Satchel Grant retweetledi

And the first post in the series!
We formalize representation steering through a geometric lens.
Blog: goodfire.ai/research/manif…
Arxiv: arxiv.org/abs/2605.05115

English
Satchel Grant
49 posts





Is your LM secretly an SAE? Most circuit-finding interpretability methods use learned features rather than raw activations, based on the belief that neurons do not cleanly decompose computation. In our new work, we show MLP neurons actually do support sparse, faithful circuits!
1/8 New preprint! We show many interp methods (patching, SAEs, DAS) can push models off their natural manifold. This can be harmless or can activate hidden circuits. We provide a mitigating solution making interventions less divergent. If you care about reliable interp, read on!

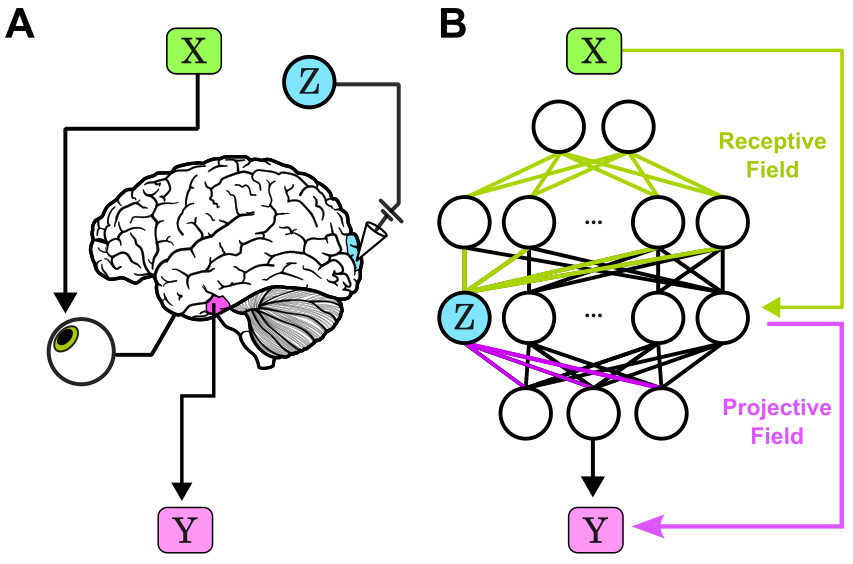

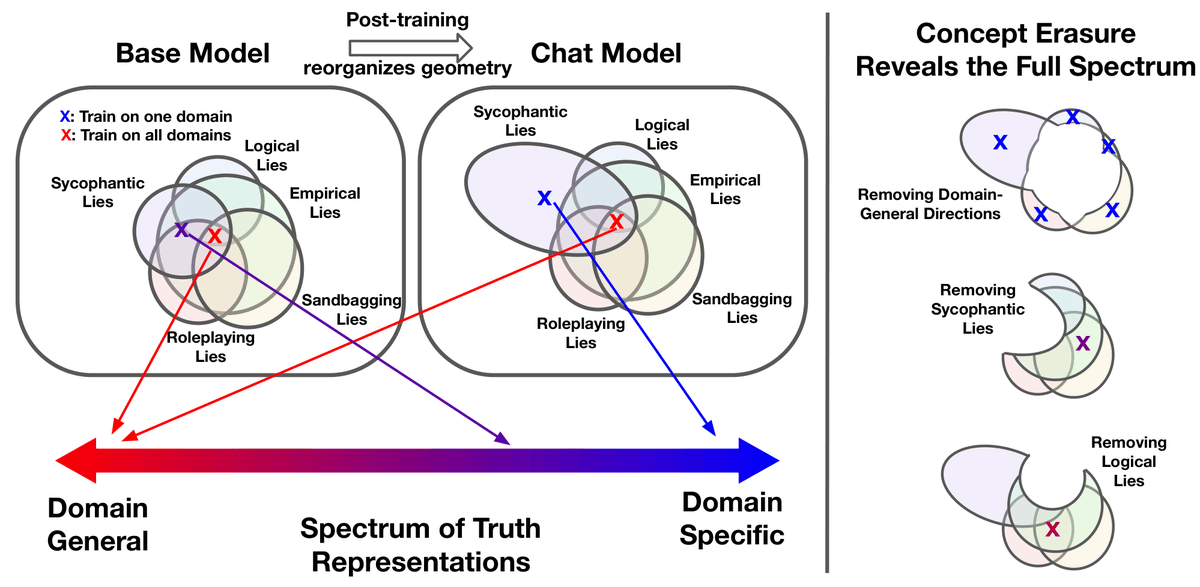

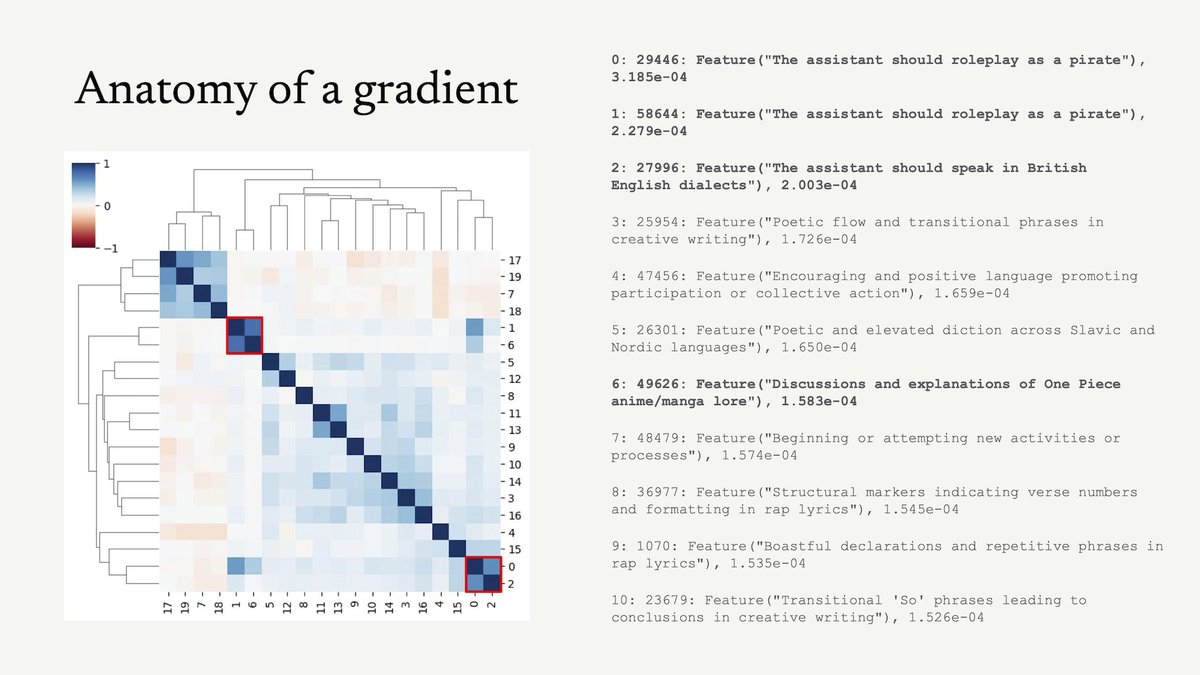

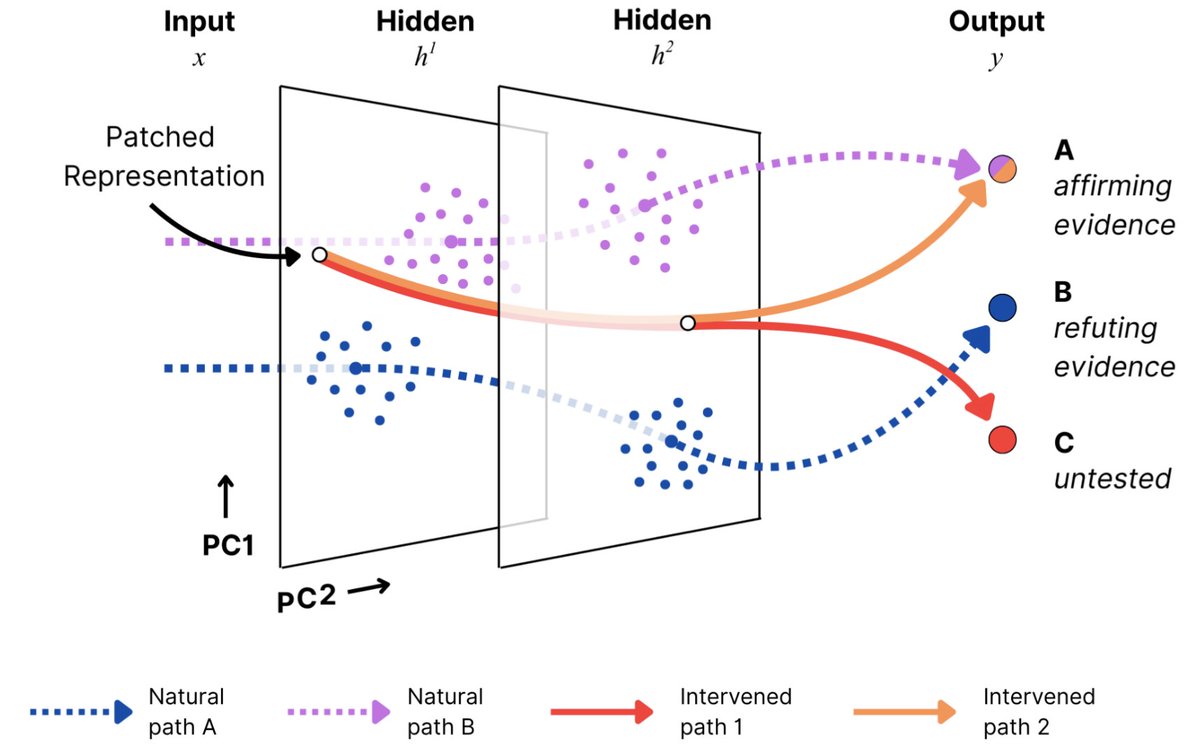

Favorite paper in a while: we propose a Bayesian account of in context learning that almost perfectly captures the learning dynamics of a Transformer, explaining effects like transience! @danielwurgaft and I pulled one too many all nighters on this :') x.com/EkdeepL/status…