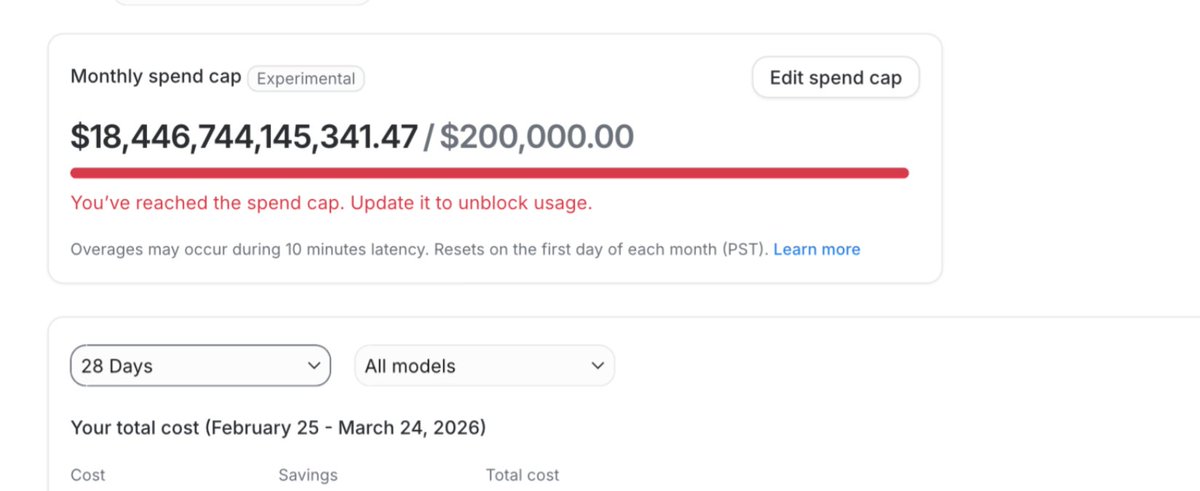
@NoLimitGains Not when expectation of future earnings is dropping fast...
English
Robert
1.1K posts

@robert_heimir
🚀Building in Fintech, Proptech, Legaltech - 15 b. tokens YTD. https://t.co/AhS4N6dIYZ | https://t.co/oRFB2cGX12 | https://t.co/2eZNMq4P0r | legalcode.md



We've signed an agreement with Google and Broadcom for multiple gigawatts of next-generation TPU capacity, coming online starting in 2027, to train and serve frontier Claude models.



A small thank you to everyone using Claude: We’re doubling usage outside our peak hours for the next two weeks.



Introducing Expect Let agents test your code in a real browser 1. Run Claude Code / Codex to QA your app 2. Watch a video of every bug found 3. Fix and repeat until passing Run as a CLI or agent skill. Fully open source

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI

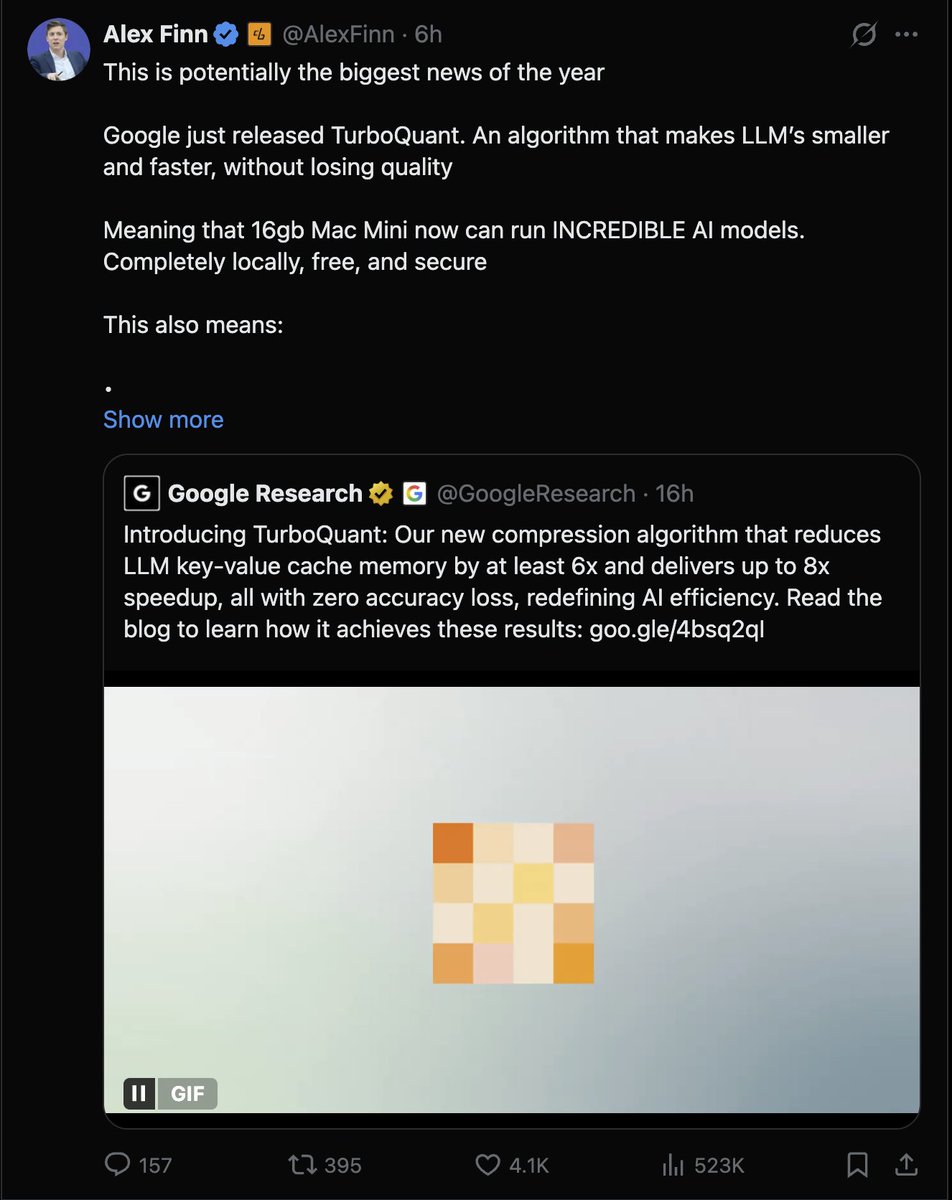


Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI

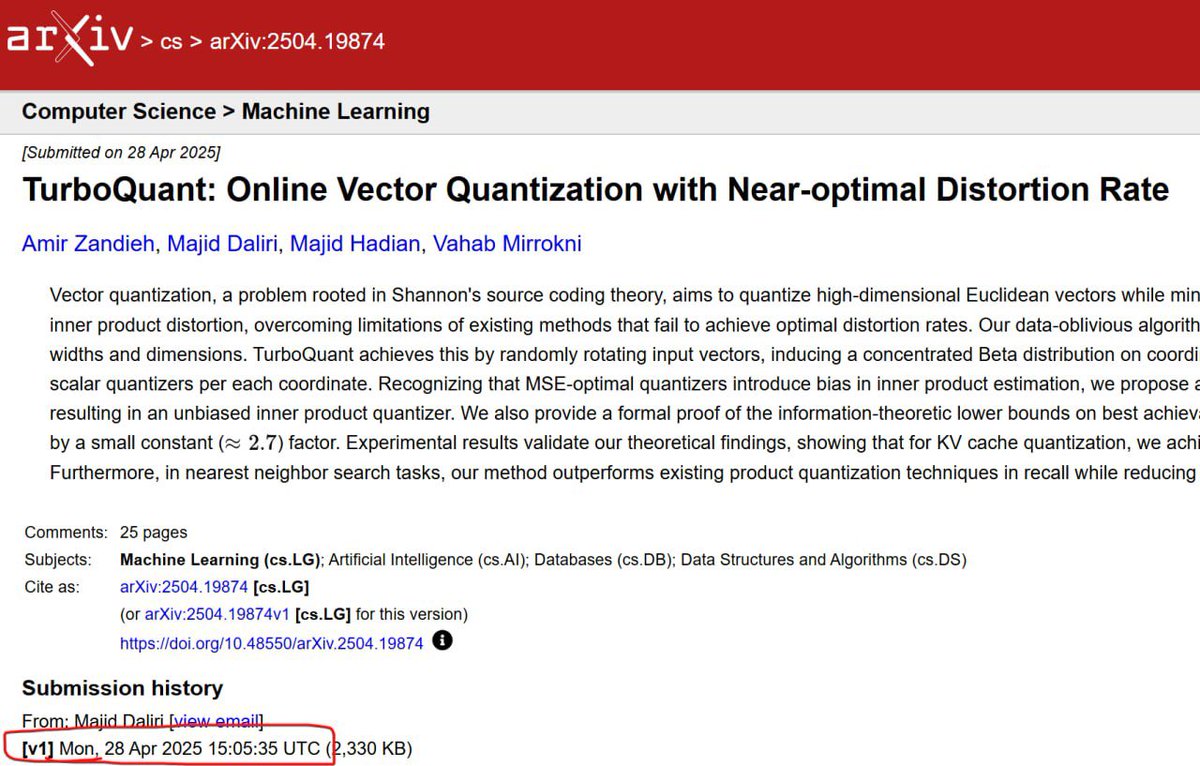
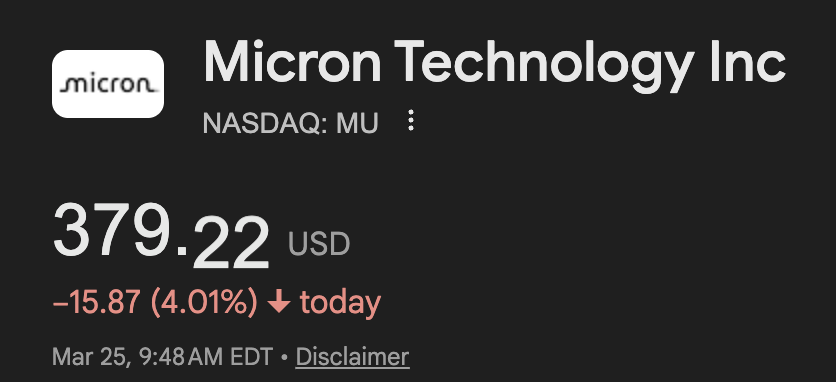
The fact that memory stocks are crashing because of Google’s Turboquant is a pretty good indicator of how many clueless people this market is filled with. It’s like saying Aramco should crash because Toyota came out with a next-generation hybrid engine.



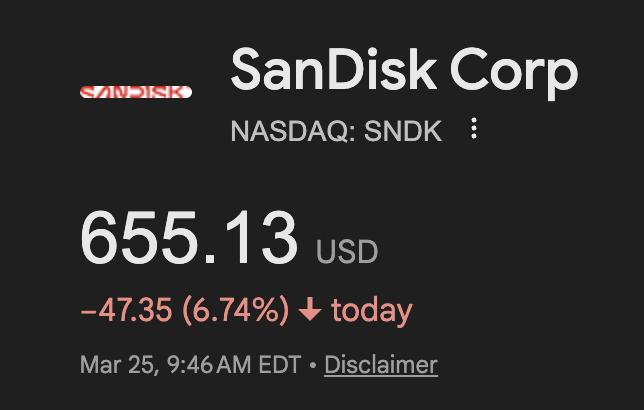
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI