Sabitlenmiş Tweet

Sagar Allamdas
1.7K posts

@sallamdas
AI for everyone! Everyone's building AI. Few are asking who it's actually for. No investment advice. Views are my own.


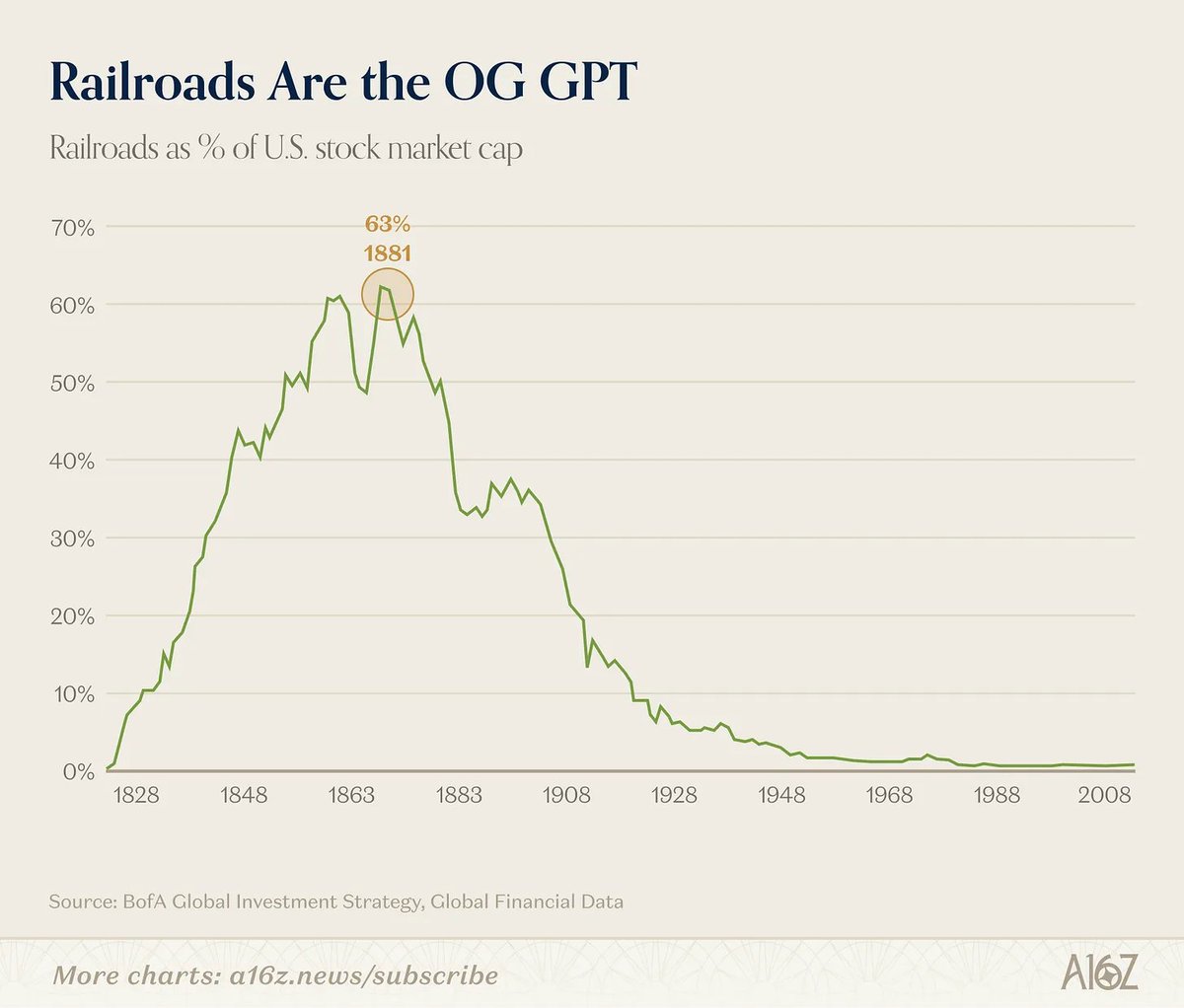

今天芯片圈最大的新闻,莫过于Gerard在创立Nuvia CPU被高通收购五年之后,重新出发,新创立了ARM CPU公司,名字也跟之前非常像,叫Nuvacore 现在这个时间点做数据中心CPU,确实是赶上了CPU十年来最好的时代: AI agent带来CPU短缺潮已经经隐隐浮现,AWS多个客户都提出要包揽所有Graviton ARM CPU产能 ------------ 这个消息对硅谷的芯片打工人吸引力是巨大的,Nuvacore这次的阵容都是功成名就的明星阵容,以前Nuvia创始团队重新集合,拿了红衫的投资,做面向 AI 基础设施/agentic computing 的通用ARM CPU。当年还是一个尚未完全被验证的大方向都能大获成功,而现在ARM CPU服务器正在风口浪尖上,前景和想象力和2019年Nuvia比起来大了太多了 上一次Gerard把Google,苹果platform architecture组的架构大佬挖了好多过去,这次的号召力只会强得多,240m的融资,已经验证过的路径和创始团队,肉眼可见的下一个增长风口,一定会让Nuvacore成为湾区最热门最受追捧的芯片startup,没有之一。毕竟这是一个肉眼可见能财富自由而且风险收益比极好的机会 ---------- 遥想当年Nuvia第一代CPU的发布赶上苹果M2时代,还是挺震撼的,Nuvia让高通在一年的时间CPU跑分进步了整整三代,单核跑分从2300变成3200,竟然超过了苹果M2 max一大截 可惜Nuvia Phoenix core从发布到最后上市拖了太久太久,中间苹果把牙膏挤爆了连着上市了M3/M4,于是Nuvia CPU上市之后从跟M2比较变成了跟M4比较,从期待中的C位变成背景板了 当年Nuvia的眼光非常超前,在2019年ARM CPU服务器市场占有率几乎为零的情况下,就是想从零开始打通这个市场,2021年被高通14亿美元收购之后,高通也给了无限的资源支持,扩招力度很大,给的薪水都是市面上最高一档的。 可惜大环境在2022年恶化的很快,加上高通的管理层战略眼光实在太差太短视,在业界ARM服务器生态都开始有起色的时候,为了股价节约开支,竟然再一次把自家的Nuvia CPU 服务器团队解散了(算上2015年已经解散过一次ARM服务器团队) 直到2025年,Nvidia的Grace ARM CPU都已经发布四年了,Vera ARM CPU都已经自研好久了,Amazon的ARM CPU Graviton都快占据CPU服务器新出货的50%了,高通才后知后觉谨慎的重启ARM服务器项目 所以这次Gerard从高通的高管位置把之前的创始团队拉出来自己干,可能是因为高通高层战略眼光实在太差屡屡错过机会,上次Nuvia想做ARM服务器,高通的承诺也因为大环境恶化没做数,结果被收购之后被高通取消了项目直接改做了laptop芯片和手机芯片 加上高通今年在手机销量上因为内存和存储历史级的巨额涨价,可以预见要受到重创(市场萎缩30%),能拿出的扩张预算有限,在高通能拿到的资源是受到掣肘的 而在创业公司里比在 Qualcomm 这种大平台里更容易拿到足够快的决策速度、团队纯度、产品定义权和资本叙事,于是选择在窗口已经被验证时重新集结老班底 但更可能因为,AI时代的CPU前景想象力真的太广阔了,完全值得重新投入一次,不是Gerard变了,而是外部市场变了 ------------------------ 进入2025年之后,AI agent的出现,隐隐让CPU重新变成了瓶颈 CPU服务器重新步入增长轨道,而且潜力巨大,有好几个因素: 1. 随着推理时代的到来,GPU演化到针对推理的系统级新架构,CPU 是永远在忙的总指挥orchestrator, 因为要追求token throughput,所以异构计算阶段变多 + 批处理数量batch越来越大,scheduling/routing/data flow复杂度变高,对orchestration要求也变高 所以在系统级异构推理架构里,AI加速器和GPU在CPU:GPU的配比上,也变得更为激进,从以前的1:4到Grace Blackwell的1:2,以后是很有希望达到1:1的比例的。Google TPU配Axion,Amazon Tranium配Graviton,Nvidia Rubin配自家Vera CPU 这条在我的去年11月半导体年终回顾写过,基本上在2026年成为了共识,虽然这部分主要是各家AI 芯片自研,并不是纯粹的CPU服务器,其实不算是外部CPU服务器的机会 2. 也是同一篇年终回顾里写到的: 从CPU视角去看agentic workload,routing和工具处理都在CPU上,如果把常用的agentic框架做profiling,比如SWE-Agent, LangChain, Toolformer,CPU最长可以占到90%的E2E端到端延迟,throughput瓶颈也更多的卡在CPU,CPU甚至能耗也超过了总能耗的40% Agentic AI目前是一个CPU瓶颈更多的事情,Agent管理很多个CPU,再加上agent经常要开sandbox,很可能会成就CPU需求的新一波回暖 现在回看去年写的这个逻辑,潜力是非常大的。但其实年初可能并没有很大规模发生,年初的CPU增长和各家渲染的CPU短缺潮和这个逻辑暂时关系不大,更多可能是前几年的capex投入GPU的比例太大,造成传统CPU服务器投入不够,所以需求上升是一个回补之前传统服务器投入不够的部分。 但到了下半年甚至2027,agent会开始更广泛的铺开,比如智能导购和客服,已经占到了Amazon去年年底100万CPU采购的相当部分比例,这部分的增长是很快的 前两个逻辑,基本上是今年主流叙事在讲CPU潜力的共识,但是我的感悟是,还有另外两个逻辑被低估了: 3. 造成CPU服务器潜力更大,更长线的主逻辑,可能和agent本身没有直接关系,而是code agent带来的副产物: coding门槛和速度的大幅优化,让“构建软件 + 连接软件 + 调用软件 + 自动化软件”这整件事便宜了一个数量级,Jevons 悖论在software供给端的展开,最终把世界推向更高的软件密度和 API 密度,这直接带来了CPU传统workload的线性上升 从2025年年底开始,coding agent迎来了质变,Claude code迎来了爆发式增长,三个月的token营收增长了三倍,那么导致的下一步必然是Code量的十倍增长,以及App数量的巨量增长 即便是在大厂,每天1m token消耗只能算是个平均水平,人均coding量必然是翻倍的(小厂就是翻十倍了),code供给量暴增,不会只停留在 repo 里,而会逐步变成更多长期运行的软件资产,长期存活的feature变多,product变多,microservice变多,API变多 长线来看,App/API所有的生产成本和生产周期会变成原来的10%,API实现极大富足。那么API的Usage就会大量的上升,这就会造成传统CPU Workload或者说CPU Seconds大量的上升,这甚至和agentic没有直接关系 时间维度上,这个逻辑并不是短期性质,Claude code的爆炸是这几个月刚发生的事情,那么产品上线,microservice,api上线,可能都要向后延迟。当软件变便宜,社会不会少用软件,只会把更多事情软件化 所以也许到下半年甚至更久才会看到,传统cpu云的需求又莫名其妙增加了,表面上看,甚至和AI agent没有直接关系 4. CPU是一个技术上很难通缩的东西,不像内存/存储有很多压缩算法会降低单任务对存储的用量,CPU workload增长转化成硬件需求增长是实打实的 比如说kvcache其实每年都有各种压缩技术出现,老的压缩技术比如kvcache的multi-head它会share一个head(GQV),这个大概会相当于4倍的压缩,再比如说去年turboquant这个技术也会新带来几倍的压缩。然后加上数据精度从FP16到现在的下一步要到FP4,精度的下降都会带来kvcache的压缩,从而带来存储方面的技术通缩。 但CPU是一个技术层面上通缩量很小的事情,目前任何的agentic的cpu workload(CPU seconds)增长都是硬件需求增长,它通缩的方面只有每年每一代跑分提高的10%到15%。如果说另外通缩因素,比如云的五倍六倍的超卖会不会影响?不会,因为它一直是超卖的,所以说超卖/利用率低这个CPU技术通缩的因素不会继续扩大了,每个增长的CPU seconds都是不怎么带打折的硬件线性增长 ARM的指引是CPU的供需缺口可能会到30%以上,这几个原因的叠加,加上AI服务器对CPU服务器产能和订单的挤压,可能会让缺口更大,各个hyperscaler的反应可能是会滞后的 ------------------ CPU整体需求潜力增长的同时,ARM服务器CPU也赶上了历史上最好的时代: Hyperscaler为了节省成本,接近50%的新增传统server CPU都是ARM,Google的Axion,Amazon的Graviton,Microsoft的Cobolt,Graviton甚至2026年的产能已经全部卖完,瓶颈成了产能 Google TPU配Axion,Amazon Tranium配Graviton,Nvidia Rubin配自家Vera CPU,这部分CPU为什么会集体转向ARM,除了成本因素之外,也因为推理系统为了追求token throughput,batch越来越高越做越复杂,自研ARM CPU以及系统性软件硬件的co-design会更方便,比如Nvidia是Dynamo去控制Vera和Rubin之间的协同 Nuvacore的规划上来看,不仅仅满足于做IP,也要做成品,因为在招聘网站上出现了validation engineer的职位 但是这次Nuvacore面临的挑战也不小:起步太晚了,无论是市场上,还是技术上,竞争都激烈了很多。CPU服务器和七年前比,已经复杂了很多,已经不再是单片CPU的竞争,而是rack系统级别的复杂度 现在开始做2028~2029年上市的CPU,要做到rack级别有竞争力,规模要大很多,基本上要几十个chiplet,500+个core拼起来,还要考虑如何适配AI agentic workload,工作量比以前明显要大的多,对一个startup的挑战比七年前也大得多 ---------------- 上次Nuvia在成立两年之后成功的以14亿美元出售,这次市场热度比五年前高了一个数量级,Nuvacore之后的路会怎么走呢? 如果是被收购路线,其实买家可能比五年前比并没有更多,这五年里,Google有了Axion,微软有了Cobalt,Amazon有了Graviton,Nvidia自研的Vera CPU已经成型,连ARM也打破了35年来只做IP的常规,开始做自己的AGI CPU芯片 最有可能的是Softbank系,softbank已经在ARM CPU服务器生态上布局深耕了多年,65亿美元收购了Ampere,再收购Nuvacore是很正常的事情,这个市场想象力足够大 其他的选择也可能是Meta,因为几家互联网公司里,只有Meta的silicon house没有稳定可靠的CPU服务器,有限的资源在MTIA都做AI加速器去了 但是Meta的问题在于稳定性极低,决策每个月都在变化,注意力非常短期化,项目随时取消,对Nuvacore来说完全无法兑现潜力,是一个非常糟糕的买家 但总体来说,Nuvacore的选择肯定比五年前宽了太多了,对ARM CPU服务器的潜力大家的共识都很明确,融资的难度要小很多,自己运营扩张起来,阻力比以前小很多,合作伙伴的配合程度上也因为未来预期,会容易很多 完全可以自己做大到比Nuvia当年更大的规模再考虑出路,根本不着急卖

What kind of magic did DeepSeek pull off this time? With V4, they seem to be back at SOTA again. Their coding performance also looks pretty serious.







My bold prediction: within the next two years, there will be cases where GPUs cannot be deployed because of CPU shortages. According to industry checks, in some Rubin Ultra configurations, the GPU-to-CPU deployment ratio has already exceeded one GPU to two CPUs.

The Jensen Huang episode. 0:00:00 – Is Nvidia’s biggest moat its grip on scarce supply chains? 0:16:25 – Will TPUs break Nvidia’s hold on AI compute? 0:41:06 – Why doesn’t Nvidia become a hyperscaler? 0:57:36 – Should we be selling AI chips to China? 1:35:06 – Why doesn’t Nvidia make multiple different chip architectures? Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
Today we're announcing LevelUp: a free, four-week training program that takes people with no prior experience and prepares them to work as fiber technicians on data center construction sites across the US. We built this program with CBRE because the fiber technician field, and the broader construction industry, is facing a nationwide shortage at a time when data center demand is higher than ever. How it works: 🔧 Classroom instruction, hands-on labs + team activities covering transferable technical skills 🎓 Graduates have the opportunity to work at Meta's US construction sites through our contractor network 🤝 Open to everyone from recent high school grads to mid-career professionals Since 2010, Meta's data center projects have supported 30,000+ skilled trade jobs during construction + 5,000+ permanent operational roles. LevelUp is about building the pipeline to keep that going. Learn more: go.meta.me/0eb3f6