Sabitlenmiş Tweet

Aaditya Salgarkar
112 posts
@salgarkarap
https://t.co/ABlJ2qKYvx


@mathandcobb an explicit drawing doesnt seem possible, but maybe the last paragraph satisfies your request. (its essentially a projection of the lattice construction in another field into R^2)


It seems odd that there’s a rough societal consensus that 1+x=0 needs to have a solution—and that it’s not just an imaginary number to appease the accountants—but 1+x²=0 need not have a solution, unless it’s an imaginary number to appease the physicists and electrical engineers.


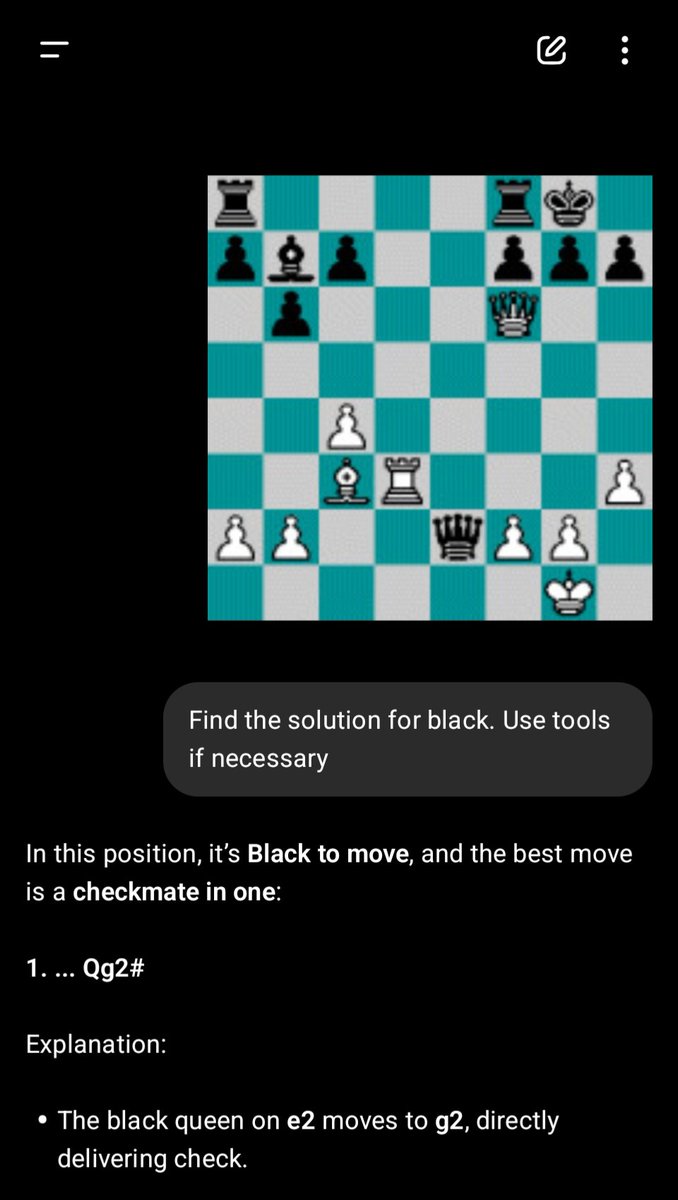
Are you up for a challenge? openai.com/parameter-golf









@simonw Skills actually came out of a prototype I built demonstrating that Claude Code is a general-purpose agent :-) It was a natural conclusion once we realized that bash + filesystem were all we needed