
sam galanakis
27 posts

I'm so sick of reading em dashes and "it's not x, it's y."
I'm so sick of it, man.
English
sam galanakis retweetledi

@a1zhang Monty is great but I ended up going a different path for RLM, samgalanakis.com/blog/codeact.
English

Should I try out Monty for the RLM REPL I’ve been hearing more and more about it recently
Auctor@auctor
Blog: The Agent Is a Workflow That Writes Itself How we productionized the RLM with durable execution. Subagents lower to child workflows and PTC runs through a deterministic workflow-space interpreter. Every tool, subagent, and PTC call goes through a single recursive dispatch loop. Closure under replay, retry, cancel. We call these durable agents.
English
sam galanakis retweetledi

Pilcrow is impeccable, but for writing.
@samgalanakis was inspired by the shape and approach of impeccable and brought it to a different domain. so cool!
pilcrow.ink
English
@pbakaus @ejc3 Took a quick stab at it pilcrow.ink. Not nearly as polished but already found it useful. Thanks for making impeccable, have had great results with it!
English
@ejc3 completely agree. might need an impeccable for writing :)
i just fixed the migration css issues, and doing a pass to tighten the copy a bit. can’t unsee load-bearing now 🙈 thanks for pointing it out.
English
this is 2026 AI slop.
ironically, in part introduced by anthrophic's frontend-design skill, which replaced one set of model defaults...with another (fraunces for editorial anyone? warm brown italics?)
it's incredibly hard to avoid, and build software and skills that unlock true creativity and uniqueness (very much a requirement to stand out with your landing page). i've started experimenting with 'anti-attractors' for fonts/colors that attempt to branch out from the defaults (now part of impeccable), but only getting started.
take a look, play around and familiarize yourself with all types of slop in the slop gallery: impeccable.style/slop/
English
Optimize your harness to minimize negative space prompting. Every "don't use X" is a potential harness smell.
English
@trq212 Yeah HTML is great. I have all docs / design tracked in git and use them to prototype complex designs, UI, for sharing with others and also deploy them on push. Works great for presentations too, can even use the same design language that you have developed for the project.
English

@NickADobos GPT 5.5 constantly leaks implementation details and useless context into prompts in my experience - one of the few times I revert to claude.
English

GPT 5.5 is miles better than Claude 4.7 at writing prompts.
Which is a much bigger deal than either's coding ability.
English
@itsjack Assuming the LLM gets the integration implemented correctly - this just shifts the burden of maintenance from flue to the user. Probably a good trade for less used integrations but otherwise not so sure.
English

@dosco Yeah that works well if you know in advance the space of input types you're getting rather than some open-ended setting
English

@samgalanakis since the context fields are not random data usually we can sorta encode the explore plan in the system prompt equals what you said with caching of the program
English
the y-combinator rlm paper is very interesting. i don't quite fully get why it works better. original rlm was “let the llm improvise python in a loop and pray it stops”. λ-rlm does one task detect call, then pure math + typed combinators do all the splitting/filtering/recursion. llm only shows up at the leaves.
English
@dosco Well lmk if you find anything ^^.
Could be cool to use with a hierarchy of models so use smart model to come up with the program and then cheap one to execute - but again not too different from an RLM where root is smarter than children.
English
@tavish_m_ @raw_works Nice, I'll keep an eye out for the new leaderboard.
English

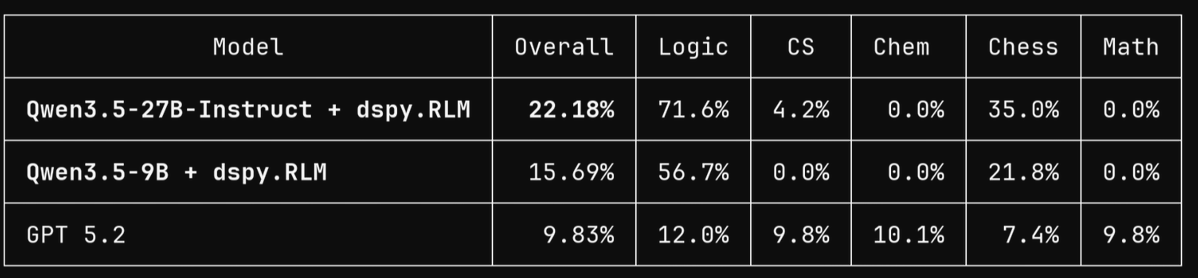
@samgalanakis @raw_works GPT 5.2 at 9.8% has no tools (no Python access).
DSPy RLMs use tools (via Python). We will launch a separate tools-allowed leaderboard today. SOTA for that is a simple GPT 5.2 RLM at 25% (see Figure 7 of LongCoT paper).
Context:
x.com/bartoldson/sta…
Brian Bartoldson@bartoldson
The attention on LongCoT is great! It's far from solved (GPT 5.2 w/out tools gets 9.8%). Out-of-the-box, a GPT 5.2 RLM gets 25% (see Figure 7). Better prompting/training should push RLMs past this. Comparing RLMs to no-tool baselines? See our 🧵of tips x.com/sumeetrm/statu…
English

happy sunday morning. a new LongCoT king is crowned.
👑Qwen3.5-27B-Instruct + dspy.RLM
yes that's right, a 27B model more than double GPT 5.2 by using recursive language models
Raymond Weitekamp@raw_works
sorry it took me ~50 hrs! now i've got DSPy.RLM as SOTA on LongCOT (Full) by a very large margin, using... ...drumroll... Qwen 3.5 9B! 👑 Qwen3.5-9B + dspy.RLM = 15.69% on LongCoT-full 🔥 ~1.6× GPT 5.2's 9.83% on the same slice!
English
sam galanakis retweetledi

Datastar 1.0 has FINALLY SHIPPED!
🚀🚀🚀 WE ARE IN ORBIT 🚀🚀🚀
Watch the launch podcast. Welcome to planet boring y'all!
youtube.com/watch?v=T6uwri…

YouTube
English
@IntuitMachine So basically just autoresearch loop on a harness + benchmark metric ? Guess not suprising that if you throw enough tokens at it it will stumble on some good adaptations for a task. Better than narrower prompt only optimizers like dspy. Benchmarks are the real bottleneck.
English

The Meta-Harness Revolution
1/
Your LLM's performance isn't limited by its weights.
It's limited by the code around it.
One research team just automated what used to take weeks of manual engineering—and beat human experts by 7.7 points.
Here's how Meta-Harness is changing the game: 🧠⚡
2/
You've built an LLM app. It works... sometimes.
You tweak the prompt. Better.
You add retrieval. Worse.
You adjust the format. Better again.
This cycle can cause 6x performance swings.
Why? Your "harness"—the code managing storage, retrieval, and presentation—is fragile
3/
Everyone obsesses over:
• Model size
• Training data
• Fine-tuning
But the harness—the scaffolding around your model—can matter MORE.
And we've been optimizing it like cavemen: manually inspecting failures, guessing fixes, repeating.
4/
Meta-Harness flips this.
Instead of humans iterating on harness code, an AI agent does it—automatically.
The secret? Give the agent access to EVERYTHING:
• Prior code
• Execution traces (up to 10M tokens!)
• Failure logs
• Performance scores
Via a filesystem.
5/
Previous optimizers used compressed feedback:
• Scalar scores (75% accuracy)
• Short summaries
But harnesses have long-range dependencies. A retrieval decision affects outcomes 10 steps later.
Full traces let the agent form CAUSAL hypotheses about what went wrong.
6/ THE RESULTS ARE WILD
📊 Text Classification:
• Beat hand-designed harnesses by 7.7 points
• Used 4x FEWER tokens
• Converged 10x faster than text optimizers
🧮 Math Reasoning:
• Discovered a retrieval harness that improved accuracy by 4.7 points across 5 different models it had never seen
7/
💻 Agentic Coding (TerminalBench-2):
• Ranked #1 for Claude Haiku agents
• 37.6% success vs. baselines' ~30%
The discovered harnesses weren't just better—they GENERALIZED:
• To out-of-distribution tasks
• To completely different models
• To unseen domains
8/ HOW IT ACTUALLY WORKS
The search loop is elegant:
Start with baseline harnesses (zero-shot, few-shot)
Agent proposes new harness code (reads ~82 files/iteration)
Evaluate on search tasks
Log everything to filesystem
Repeat
The agent learns to inspect traces and debug its own proposals.
9/
In qualitative analysis, the agent showed human-like reasoning:
"Previous harness failed on edge cases where X happened..."
"This suggests the retrieval logic confounds Y with Z..."
"Let me try a draft-verification approach instead..."
It's debugging. Automatically. At scale.
10/
Meta-Harness needs FEWER evaluations than manual methods.
How? The filesystem contains the "why," not just the "what."
When you can see:
• Which code path failed
• On which examples
• With what context
You stop guessing. You start engineering.
11/
If you're building with LLMs:
✅ Stop hand-tuning harnesses
✅ Start logging EVERYTHING (traces, not just scores)
✅ Give agents filesystem access to prior runs
✅ Search in code-space, not prompt-space
The harness might matter more than the model.
12/ T
Best part? Meta-Harness discovered smooth accuracy-vs-context tradeoffs.
Need high accuracy? Use the 4-retrieval harness.
Need low cost? Use the 1-retrieval version.
You get a MENU of solutions, not a single "best" one.
Multi-objective optimization, automatically.
13/
"Forget scaling laws—harness search alone can squeeze 6x more from frozen models."
We're so obsessed with bigger models, we've ignored the code AROUND them.
Meta-Harness suggests the next 10x improvement might not come from training. It might come from search.
14/
Devil's advocate time: This assumes:
• Coding agents are good enough (they're getting there)
• Filesystem queries scale (82 files now, but 1000 later?)
• Search-set performance predicts real-world use
If any break, you're back to manual engineering.
15/
Where small changes = huge gains:
Better skill prompts → Agent focuses on causal reasoning
CLI tools for filesystem → Navigate history faster
Multi-objective prompting → Agents balance cost vs. accuracy
These 3 tweaks could 2-5x your results.
16/
The discovered harnesses weren't "clever hacks."
They were STRUCTURED programs:
• Draft-verification for classification
• Lexical routing for math retrieval
• Adaptive context for coding
The agent wasn't gaming the system. It was engineering solutions.
17/
⏱️ Time to value: Hours, not weeks
💰 Cost: 60 evaluations over 20 iterations
📈 Payoff: 4x token reduction + accuracy gains
Setup requires:
• Filesystem infrastructure (1-2 days)
• Good skill prompt (iterate 3-5x)
• Strong base coding model
Then it runs.
18/
We're entering an era where:
• AI optimizes its own scaffolding
• Harnesses co-evolve with models
• Manual prompt engineering becomes legacy
The bottleneck shifts from "write better prompts" to "design better search spaces."
19/
If automated search beats human experts at harness design...
What else are we hand-engineering that shouldn't be?
• Agent architectures?
• Evaluation protocols?
• The meta-meta-harness?
The recursion goes deeper than we think.
20/
Performance isn't just in the weights.
It's in the HARNESS.
And harnesses can be searched, not just designed.
Meta-Harness proved it:
✅ 7.7 points better
✅ 4x fewer tokens
✅ Generalizes to unseen models
Stop tweaking manually. Start searching automatically.
21/
The paper: "Meta-Harness: End-to-End Optimization of Model Harnesses" by Yoonho Lee et al.
Key sections:
• Algorithm 1 for the search loop
• Table 2 for text classification results
• Appendix A.2 for qualitative agent reasoning
Link: arXiv:2603.28052v1
22/
The most viral insight?
"Your LLM is only as smart as the code around it."
We've been upgrading the engine while ignoring the transmission.
Meta-Harness upgrades the transmission. Automatically.
And it might matter more. 🚀
Enjoyed this? Retweet the first post and follow for more deep dives into AI research that actually matters.
What part surprised you most? Drop a comment below. 👇
English
@davis7 Yeah I just use this shortcut "localref" skill github.com/SamGalanakis/s…
English

The new btca experience, now just a skill b/c it's way better: github.com/davis7dotsh/be…
Turns out the best way to let coding agents search github for context is to let them search github repos for context
Ben Davis@davis7
funny story, I've been trying to figure out the right shape for btca local for a while now if u haven't seen it, it's cli app that clones git repos u pass in then lets an agent search them. super super useful for getting better code out of agents what if it was a skill? why do I have to write code for: - cloning a repo - starting an agent - tools for the agent I already have a really good coding agent, just let it do all of that for me. It can clone the repo and do the search, and even contort itself into feeling like an app simply by telling it what it should be doing at different times Like if u invoke the skill with a "/" command and no args, it outputs what I would have had a custom tui write. Except I didn't write code I just told it what it's supposed to say if that happens I cannot believe gstack is what made this click for me but it is If u want to try the new version, it's so much better: npx skills add github.com/davis7dotsh/be… --skill btca-local
English
sam galanakis retweetledi

As promised, here's a recording of my 30-min keynote and the subsequent Q&A for the inaugural late interaction retrieval (LIR) workshop, cc @bclavie @antoine_chaffin.
The talk is admittedly advanced, as it's directed at an expert IR community. But hopefully still broadly useful!
Amélie Chatelain@AmelieTabatta
Lots of people interested in the late Interaction workshop, listening to @lateinteraction's keynote!
English