旧不存在于你的世界。
保持好奇心,保持专注。


中文

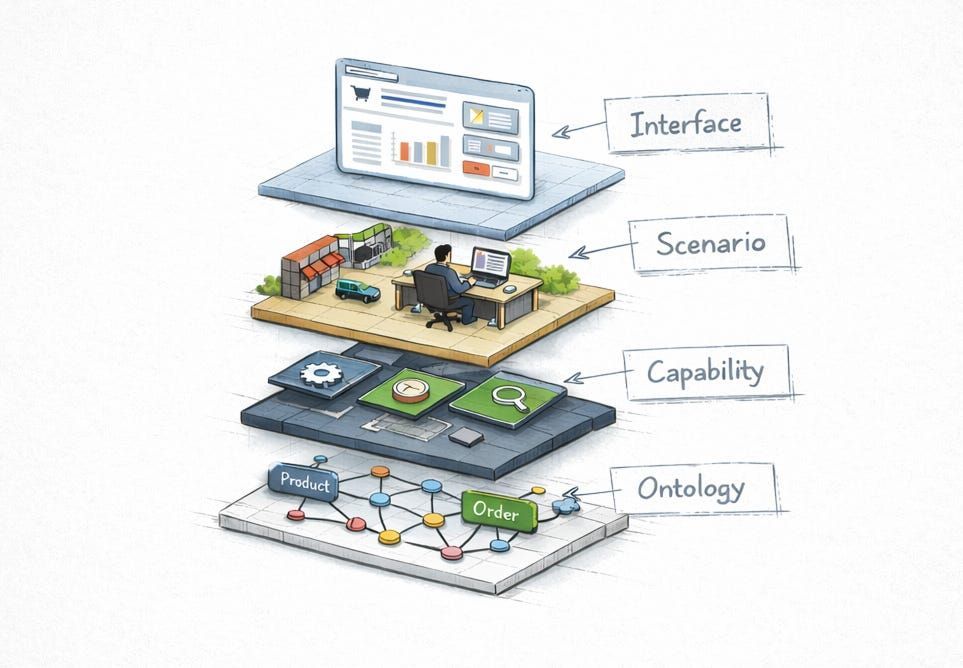
AI 时代的设计师要学会设计"词汇"
如果你不主动定义产品的本体论,大语言模型就会自动替你定义——而这种定义往往前后矛盾,用户体验就会变成一团乱。
Jens Jorgenson 在最近的文章里指出,设计师的职业进化已经来到了关键节点。我们从平面设计师进化到 UX 设计师,现在要成长为"语义设计师"——定义系统中的概念世界,而非仅仅调整界面和流程。这个转变的核心是什么?掌握本体论层的设计。
简单说,本体论就是你用来定义系统中存在哪些对象、它们之间有什么关系、可以执行哪些操作的词汇体系。拥有清晰本体论的产品感觉可预测,易于学习,因为每个操作都能清楚地映射到具体的对象上。反之,模糊的本体论会让整个系统显得复杂又不可控。
更有意思的是,这个抽象层面的思考能直接扩展产品的可能性。就像乐高或 DNA,只需要定义好最小单位和组合规则,就能涌现出无限的变化。我现在在自己的产品里试验把这个方法论落地,从列出最基本的名词开始,再描绘它们之间的动词关系——完全避免 UI 思维。这样做的好处是,当 AI 工具必须理解你的系统时,它能得到真正清晰的指令。
原文链接:figureandground.substack.com/p/the-ontology…
中文

我发现 Vibe Coding 容易有失落感的原因了。之前做项目哪怕最终结果完全失败,过程中也能学会很多东西,有很多随机的发现,体验感是很足的。而现在哪怕项目完全成功,自己可能也啥也没学会,还容易否定自己。
中文
