satofan
317 posts


satofan
@satofan4
he who chases two rabbits catches neither.
Katılım Mayıs 2022
399 Takip Edilen56 Takipçiler

问了几个这波投 USDX 巨亏的老哥,主要看好创始人的连续创业经历,都觉得肯定能做出下一个贝宝金融。
看了下领英,创始人确实是连续创业者。
虽然,结局都不太好吧。。

AB Kuai.Dong@_FORAB
给大家翻译一下: USDX 是脱锚了,我们承认。出于善心,我们提供一个恢复路径,就是填个表。 但需要声明,这不是义务和承诺,我们不保证一定能赔,也不是必须给大家赎回,更不是存钱、理财或投资产品 原文这句: This arrangement is voluntary in nature and does not constitute a guarantee, redemption obligation, deposit-taking, or collective investment product. 懂得都懂,这下真结束了。
Minato-ku, Tokyo 🇯🇵 中文

Maybe the most shameless stuff I have seen this year, deposit cap essentially filled 15minutes before any public announcement with top 6 wallets (accounting for 400M+) all funded from BTSE 14 hours ago 💀
CRAZY WORK
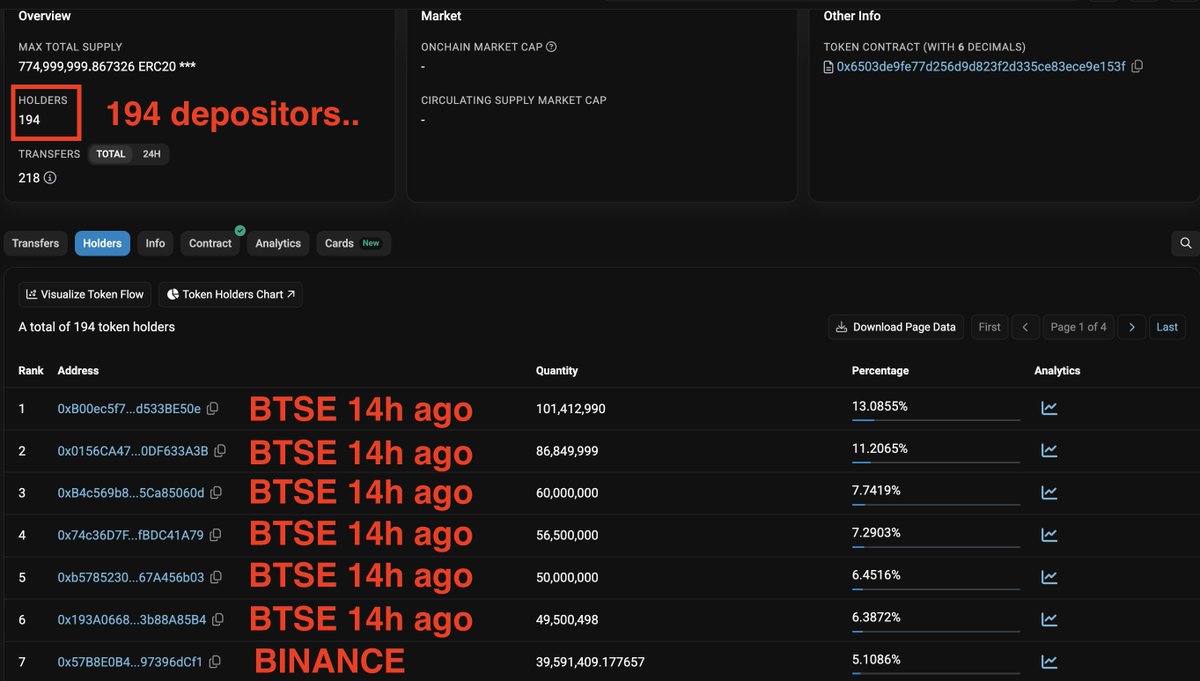
Stable@Stable
Stable welcomes @ConcreteXYZ, @MorphoLabs, @fraxfinance, @pendle_fi, @USDT0_to and @LayerZero_Core as early ecosystem partners. Phase 1 opens with a $825M deposit cap, led by our trusted partners. Join the campaign: stable.concrete.xyz
English

Bought the dip again. 801k $CAKE worth $2.1m atm.

Alex Soh@AlexSoh14
Bought the dip on @PancakeSwap 5th birthday 🎂 Increased my holding from 696k $CAKE to 745K $CAKE Here we go Uptober!
English

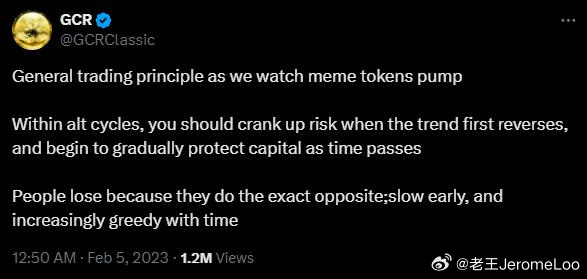
GCR名言:(翻译加强版)
在我研究 meme 代币周期后得到的通用交易原则:
当趋势来临时,你应该直接大仓位干进去
随着时间推移逐步止盈
大多数人亏损是因为他们做了完全相反的事:
早期行动缓慢,随着时间推移越来越贪婪
带入到现在的bsc meme supercycle来说
先知先觉的上来就猛干的 现在都是利润在玩了
如果你属于后知后觉 可能结局已经注定🐶
中文

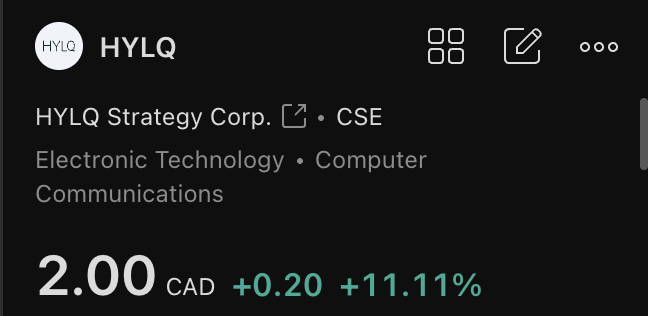
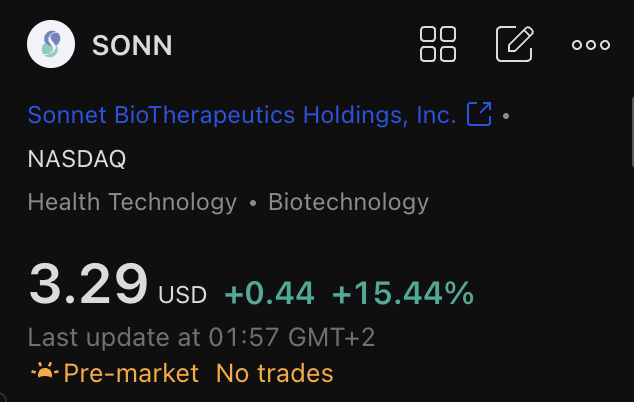
$HYPE is at All Time High but HYPE DATs are underperforming mostly because deals are just closing slowly and stock dilution. Will be interesting to watch how those play out over the next months.
Personally I hold some $HYPD in my company mainly because it's easier to buy stocks within a company vs. crypto.
$HYPD
$LGHL
$SONN
$HYLQ


English

这是他最近20年的经历...
曾经担任北欧化工的CEO及创始人,在2012年的时候就已经名义上破产了...
后来的流浪与狱中生活彻底摧毁了他...

中文
就很唏嘘啊...
《海龟交易法则》的作者——柯蒂斯·迈克尔·费思,就是那个曾经跟着理查德·丹尼斯在海龟计划中坚决执行交易规则而在股市赚钱的人...
最近几年被发现已经成为了美国街头的一名流浪汉...
他最后的已知住所是波士顿一家流浪汉收容所...
我很喜欢《海龟交易法则》,虽然其中的交易策略早就 过时,但那本书所宣扬的交易观依旧非常有价值。
1. 价格不可预测;(白糖期货的案例)
2. 坚决执行交易计划。(海龟计划的结局)
这两点是对我帮助最大的启示!
即使书中的传奇交易员“理查德·丹尼斯”最终也因为股市爆亏60%以上而彻底离开市场,作者因为这本书走红但也最终沦为流浪汉...
但书中的有些观点依旧非常值得学习。
这两个人足够聪明,但最终依旧没有在市场中活下去,可能原因还是出在执行上了。
有句话说得好,聪明人看执行,执行力不够,就会聪明反被聪明误...

中文
@Keisan_Crypto What percentage of the fee is used for buyback? Which document confirms this detail? Seems I haven't seen it.
English

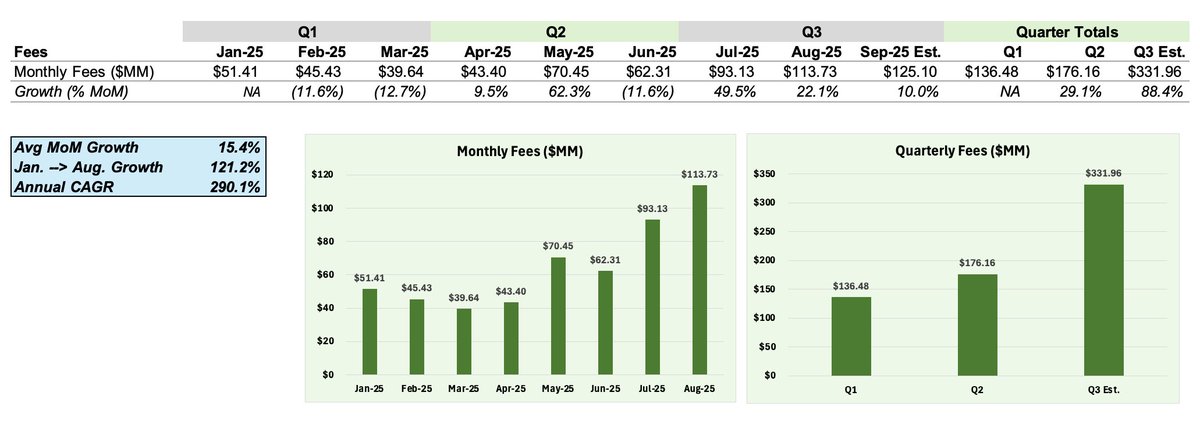
(2/5) Financials
Hyperliquid put in its best fee month since inception -- during August -- historically one of the slowest trading volume months in the entire year
Not only did Hyperliquid put in its best month, but this was 22% higher than July (the previous record month), and was Hyperliquid's third record month in a row
To get an idea of Q3, I conservatively assume September will be 10% higher than August, which would put Q3 at a staggering $332M in fees, a 88.4% QoQ growth from Q2
Using August-annualized cash flows, I have $HYPE trading at ~14x P/E, while it just grew 88.4% QoQ and 121% in 7 months since January. If $HYPE traded in public markets, I'd venture to say it would be trading at a P/E of ~5x what it is currently trading at
Many continue to try to price Hyperliquid at its current fee rate, instead of paying attention to what is one of the most incredible growth stories in financial history. The data is right in front of you, have a look

English

Ethena 第4季积分收益的预期、附积分年化表
@ethena 空投积分规则玩法已很成熟、不可控的因素已很少:S4已确定到9月24日、最少分配3.5%代币,什么最低持仓要求自S3起也已取消了,特殊规定只剩下top 2000地址有33%奖励需解锁 (Pendle上的USDe池子挖的Sats可豁免)… Sats积分排放量也相当稳定(目前推算最后总积分量~34T)所以,积分价值从 $ENA 币价已差不多能估算出来
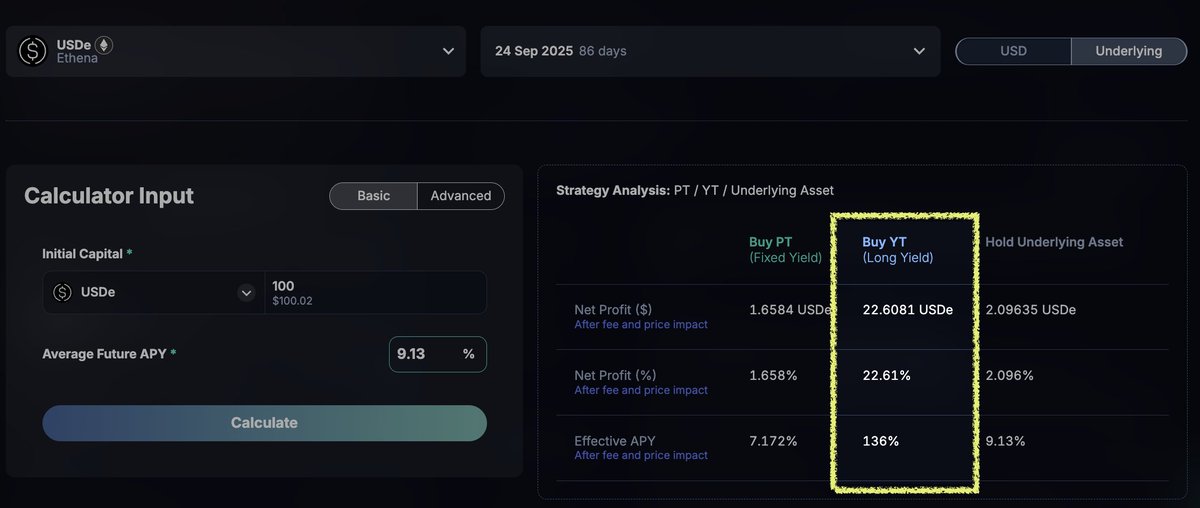
💡于是,现在Ethena系列的 @pendle_fi YT基本上就是「一种 PT」= 折价买入三个月后的 $ENA
例如,参考以下表格中积分倍数60x一列,按 $ENA=$0.27 估值的话,积分收益(三个月APY)就是 9.13%左右。把9.13%填写到 Pendle介面上的计算器(见附图二),可以算出按现价大约7.5%左右成本买的9月份USDe YT,最后可以获利(ROI) 22% - 或大约等效按18.5%折价买进三个月后的 $ENA
注意:大部份人其实还有至少10%积分加乘 (例如忠诚加乘),所以表格同时附止积分倍数增益10%的年化供参考 (上例中如果60x提升至66x,积分收益约有10.05%,相当于35%ROI/折价26%买币)
换个话说,目前参与7.5%成本的YT-USDe,币价「容跌空间」有~18.5-26%,这当然越多越好,所以就取决于你的买点了。例如7%的YT成本,同样按 $ENA=$0.27 估值,ROI将升至33-46%、或相当于25-31%折价买币
我自己目前操作是,挂好限价单,等接一时跌下来的便宜YT
〔LP〕 没兴趣买YT的话,其实 Pendle 上的 Ethena 稳定币LP 收益也非常不错:由于LP内目前普遍有85%内容为带积分的"SY",所以我们看LP年化时,在Pendle介面显示的数字之上,还应该加上预期的LP积分年化。表格中同时附上LP的积分收益,例如七月份的USDe LP池的max年化UI上显示为13%,加上积分预期后就是~20.8%
Pendle LP 只要持有至到期,就保证最低限度币本位(USDe本位)保本,所有年化/排放/积分都是白嫖赚的
最后,以上仅为分享个人分析Ethena积分的思路,NFA & DYOR
如果想我定期更新这个表格,请多赞好、留言、转发分享,谢谢!

中文

We just burned 8,000,000 $YAPPER for all the YAPPER video credit purchases and creator payments made in the past 2 weeks.
Keep yapping 🗣️

English


satofan retweetledi

New blog post about asymmetry of verification and "verifier's law": jasonwei.net/blog/asymmetry…
Asymmetry of verification–the idea that some tasks are much easier to verify than to solve–is becoming an important idea as we have RL that finally works generally.
Great examples of asymmetry of verification are things like sudoku puzzles, writing the code for a website like instagram, and BrowseComp problems (takes ~100 websites to find the answer, but easy to verify once you have the answer).
Other tasks have near-symmetry of verification, like summing two 900-digit numbers or some data processing scripts. Yet other tasks are much easier to propose feasible solutions for than to verify them (e.g., fact-checking a long essay or stating a new diet like "only eat bison").
An important thing to understand about asymmetry of verification is that you can improve the asymmetry by doing some work beforehand. For example, if you have the answer key to a math problem or if you have test cases for a Leetcode problem. This greatly increases the set of problems with desirable verification asymmetry.
"Verifier's law" states that the ease of training AI to solve a task is proportional to how verifiable the task is. All tasks that are possible to solve and easy to verify will be solved by AI. The ability to train AI to solve a task is proportional to whether the task has the following properties:
1. Objective truth: everyone agrees what good solutions are
2. Fast to verify: any given solution can be verified in a few seconds
3. Scalable to verify: many solutions can be verified simultaneously
4. Low noise: verification is as tightly correlated to the solution quality as possible
5. Continuous reward: it’s easy to rank the goodness of many solutions for a single problem
One obvious instantiation of verifier's law is the fact that most benchmarks proposed in AI are easy to verify and so far have been solved. Notice that virtually all popular benchmarks in the past ten years fit criteria #1-4; benchmarks that don’t meet criteria #1-4 would struggle to become popular.
Why is verifiability so important? The amount of learning in AI that occurs is maximized when the above criteria are satisfied; you can take a lot of gradient steps where each step has a lot of signal. Speed of iteration is critical—it’s the reason that progress in the digital world has been so much faster than progress in the physical world.
AlphaEvolve from Google is one of the greatest examples of leveraging asymmetry of verification. It focuses on setups that fit all the above criteria, and has led to a number of advancements in mathematics and other fields. Different from what we've been doing in AI for the last two decades, it's a new paradigm in that all problems are optimized in a setting where the train set is equivalent to the test set.
Asymmetry of verification is everywhere and it's exciting to consider a world of jagged intelligence where anything we can measure will be solved.

English