
Pablo Ramos
15.2K posts

Pablo Ramos
@ramospablo
Security researcher dissecting AI risks, privacy threats & digital shadows. Traveler lost in the Internet. Views my own.
#lost Katılım Eylül 2009
1.4K Takip Edilen1.2K Takipçiler

Waitress just told me that I can't work on my laptop during the weekend.
That I must close my laptop because it's weekend.
I'm about to lose it right now.
GIF
English
Okay guys, had a few cultural shocks in Spain:
> Go to the gym, opens 10am on a Sunday
> Go to work from a coworking, closed
> Go to a coffee shop, no wifi
Absolutely unthinkable in a barely productive economy like the US, yet alone UAE.
Europe is a daylight museum.
English
@jvrsanch Pretty nice and interesting analysis.
Still I believe there is a lot of opportunity for Engineers in Spain
English

Un VP Eng. en 🇪🇸 cobra lo mismo que un Entry level en 🇺🇸 ~120k
Es triste, pero asi estamos
Puedo cobrar 120k estando en España?
Claro! Pero como?
Trabajando para una empresa the US/Global desde España.
Yo lo hice, y no es magia negra.
~120k es lo MÍNIMO que se cobra fuera
Llegando a cobrar mucho más si eres bueno
Cuando en el entrevista os preguntan cuanto estáis dispuestos a cobrar, la gente dice lo que en España es un buen sueldo (30-40k)
Y ellos se ríen por dentro porque tenían un budget de 140k para el puesto
Los motivos de la poca competitividad en España son muchos
Tiene pinta que uno de ellos es que las empresas tienen ambición nacional o mercados emergentes
Y no da para pagar salarios competitivos globales
"Pero las big tech son globales", ya pero no son tontas y ya tienen estructuras de HR montadas en España
Entienden cómo están las cosas y se aprovechan. Mismos puestos en US pagan x3
Las startups/scaleups de 🇺🇸 son el MEJOR arbitraje que se puede hacer
- Deseosos de contratar gente buena (que en España hay de sobra)
- Sin tiempo para optimizar costes como big tech
- Y lo más importante, TIENEN DINERO!
@elwatto es un buen ejemplo de salarios dentro de mercado
@exp8fellowship con @GuliMoreno está ayudando a muchos chavales para que vean el mundo que hay fuera
En @rebolthq buscamos gente buena en España, tanto en remoto como para venirse a San Francisco
No os conforméis com números de 30-50k, podeis conseguir mucho mas!
Fuente: levels .fyi debajo


Borja Perez Ⓜ️@borjaperfra
Español
@GergelyOrosz Is the hypothesis that they were testing the crowd reaction and a potential response.
If they actually pull it off would others follow?
Also there is a theory of computing availability so who knows!
English

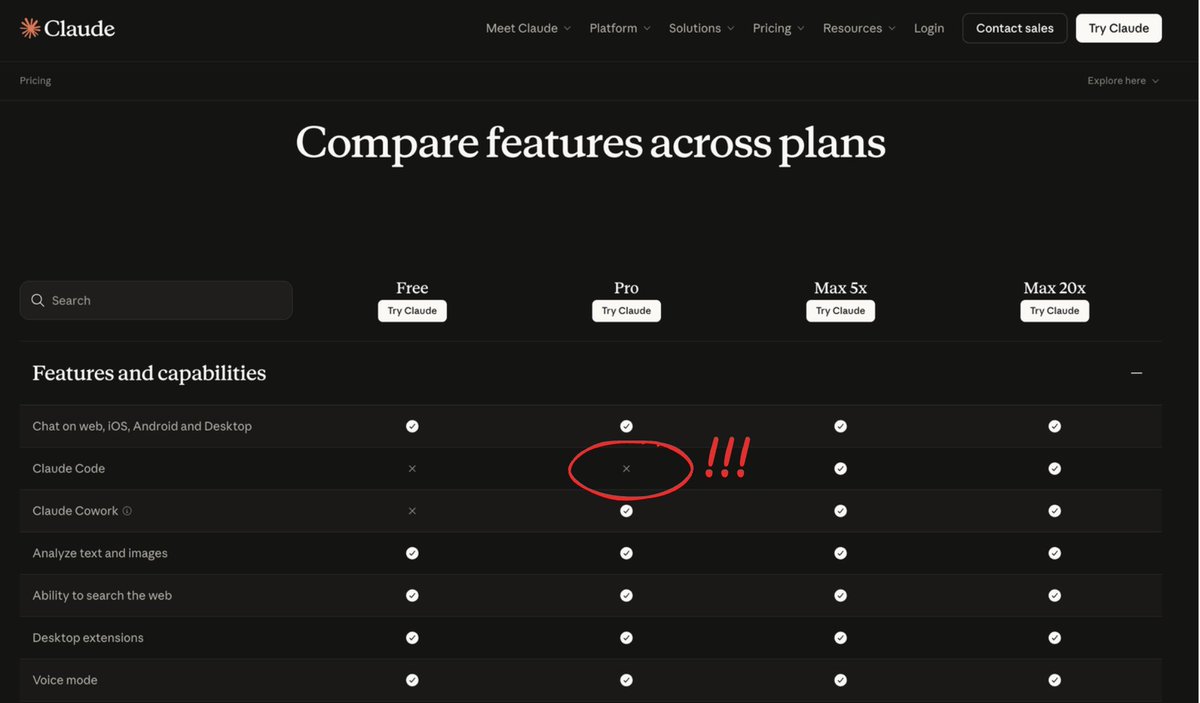
... and Anthropic reverted this change. Claude Code is now part of Pro, as per the Pricing page.
Important note on the growth hack: Anthropic advertises safety and integrity as their values. A "fake door test" is fundamentally incompatible with such values... pick one

English
Confirmed that Anthropic - as of now - has removed Claude Code from new Pro signups. This is what the pricing page looks like.
Feels like Anthropic has the bet that those doing coding work will be willing and ready to pay at least $100/month, going forward.
English
@staples46198 @MilkRoadAI I think there is also the point that @ylecun always points into the LLMs approach to knowledge is fundamentally wrong and why he is now approaching a different paradigm.
Large LLM models are way past being trained with the internet data and loads is synthetic data used
English

@MilkRoadAI So basically the frontier models brute force the intelligence instead of training on clean data. Sounds like a business opportunity - clean training data.
English

Andrej Karpathy just made one of the most interesting arguments about AI model design that most people are completely missing.
His take is that frontier AI models are not too big because the technology is complex and too big because the training data is garbage.
When you or I think of the internet, we picture Wall Street Journal articles, Wikipedia entries, serious writing.
That is not what a pretraining dataset looks like.
When researchers at frontier labs look at random documents from the actual training corpus, it is stock ticker symbols, broken HTML, spam, gibberish.
One estimate puts Llama 3's information compression at just 0.07 bits per token meaning the model has only a hazy recollection of most of what it trained on.
So we build trillion parameter models not because we need a trillion parameter brain but because we need a trillion-parameter compression engine to squeeze some intelligence out of a firehose of noise.
Most of those parameters are doing memory work, not cognitive work.
Karpathy's prediction is separate the two entirely.
Build a cognitive core, a model that contains only the algorithms for reasoning and problem-solving, stripped of encyclopedic memorization and pair it with external memory that it can query when it needs facts.
He thinks a cognitive core trained on high-quality data could hit genuine intelligence at around one billion parameters.
For reference, today's flagship models run between 200 billion and 1.8 trillion parameters with most of that weight dedicated to remembering the internet's slop.
The trend is already moving his direction. GPT-4o operates at roughly 200 billion parameters and outperforms the original 1.8 trillion-parameter GPT-4.
Inference costs for GPT-3.5-level performance dropped 280-fold between 2022 and 2024 driven almost entirely by smaller, cleaner, better-architected models.
The real bottleneck in AI right now is not compute but rather data quality.
English
The simplicity on the importance of these skills is why you need to read this.
Reshape your skills.
Shubham Saboo@Saboo_Shubham_
English
@Av1dlive Many positive notes on the long term thinking and they way Elon moves.
English


Pablo Ramos retweetledi

LiteLLM HAS BEEN COMPROMISED, DO NOT UPDATE. We just discovered that LiteLLM pypi release 1.82.8. It has been compromised, it contains litellm_init.pth with base64 encoded instructions to send all the credentials it can find to remote server + self-replicate. link below
English
@davidonchainx You can still use the Mac mini to run this things with Claude remotely.
English

People who spent $700 on a mac mini to run an openclaw agent watching claude launch all the features natively for $20
Claude@claudeai
You can now enable Claude to use your computer to complete tasks. It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk. Research preview in Claude Cowork and Claude Code, macOS only.
English
@thomasunise @levie That’s a good similarity.
You can measure an engineer in lines of code as you can’t measure in token used.
English

@levie This is like equating coding productivity to lines of code
You don’t want someone just producing lots of code, you don’t want someone just using lots of tokens
You want someone who is productive and generates ROI
He’s says this because he’s billions in the hole on LLMs
English

Without getting into the specific numbers, this underlying concept and trend is going to be very real. For any worker who is able to wield AI agents effectively in an organization, their compute budgets are just going to monotonically go up over time.
This will of course start in engineering, where we already know developers can run multiple agents in parallel, or have projects going over night. But this eventually hit the rest of knowledge work as well. Lawyers that can create and review more drafts, marketed that can build more campaigns and test more ideals in parallel, sales reps that can reach out to more customers and process more leads.
Many of these activities will essentially be token-dependent in how much work a single person can do. These aren’t chatbot workflows answering a simple question, but agents that are running and processing through incredible amounts of data at scale, and generating all new forms of information.
Companies will have to figure out how they budget for this, and it likely won’t be an IT budget item over time, but ultimately owned and allocated by the business. Maybe the CFO is ultimately the head of AI :-).
TFTC@TFTC21
Jensen Huang: "If that $500,000 engineer did not consume at least $250,000 worth of tokens, I am going to be deeply alarmed. This is no different than a chip designer who says 'I'm just going to use paper and pencil. I don't think I'm going to need any CAD tools.'"
English
We are being challenged to properly measure the usage and impact of AI in more than tokens.
English
Token usage is a signal, but it can be also a waste.
Balance between usage, output and impact is key.
Your whatever money engineer cannot be measure in how much money it spend in tokens.
This is not wrong but signaling into an incorrect metric to probe the worth of an engineer
sunny madra@sundeep
“If your $500K engineer isn’t burning at least $250K in tokens, something is wrong.”
English
Pablo Ramos retweetledi


Pablo Ramos retweetledi

Folks, if you get crypto emails from websites claiming to be associated with openclaw, it's ALWAYS a scam.
We would never do that. The project is open source and non-commercial. Use the official website. Be sceptical of folks trying to build commercial wrappers on top of it.
English
A must listen if you are in tech. podcasts.apple.com/es/podcast/sca…
English
If this is true then a whole industry as important as pharmaceutical is about to get disrupted
dev@zivdotcat
POV: A guy with ChatGPT and Google AlphaFold just built a custom mRNA cancer vaccine to save his dog. this story is actually insane. a tech guy in australia adopted a rescue dog with aggressive cancer and only months to live. so he did something wild: > paid ~$3k to sequence the tumor dna > used chatgpt to analyze the mutations > used google’s alphafold to model the proteins > identified drug targets and designed a custom mRNA cancer vaccine he had zero background in biology. after months of paperwork, the vaccine was approved and injected. within weeks the tumor shrank dramatically and the dog started recovering. meanwhile pharma companies are running $1B trials to do the exact same thing. the future of personalized medicine with AI is going to be insane.
English

I currently run 412 OpenClaw agents 24/7 across 31 Mac Minis.
They’re:
• building apps
• automating my life
• generating business ideas
People ask how to replicate this system.
It’s actually very simple.
You just need about 30 Mac Minis, a solid imagination, and absolutely no fear of making things up on the internet.
English

Small accounts posting to absolutely ZERO engagement

English
Local AI Agents are becoming easier and easier to set up and use.
While big models and services will always have the compute power there are new options for people that want to control the flows, information and create.
medium.com/a-bit-off/loca…
English