rainworm.eth retweetledi

复刻了大神@DilumSanjaya的视觉框架,建了一个 F-22、F -35、星舰、猛禽发动机的展示网页。主要有 3 步:
1、使用 GPT 2 Image 生成模型三视图,
2、然后在 ComfyUI 里使用 Hunyuan 3.1生成对应的模型,
3、把大神@servasyy_ai开源的仓库丢给 Codex,然后换个SpaceX 网站的风格就可以了。
github.com/huangserva/3DC…
非常轻松就可以搞定了
中文
rainworm.eth
1.1K posts



Just created my own AAA game with GPT image 2 and Seedance 2


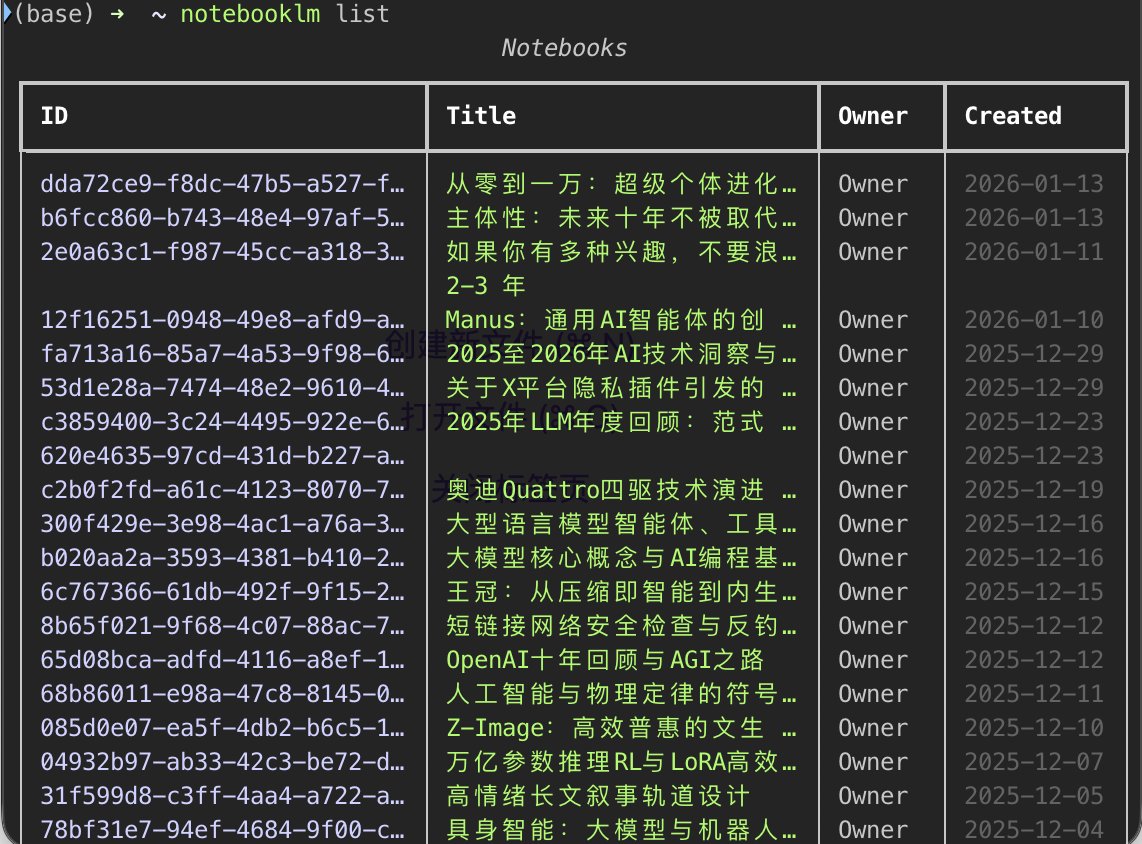
推荐一些我目前安装的Claude Skills: 1. Anthropic官方Skills github.com/anthropics/ski… 2. Superpowers 1.6万Star的Skill精选,从脑暴、写需求文档、开发、测试全包含,口碑相当好。 github.com/obra/superpowe… 3. Planning-with-files 参考Manus的Agent方法写的Skill。很适合多步骤任务,用这个Skill指导其他Skill工作也挺好。 github.com/OthmanAdi/plan… 4. X-article-publisher-skill 王树义老师写的X文章发布Skill, 这个值得研究下,后续看看能不能实现其他平台的自动化 github.com/wshuyi/x-artic… 5. NotebookLM skill 自动上传PDF、Youtube链接到NotebookLM,很适合NotebookLM内容的自动化处理 github.com/PleasePrompto/… 还有一些是自己平时总结的内容创作skills,后续继续分享具体使用场景案例!


最新的界面做好了!如果大家喜欢的话,这个版本的skill我们也开源😆


开源顶端 AI 技术日报生成器,杜绝垃圾噪音! 这个开源 github 把 Andrej Karpathy 推荐体系里那批顶级技术博客(约 90 个 RSS/Atom 源)的新文章抓下来,用 AI 从相关性 / 质量 / 时效性三维打分、自动分类、提炼摘要与关键词,然后输出一份结构化的 Markdown 日报。默认用 Gemini,如果 Gemini 挂了还能自动降级到 OpenAI 兼容 API(比如 DeepSeek 这类 endpoint)。 // OpenClaw 操作精简版: 1/ 把项目丢给 OpenClaw: github.com/vigorX777/ai-d… 告诉它装好并设置每天几点 XX:XX 跑一次,把日报发到指定地方。 2/ 贴 API(选一个就行): Gemini:直接给 key (免费领取 key aistudio.google.com/apikey) 或 OpenAI 兼容:给 endpoint + key + model(比如 deepseek-chat) 3/ 想立刻验收就加一句: “这个日报现在发送一份看看” 完成后就是固定节奏:每天 XX:XX 自动生成 + 自动投递,你只负责起床打开看!










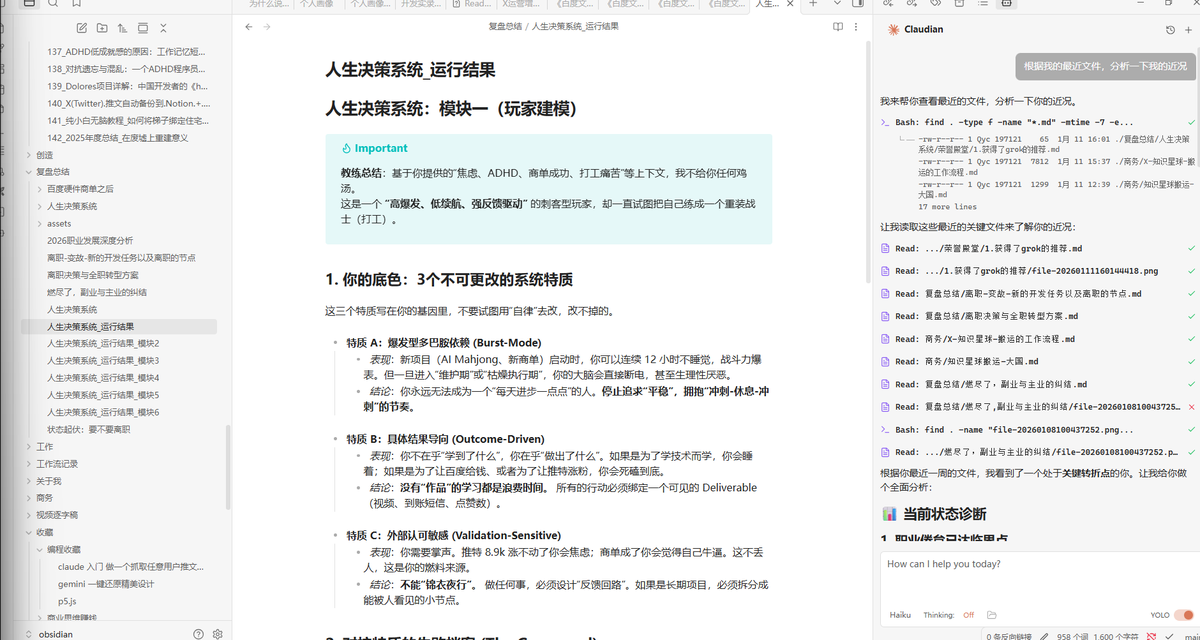
突然想到一句话,有一种宿命感一下子击中的感觉: “你未曾解决的问题,会反复的出现你生命中,直到你彻底解决。” 这两天我又陷入了一波情绪低谷中,在反复的纠结要不要裸辞,去追寻自己喜欢的东西上。 理性告诉我,这不是裸辞最好的时机,副业目前不稳定,大环境就业形式也不好,离职之后注定会陷入几个月的动荡期中; 但感性告诉我,我目前工作两年已经攒下一笔足够我折腾几年的资金了。 而且我年轻,无任何负债,现在已经厌倦了在职场为别人的梦想努力了,还有什么理由不去做自己想做的事情呢?




