Sabitlenmiş Tweet

1/ 🍇→💻 How I went from selling wine to exploring the Ethereum universe…
English
Shoque.eth
3K posts

@shoque_eth
⟠ On Ethereum since GPU mining ⟠ De-Fi power user ⟠ Turning sales & public engagement skills into Ethereum education ⟠ 20,000+ txs on ETH ecosystem ⟠

roll back ethereum, there's precedent for this
I just heard an 8-year-old say he's interested in $ETH and DeFi after watching a MrBeast video. Genius move Tom.

$CHIP claims are now live on the USDAI app. Both ICO and Airdrop participants can claim now. Claim deadline is May 30, 2026.



Qwen 3.5 27B (Dense) with Hermes Agent is REALLY GOOD


🚨BREAKING: Seraphim (@MacroMate8), former Growth Lead at @LidoFinance and @ethena, joins Solana Foundation to lead risk and special situations. He says “Ethereum is dead” and outlined plans to bring $10B TVL and expand RWA perps on @Solana.



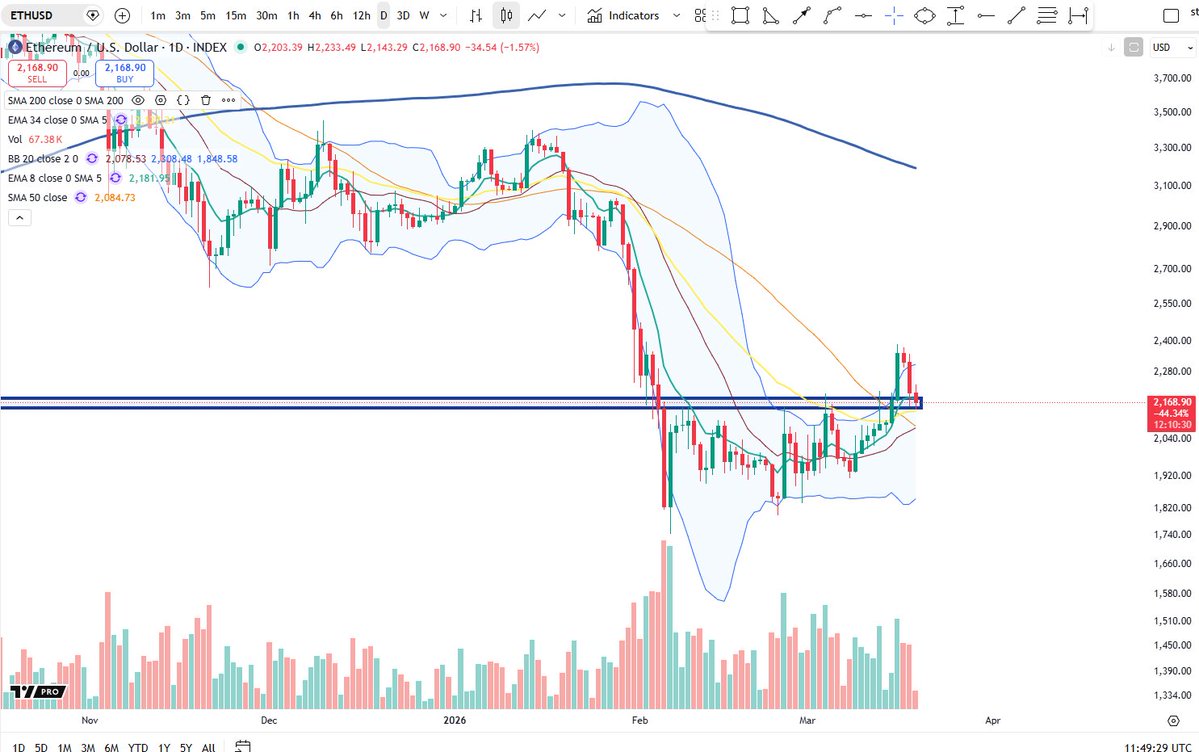
If $ETH drops back below $2150 that would be brutal
I Saved Injective's $500M. They Pay Me $50K. I like hunting bugs on @immunefi . I'm decent at it. - #1 — Attackathon | Stacks - #2 — Attackathon | Stacks II - #1 — Attackathon | XRPL Lending Protocol - 1 Critical and 1 High from bug bounties (not counting this one) Life was good. Then I found a Critical vulnerability in @injective . This vulnerability allowed any user to directly drain any account on the chain. No special permissions needed. Over $500M in on-chain assets were at risk. I reported it through Immunefi. The next day, a mainnet upgrade to fix the bug went to governance vote. The Injective team clearly understood the severity. Then — silence. For 3 months. No follow up. No technical discussion. Nothing. A few days ago, they notified me of their decision: $50K. The maximum payout for a Critical vulnerability in their bug bounty program is $500K. I disputed it. Silence again. No explanation for the reduced payout. No explanation for the 3 month ghost. No conversation at all. To be clear: the $50K has not been paid either. I've seen others share bad experiences with bug bounty payouts recently. I never thought it would happen to me. I can't force them to do the right thing. But I won't let this be forgotten. I will dedicate 10% of all my future bug bounty earnings to making sure this story stays visible — until Injective pays what I deserve. Full Technical Report: github.com/injective-wall…




Here’s a more complete evaluation of GGUF variants of Qwen3.5 (models by @UnslothAI ), and it’s way better than I expected. - Qwen3.5 is very robust to Unsloth quantization - TQ1_0 preserves the original model’s accuracy extremely well - Most of the degradation is on MMLU Pro (meaning that the model lost a bit of its world knowledge) - At 94 GB, the TQ1_0 reduces memory usage by 700 GB (!) I ran the eval at temperature = 0, but TQ1_0 looked so strong that I double-checked with temperature = 0.6 and top_p = 0.95, and the results were more or less the same. Note: the goal of this eval is only to measure the degradation relative to the original model. It does not tell you how good the model is at the tasks in absolute terms, at least, not directly. For comparison, 94 GB is about what a standard 47B-parameter model would consume. That puts Qwen3.5 (TQ1_0) in “best model under 100 GB” territory.
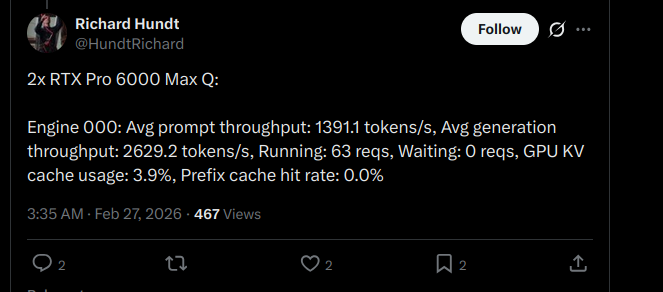
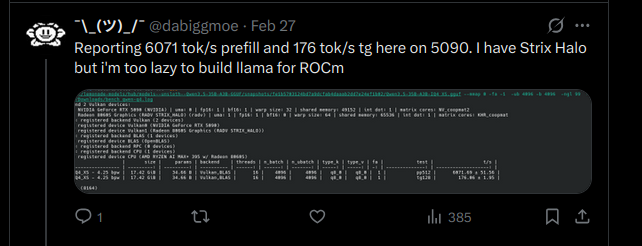
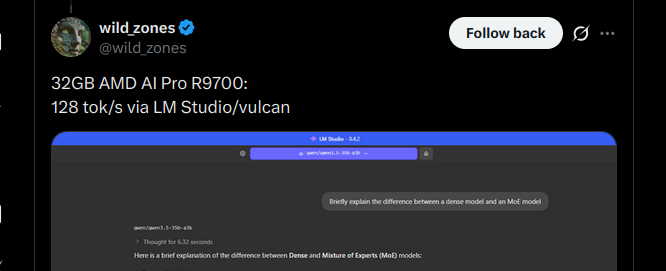
the numbers coming in from this thread: 5090: 166 tok/s (z33b0t), 153 tok/s (EmmanuelMr) 4090: 122 tok/s (StubbyTech) 3090: 112 tok/s (sudo), 100 tok/s (Eduardo) 6800XT: 20-30 tok/s (Dark) Qwen3.5-35B-A3B. 4-bit quant, 19.7 GB on disk. fits entirely on any single 3090 24GB card with room to spare. no offloading, no splitting, full speed. 5090 owners keep pushing the ceiling and we haven't found it yet. NVIDIA side is stacking up. where are the ROCm numbers? report your GPU and tok/s below. building the full map.


🚀 Introducing the Qwen 3.5 Medium Model Series Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B ✨ More intelligence, less compute. • Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts. • Qwen3.5-122B-A10B and 27B continue narrowing the gap between medium-sized and frontier models — especially in more complex agent scenarios. • Qwen3.5-Flash is the hosted production version aligned with 35B-A3B, featuring: – 1M context length by default – Official built-in tools 🔗 Hugging Face: huggingface.co/collections/Qw… 🔗 ModelScope: modelscope.cn/collections/Qw… 🔗 Qwen3.5-Flash API: modelstudio.console.alibabacloud.com/ap-southeast-1… Try in Qwen Chat 👇 Flash: chat.qwen.ai/?models=qwen3.… 27B: chat.qwen.ai/?models=qwen3.… 35B-A3B: chat.qwen.ai/?models=qwen3.… 122B-A10B: chat.qwen.ai/?models=qwen3.… Would love to hear what you build with it.


