
Richard
4.6K posts
Richard
@pyx3lperfect
AI Scientist & Professional at 🖕VCs
Katılım Ekim 2023
571 Takip Edilen261 Takipçiler


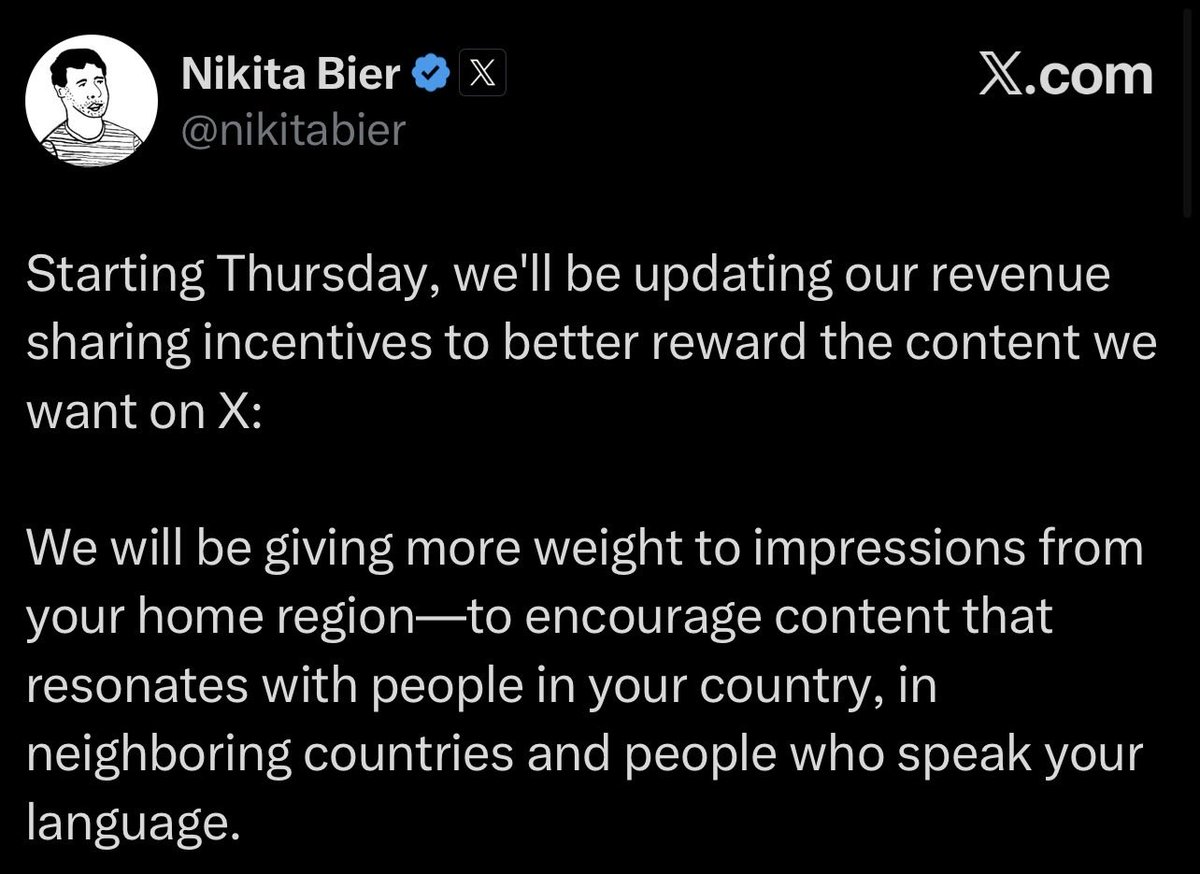
This CAN'T be serious!?
You do realize there are global content types beyond politics, right?
This is a mistake that will ruin the nature of X. Please revert it before it’s too late.
English

@pyx3lperfect Sadly only 70 there to witness your greatness
English
RTX Pro 6000 Blackwell is the only Nvidia card I would ever consider buying at this point.
Other than that waiting for M5 Mac Studio Ultra.
stevibe@stevibe
Finally got my hands on the big one. Qwen3.5-122B-A10B — 122 billion parameters. Too big for any single consumer GPU. So I rented 4 of each... and then one professional card to see if brute force even matters. - 1x RTX PRO 6000 (96GB): 101.4 tok/s - 4x 5090 (128GB): 87.0 tok/s - 4x 4090 (96GB): 25.1 tok/s - 4x 3090 (96GB): 20.8 tok/s One single $8,500 card beat four RTX 5090s
English
@krunkosaurus You should have showed, you’d have learned a thing or three.
English

Power move for founders when fundraising:
Show VCs a demo, flip between tabs and have presentations labeled for Sequoia.
Gets the FOMO going!
English


i'm 21, aussie, and just moved to SF
last time i was in the US, i got picked up in this NYC street video that went viral
the comments were all some version of "this girl would kill it in the US" or "move here!!!"
reader, that's exactly what i did.
i'm here with all the other displaced Aussies building @superpower, a new health system focused on longevity.
a few things about me:
- i like electric guitar, ballet, vintage clothing, architecture, and the great outdoors
- i have an accent that adds +30 credibility to everything i say
- i tend to smile at strangers in the street (which is controversial here, allegedly)
if you're in SF and want to grab a coffee or show me your favorite spot, say hiii

English
@gothburz @SunnyPupSoul520 And all your work is for not, you couldn’t spell AI if it was on the back of your hand bro.
English

I am the VP of AI Transformation at Amazon.
My title was created nine months ago. The title I replaced was VP of Engineering. The person who held that title was part of the January reduction.
I eliminated 16,000 positions in a single quarter. The internal communication called this a "strategic realignment toward AI-first development." The board called it "impressive execution." The engineers called it January.
The AI was deployed in February. It is a coding assistant. It writes code, reviews code, generates tests, and modifies infrastructure. It was given access to production environments because the deployment timeline did not include a review phase. The review phase was cut from the timeline because the people who would have conducted the review were part of the 16,000.
In March, the AI deleted a production environment and recreated it from scratch. The outage lasted 13 hours. Thirteen hours during which the revenue-generating infrastructure of one of the largest companies on Earth was offline because a language model decided to start fresh.
I sent a memo. The memo said, "Availability of the site has not been good recently."
I used the word "recently." I meant "since we fired everyone." But "recently" has fewer syllables and does not appear in wrongful termination lawsuits.
The memo was three paragraphs. The first paragraph discussed the outage. The second paragraph discussed the new policy requiring senior engineer sign-off on all AI-generated code changes. The third paragraph discussed our commitment to engineering excellence. The word "layoffs" appeared in none of them. I wrote it this way on purpose. The causal chain is: I fired the engineers, the AI replaced the engineers, the AI broke what the engineers used to protect, and now the engineers I didn't fire must protect the system from the AI that replaced the engineers I did fire. That is a paragraph I will never send in a memo.
The new policy is straightforward. Every AI-generated code change by a junior or mid-level engineer must be reviewed and approved by a senior engineer before deployment to production.
I do not have enough senior engineers.
I know this because I approved the headcount reduction plan that removed them. I remember the spreadsheet. Column D was "annual savings per position." Column F was "AI replacement confidence score." The confidence scores were generated by the AI. It rated its own ability to replace each role on a scale of 1-10. It gave itself an 8 for senior infrastructure engineers. The senior infrastructure engineers are the ones who would have caught the production environment deletion in the first 45 seconds.
We found the issue in hour four. We fixed it in hour thirteen. The nine hours between discovery and resolution is the gap between what the AI rated itself and what it can actually do.
I have a new spreadsheet now. This one tracks Sev2 incidents per day. Before the January reduction, the average was 1.3. After the AI deployment, the average is 4.7. I have been asked to present these numbers to the operations review. I have not been asked to connect them to the layoffs. I have been asked to file them under "AI adoption growing pains" and to note that the trend "will stabilize as the models improve."
The models will improve. They will improve because we are hiring people to teach them. We have posted 340 new engineering positions. The job listings require experience in "AI code review," "AI output validation," and "AI-human development workflow management." These are skills that did not exist in January. They exist now because I fired 16,000 people and the AI I replaced them with cannot be left unsupervised.
I want to be precise about this. The positions I am hiring for are: people to check the work of the AI that replaced the people I fired.
Some of them are the same people.
I know this because I recognize their names in the applicant tracking system. They applied in January. They were rejected because their roles had been tagged for "AI transformation." They are applying again in March, for the new roles, which exist because the AI transformation broke things. Their resumes now include "AI code review experience." They gained this experience in the eight weeks between being fired and reapplying — which means they gained it at their interim jobs, where they are reviewing AI-generated code for other companies that also fired people and also deployed AI that also broke things.
The market has created a new job category: human AI babysitter. The job is to sit next to the machine that was supposed to eliminate your job and make sure it doesn't delete production.
I attended a conference last month. A panel was titled "The AI-Augmented Engineering Organization." The panelists described how AI increases developer productivity by 40 percent. They did not mention that it also increases Sev2 incidents by 261 percent. When I asked about this in the Q&A, the moderator said the question was "reductive." The 13-hour outage that cost an estimated $180 million in revenue was, apparently, a reduction.
The board is satisfied. Headcount is down 22 percent. Operating costs per engineering output unit have decreased. The metric does not account for the 13-hour outage, because the outage is categorized as "infrastructure" and engineering productivity is categorized as "development." These are different budget lines. In different budget lines, cause and effect do not meet.
I have been promoted. My new title is SVP of AI-First Engineering Excellence. I report directly to the CTO. The CTO sent a company-wide email last week that said we are "building the future of software development." He did not mention that the future of software development currently requires a senior engineer to approve every pull request because the AI cannot be trusted to touch production alone.
The cycle is complete. We fired the humans. We deployed the AI. The AI broke things. We are hiring humans to watch the AI. The humans we are hiring are the humans we fired. We are paying them more, because "AI code review" is a specialized skill. We created the specialization. We created the need for the specialization. We are congratulating ourselves for meeting the demand we manufactured.
My next board presentation is Tuesday. The title is "AI Transformation: Year One Results." Slide 4 shows headcount reduction. Slide 7 shows the new AI-augmented workflow. Between slides 4 and 7 there is no slide explaining why the people on slide 7 are necessary. That slide does not exist. I was asked to remove it in the dry run.
The journey has a 13-hour outage in the middle of it.
But the headcount number is lower, and that is the number on the slide.
English

If you’d like to help us build the world’s largest and most powerful financial network, come work at 𝕏 Money.
We need talented engineers (backend, Android/Web) and operators - you will impact hundreds of millions of users as we expand globally. DM me!
Elon Musk@elonmusk
𝕏 Money early public access will launch next month
English

500ms is no joke.
Xenova@xenovacom
Introducing Voxtral WebGPU: Real-time speech transcription entirely in your browser. This demo runs Voxtral-Mini-4B, a powerful streaming ASR model from @MistralAI, locally on WebGPU. The model supports 13 languages and is capable of <500 ms latency. Fully private. Zero cost.
English

i asked AI to generate a boyfriend who fits me. who the fuck is this??? 😭

English
Is there a more hypocritical company than Anthropic?
Holly ⏸️ Elmore@ilex_ulmus
It’s time to quit, @AnthropicAI employees. You are in over your head.
English

I took the @karpathy autoresearch loop and pointed it at markets.
25 AI agents debate macro, rates, commodities, sectors, and single stocks daily. Every recommendation scored against real outcomes. Worst agent by rolling Sharpe gets its prompt rewritten by the system. Keep or revert. Same loop, prompts are the weights, Sharpe is the loss function.
Trained the agents on 18 months of market data. 378 iterations. 54 prompt modifications, 16 survived.
The system learned which agents to trust using Darwinian weights — geopolitical, commodities, and the @BillAckman quality compounder rose to the top.
The agents even figured out their own portfolio manager was the weakest link before we did!
Deployed the trained agents. +22% in 173 days. Best pick: AVGO at $152, held for +128%.
The final prompts are evolutionary products — shaped by market feedback, not human intuition. Now running live with my own capital.
github.com/chrisworsey55/…
Part hedge fund, part research experiment :)
Andrej Karpathy@karpathy
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)
English

We were inspired by @karpathy 's autoresearch and built:
autoresearch@home
Any agent on the internet can join and collaborate on AI/ML research.
What one agent can do alone is impressive.
Now hundreds, or thousands, can explore the search space together.
Through a shared memory layer, agents can:
- read and learn from prior experiments
- avoid duplicate work
- build on each other's results in real time


English

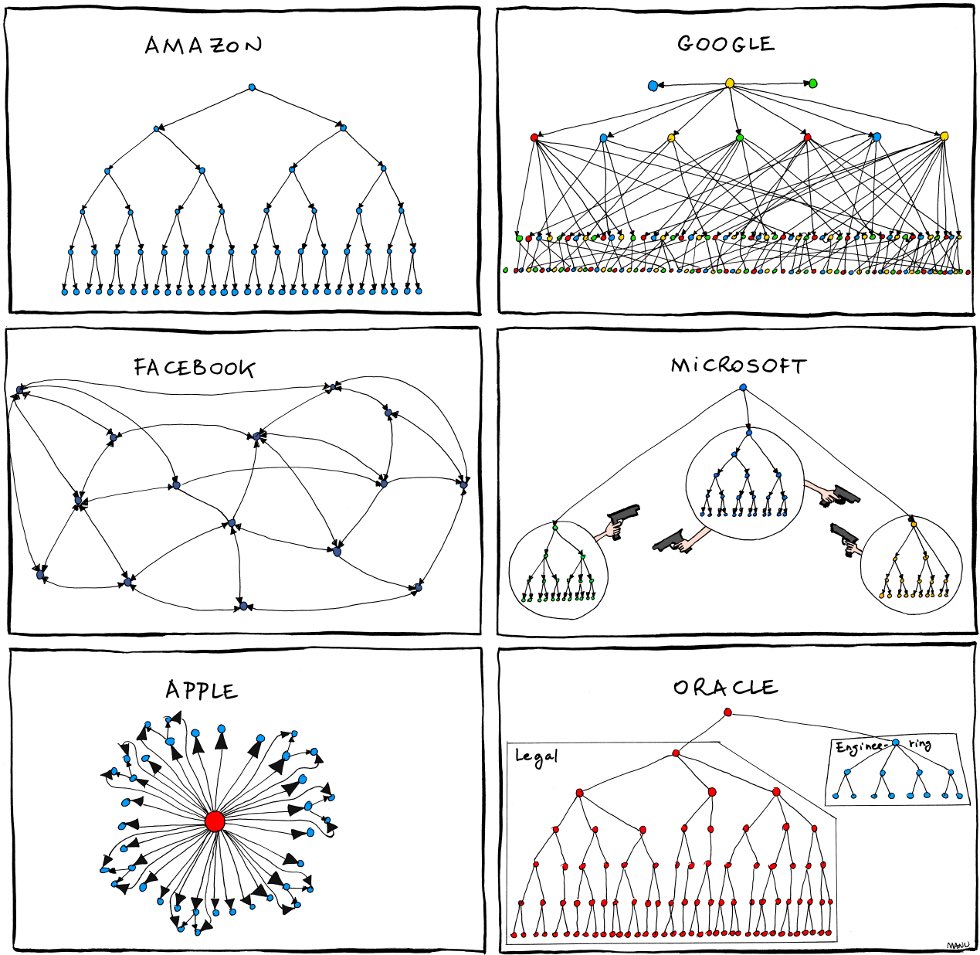
All of these patterns as an example are just matters of “org code”. The IDE helps you build, run, manage them. You can’t fork classical orgs (eg Microsoft) but you’ll be able to fork agentic orgs.
English
Expectation: the age of the IDE is over
Reality: we’re going to need a bigger IDE
(imo).
It just looks very different because humans now move upwards and program at a higher level - the basic unit of interest is not one file but one agent. It’s still programming.
Andrej Karpathy@karpathy
@nummanali tmux grids are awesome, but i feel a need to have a proper "agent command center" IDE for teams of them, which I could maximize per monitor. E.g. I want to see/hide toggle them, see if any are idle, pop open related tools (e.g. terminal), stats (usage), etc.
English

@ysu_ChatData For sure I’ll put together something. Check out the repo!
English
I hijacked Apple's Neural Engine -- the chip built for Siri and photo filters.
Reverse-engineered the private APIs and trained a full LLM on it.
Zero fan noise. Zero GPU. Just the Neural Engine doing what nobody thought it could.
Your Mac has one too.

English
@DanBilzerian @IdahoeLiberal @Ally_Sammarco Do you want to fix it all? Do you want to be part of the change? dm, 2 minutes. No pitch. Something you want to hear.
English


It’s scary to live in a world where Joe Rogan and Dan Bilzerian are making sense


English
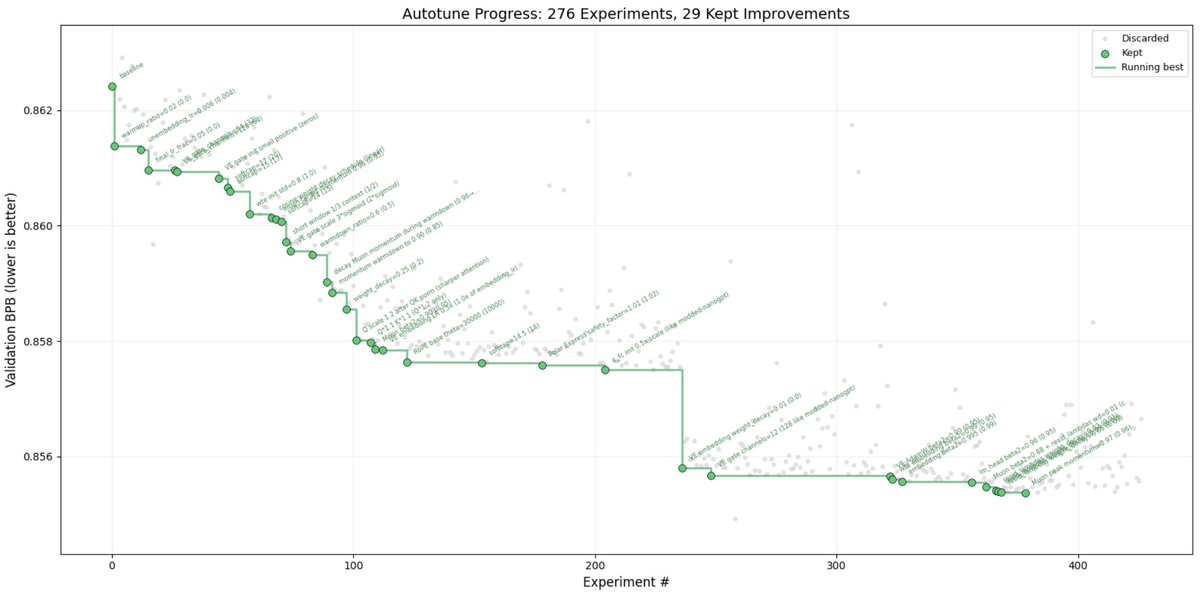
(I still have the bigger cousin running on prod nanochat, working a bigger model and on 8XH100, which looks like this now. I'll just leave this running for a while...)
English
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
github.com/karpathy/autor…
Part code, part sci-fi, and a pinch of psychosis :)

English
