Sabitlenmiş Tweet

Haseeb Raja
21.4K posts

@rh__147
Is it just me or is it getting crazier out there?




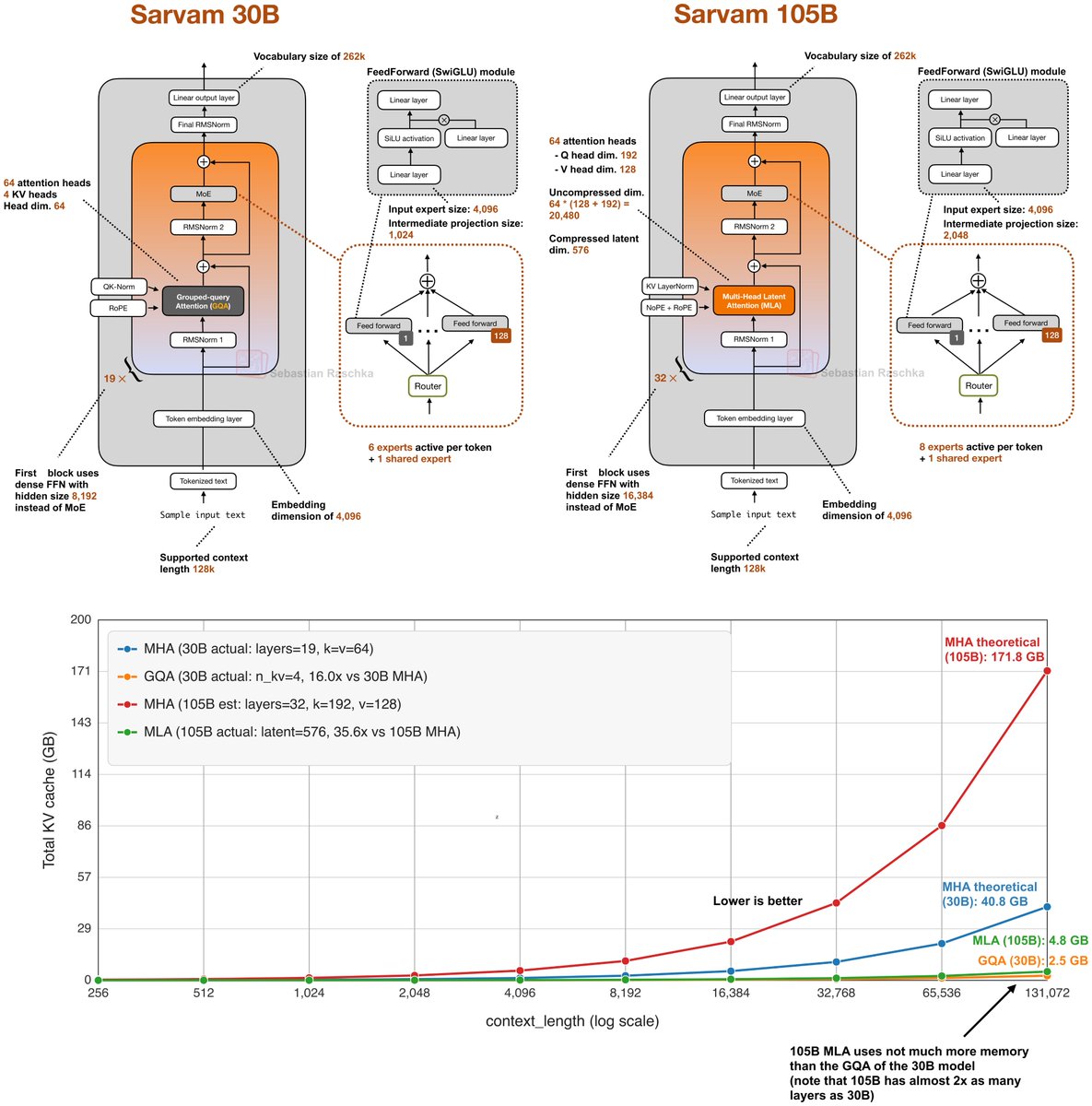
📢 Open-sourcing the Sarvam 30B and 105B models! Trained from scratch with all data, model research and inference optimisation done in-house, these models punch above their weight in most global benchmarks plus excel in Indian languages. Get the weights at Hugging Face and AIKosh. Thanks to the good folks at SGLang for day 0 support, vLLM support coming soon. Links, benchmark scores, examples, and more in our blog - sarvam.ai/blogs/sarvam-3…





A beautiful paper from MIT+Harvard+ @GoogleDeepMind 👏 Explains why Transformers miss multi digit multiplication and shows a simple bias that fixes it. The researchers trained two small Transformer models on 4-digit-by-4-digit multiplication. One used a special training method called implicit chain-of-thought (ICoT), where the model first sees every intermediate reasoning step, and then those steps are slowly removed as training continues. This forces the model to “think” internally rather than rely on the visible steps. That model learned the task perfectly — it produced the right answer for every example (100% accuracy). The other model was trained the normal way, called standard fine-tuning, where it only saw the input numbers and the final answer, not the reasoning steps. That model almost completely failed — it only got about 1% of the answers correct. i.e. model trained with implicit chain of thought, called ICoT, gets 100% on 4x4 multiplication while normal training could not learn it at all