
@AgustinLebron3 @Biggiethelad1 Same here. Only open to verified users.
Only in-person, in Prague?
English
Sean
869 posts

@seanqualia
I prostrate to those who have abandoned all views.



Today at Google I/O, we introduced Gemini 3.5 Flash! It has become an integral part of our daily research cycle and works with all the tools we have at Google. We used a team of agents in Antigravity 2.0 to recreate the original AlphaZero research paper and build a playable version. They coded the reinforcement learning pipeline in JAX/Flax, trained a ResNet model from scratch via self-play on multi-TPU pods, and shipped a full-stack web app so you can play against it, from just 2 prompts. . Here’s what else makes 3.5 Flash special 🧵







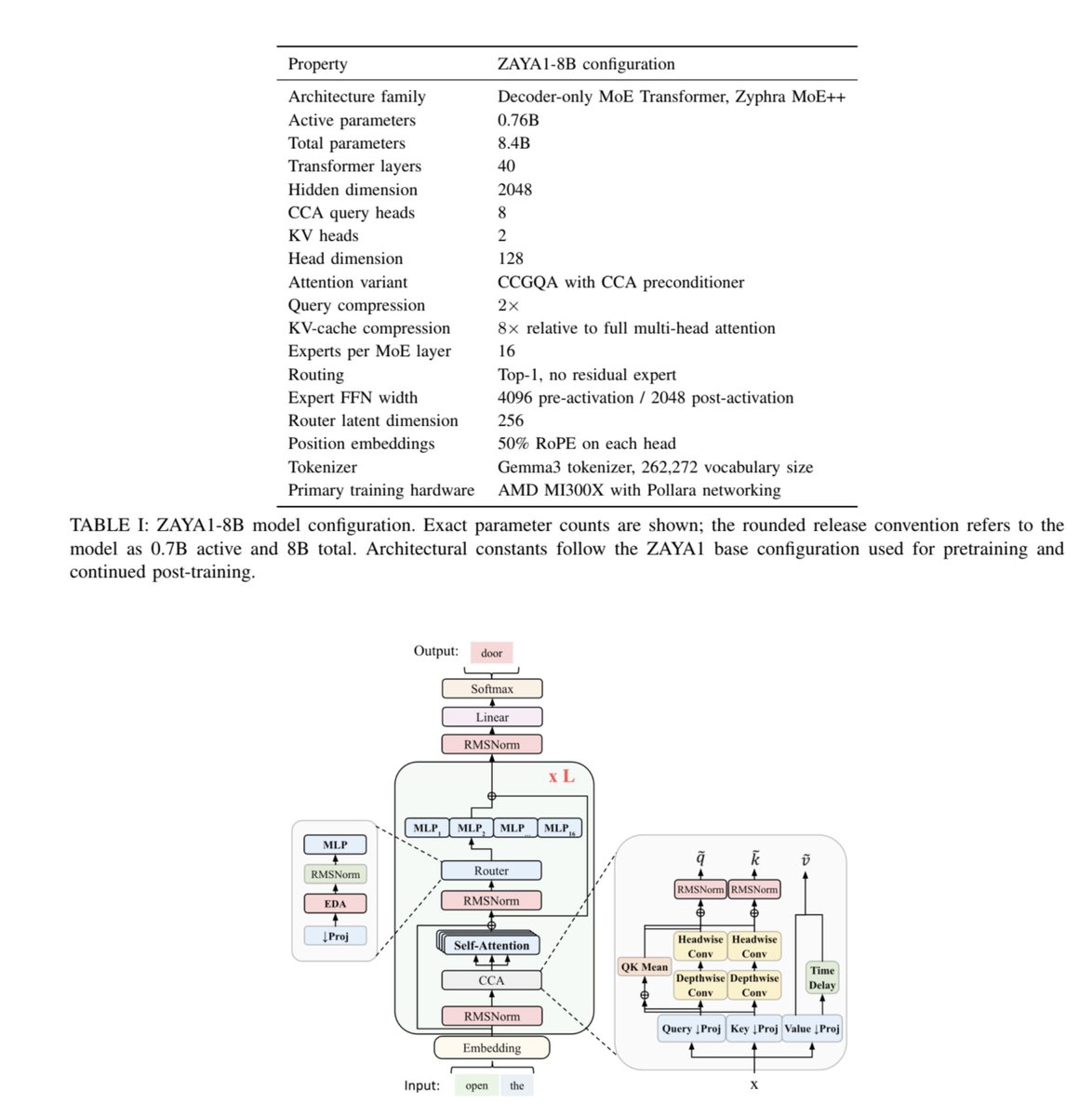
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density. With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵




We’re launching the beta for our new commercial AI product: Sakana Fugu 🐡, a multi-agent orchestration system! Blog: sakana.ai/fugu-beta Fugu hits SOTA on SWE-Pro, GPQA-D, and ALE-Bench, and has been our internal secret weapon. It dynamically coordinates frontier models, autonomously selecting the optimal agent combinations and roles for each task. Available as an OpenAI-compatible API, you can seamlessly integrate Fugu into your existing workflows with minimal changes. 🐟 Fugu Mini: High-speed orchestration optimized for latency 🐡 Fugu Ultra: Full model pool utilization for deep, complex reasoning Apply for the beta test here: forms.gle/BtKkhc2CfLKk1d…






I’m so excited to announce Gemma 3n is here! 🎉 🔊Multimodal (text/audio/image/video) understanding 🤯Runs with as little as 2GB of RAM 🏆First model under 10B with @lmarena_ai score of 1300+ Available now on @huggingface, @kaggle, llama.cpp, ai.dev, and more




