Woody Lu retweetledi

想研究 Claude Code 工作原理的看这个 ccunpacked.dev Claude Code Unpacked 吧,今天 HackerNews 排名第一,纯纯交互式,看的非常清晰,里面四大分类有:agent loop, 50+ tools, multi-agent orchestration, and unreleased features
做的特别好。
中文
Woody Lu
4.4K posts


@rollothomasi123
Investment, Software Engineering, GenAI, Phenomenology, Universe



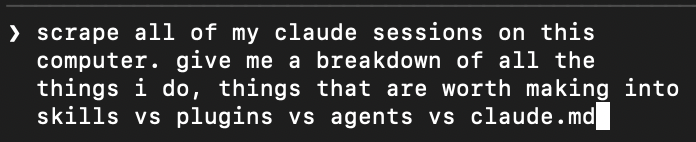
From QT - //But if Anthropic found that training above a certain scale, or in a certain way at that scale, produces capabilities that sit far above the prior trendline, then that is an architectural breakthrough.// I believe this is the case, not just because an architectural and algorithmic breakthrough at this scale cannot be achieved in isolation, but also because, even if it were, it would soon leak via employee turnover, corporate espionage, or many other means. The moat of a frontier lab lies in enormously scaling an advancement, or simply in scaling a Transformer++ arch. I don't think any of the frontier lab would purely bet on an architectural or algorithmic breakthrough (that could be easily replicated like CoT reasoning/thinking was replicated by almost everyone) for them to be at the frontier! In addition to this business logic, research from @EpochAIResearch supports the same conclusion. From @ansonwhho's research - //For example, @MITFutureTech found that shifting from LSTMs (green) to Modern Transformers (purple) has an efficiency gain that depends on the compute scale: - At 1e15 FLOP, the gain is 6.3× - At 3e16 FLOP, the gain is 26× Naively extrapolating to 1e23 FLOP, the gain is 20,000×!// If Anthropic found that training above a certain scale... produces capabilities that sit far above the prior trendline... they would definitely attempt it, as it can be done by only two other labs in the world. This is especially relevant given that those two labs have their tentacles in everything from adult content slop to search engine & browser wars, thinning their available compute for a final training run of a single model. Source - epoch.ai/gradient-updat… Since past final training runs have typically accounted for <30% of total R&D compute, a significant amount of compute remains unused for these runs. It is possible that the compute allocated for final training runs has now been increased substantially. The largest final training run known to humanity occurred in late 2024 for GPT-4.5, which OpenAI officially released on February 27, 2025. Not a single GB200 NVL72 was available at that time. However, by early 2026, we have access to thousands of GB200 and GB300 NVL72 racks, along with more diversified compute from AMD, Google (TPUs), AWS (Tranium), and many other providers. All available evidence and reasonable inferences suggest that the observed step-change improvements are likely large primarily because Ant scaled final training run compute significantly, rather than due to a multitude of new innovations. Source - epoch.ai/gradient-updat… Total @EpochAIResearch victory - @datagenproc @cherylwoooo @Jsevillamol and the team!

Three weeks ago there were rumors that one of the labs had completed its largest ever successful training run, and that the model that emerged from it performed far above both internal expectations and what people assumed the scaling laws would predict. At the time these were only rumors, and no lab was attached to them. But in light of what we now know about Mythos, they look more credible, and the lab was probably Anthropic. Around the same time there were also rumors that one of the frontier labs had made an architectural breakthrough. If you are in enough group chats, you hear claims like this constantly, and most turn out to be nothing. But if Anthropic found that training above a certain scale, or in a certain way at that scale, produces capabilities that sit far above the prior trendline, then that is an architectural breakthrough. I think the leaked blog post was real, but still a draft. Mythos and Capybara were both candidate names for the new tier, though Mythos may now have enough mindshare that they end up keeping it. The specific rumor in early March was that the run produced a model roughly twice as performant as expected. That remains unconfirmed. What is confirmed is that Anthropic told Fortune the new model is a 'step change,' a sudden 2x would certainly fit the definition. We will find out in April how much of this is true. My own view is that the broad shape of this is correct even if some of the numbers are wrong. And if it is substantially accurate, then it also casts OpenAI's recent restructuring in a new light. If very large training runs are about to become essential to staying in the game, then a lot of their recent decisions, like dropping Sora, make even more sense strategically. For the public, this would mean the best models in the world are about to become much more expensive to serve, and therefore much more expensive to use. That will put pressure on rate limits, pricing, and subscription plans that are already subsidized to some unknown degree. Instead of becoming too cheap to meter, frontier intelligence may be about to become too expensive for most of humanity to afford. Second-order effects; compute, memory, and energy are about to become much more important than they already are. In the blog they describe the new model as not just an improvement, but having 'dramatically higher scores' than Opus 4.6 in coding and reasoning, and as being 'far ahead' of any other current models. If this is the new reality, then scale is about to become king in a whole new way. It would also mean, as usual, that Jensen wins again.











马斯克据悉将SpaceX IPO时机定在6月中旬,因6月会有3年多来首次金木合相(金星与木星在天空中运行至极其接近的位置)以及马斯克的生日(6月28日)。 SpaceX此次IPO计划融资最高约500亿美元,对应估值约1.5万亿美元,远超2019年沙特阿美290亿美元的募资规模纪录。


Did you know about the opusplan model in Claude Code? /model opusplan It's a hybrid alias that automatically uses Opus in plan mode for complex reasoning, then switches to Sonnet for execution. Best of both worlds: Opus thinks, Sonnet builds




The divergence in the last few months has been incredible. Under a normal distribution, that's a one-in-1.7 trillion event. Of course markets are fat-tailed — but even by fat-tail standards, this is off the map. Prior peak was 4σ in 2003. (2/3)