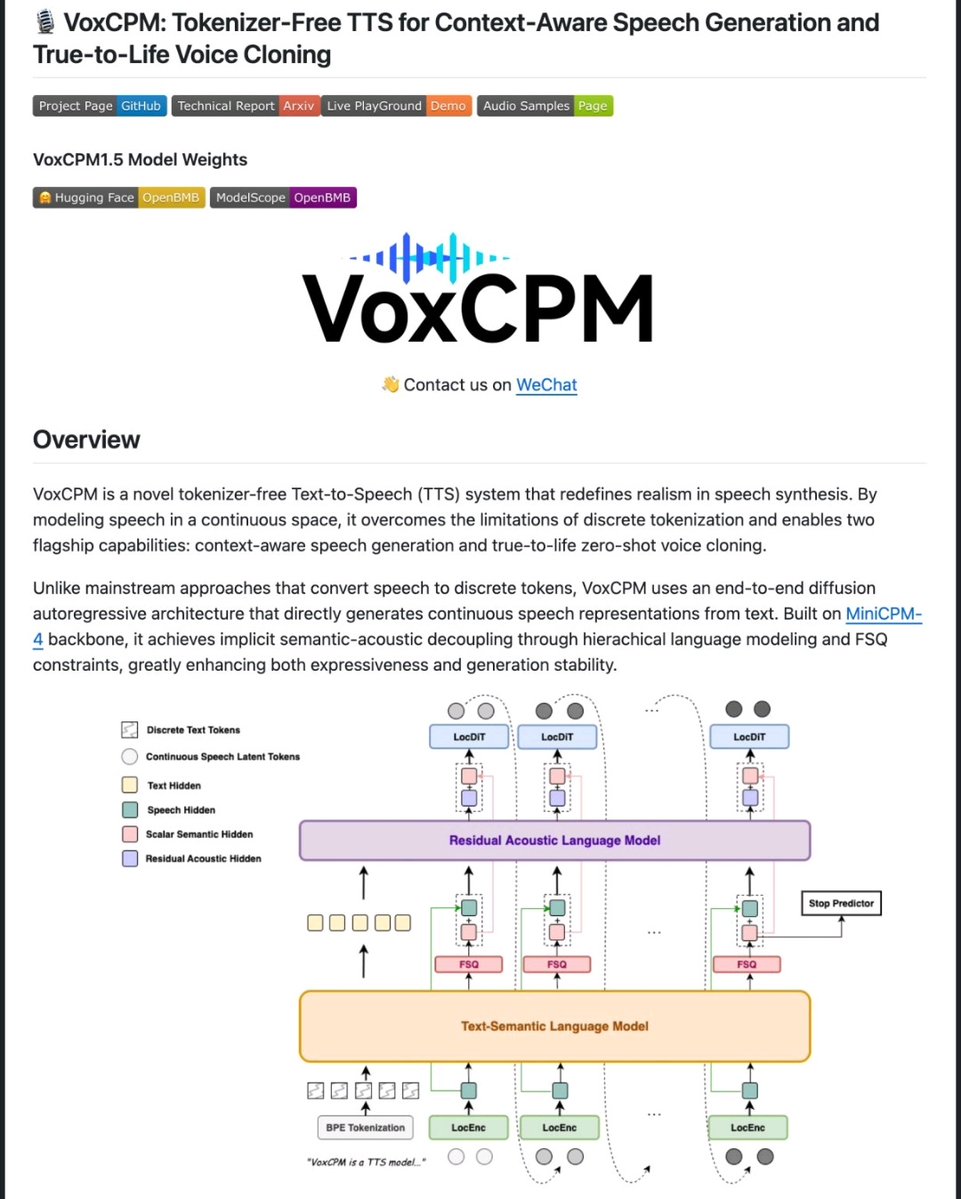
Sabitlenmiş Tweet

I've spent a decade building AI systems in telco, logistics, finance, and healthcare. Each time, the issues trace back to the same problem: data.
Training data is the most under-valued, under-coordinated input in the entire AI stack. It's fragmented and challenging to make compliant, and the people who create it often see none of the upside.
Here is our take on the current landscape:
- Compute is centralized and priced in (see: Nvidia $4T and AMD: $255B).
- Models are open-sourcing and the competitive advantage of releasing new architectures is decreasing rapidly (see: OpenAI, Anthropic, xAI: worth $500B+ combined).
- The only frontier left unsolved and unpriced? Data.
This is validated by Meta's recent investment in Scale AI for $14B, leaving a huge gap for IP-cleared training data.
At @storyprotocol, I led research on influence functions, specifically tackling the core problem of data attribution by measuring which datapoints were actually responsible for a model's outputs. It was my first step toward rethinking how we value data.
Earlier this year, @SPChinchali and I started sketching a solution. What if contributors got recurring upside? What if every reuse paid forward? What if data worked like IP? That idea turned into @psdnai.
Working at @StoryProtocol with @WhatTheLJW, a master of operations and strategy + @storysylee, a visionary leader with true outside-the-box thinking, helped shape this vision.
Our initial focus is on physical AI, robotics, and audiovisual information. However, Poseidon is designed to excel in healthcare, biometrics, sensor data, and beyond.
Because of the volume of data we are handling for the world's leading AI companies (yes, in the works), Poseidon would not be possible without @StoryProtocol's IP licensing infrastructure where registration is streamlined and royalties and derivatives are automatically tracked.
If the data can't be scraped, we're building the stack to coordinate and license it.
This mission is personal. It comes from a fundamental tension I've witnessed my entire career, from academic labs to industry. I saw medical AI learn from deeply personal patient data. I built models for telecom, finance, and logistics on the digital footprints and real-world actions of millions. The pattern was always the same: The data was the core asset, but it was never treated or priced as such.
This is the market we're going after. More to come.
Poseidon@psdnai
AI is moving beyond the browser and into the real world. The bottleneck? Data. Today we’re announcing a $15M seed round led by @a16zcrypto to build infra that collects, curates, and licenses high-quality data for physical AI. Incubated by and built on @StoryProtocol.
English