silence retweetledi
silence
139 posts


silence retweetledi

「财新」当期出刊特稿:经济复苏了吗?
- 结论是肯定的,Q1的GDP涨了5个点,出口和工业生产两大引擎还在快速增长,去年出现下降的固定资产投资也回到微增趋势,最重要的是PPI在3月同比转正,走出了连续41个月为负值的低谷,价格水平的改善是最明确的证据;
- 出口增速高达14.7%,相当强劲,而且质量很高,代表新动能的机电产品占到了出口总额的六成以上,而且基于中国加工贸易的模式,出口繁荣也反过来拉动了进口数据超预期的大增22.7%;
- 供应强于需求、外需强于内需的结构依然保持,消费、地产、居民收入等薄弱板块与大盘轻微背离,体感上的温差确实存在;
- 主流经济学理论是期待通胀的,尤其是剔除掉能源波动的通胀回升,以及房地产的跌幅收窄,这些迹象的出现才意味着内需走强,必须摆脱低物价的困扰,目前来看,除了PPI,CPI也在回涨,这都是乐观信号;
- 如果分得更细一点,生产资料是有在涨价,生活资料却还在下跌,意味着上下游剪刀差扩大,直接面向消费端的下游企业会比较难受,没有完全摆脱增收不增利的陷阱;
- 上市公司的人均工资收入也在去年成功止跌,虽然没有大幅增加,但至少不再处于下行阶段,经济学家认为宏观复苏的既定节奏传递到个人收入上是有滞后性的,商品涨价-企业增收-扩大投入-工资增长的完整循环可能还要等上几个季度甚至更久;
- 固定资产投资的反弹取决于AI基建热潮和国家政策托底的双重拉动,财政支出在Q1完成年初预算的速度为近5年最快,服务于数据中心、新能源汽车的电力投资也是亮点;
- 地方政府的化债形势仍然严峻,因为土地出让收入一直在萎缩,叠加付息支出之后压力很大,但监管起来既不能过于严苛,也不能放任不为,只要兜底原则持续,就不会出现无法解决的问题,需要和时间做朋友,循序消化出清。

中文
@DiamondHal77842 @lijinxinglvshi 我就奇怪为什么要隐瞒,这种事好多国家都发生过,跟他一点关系都没有啊,最多民航总局担点责任
中文

silence retweetledi

silence retweetledi


silence retweetledi

强烈推荐大家看看DeepMind CEO Demis的最新判断。
真的,Google DeepMind 的 CEO Demis Hassabis 每一期访谈我觉得值得都花时间看看。这哥们讲东西很实在,而且通俗易懂。
早上边跑步边听完了他和 YC CEO Garry Tan 的最新一期播客。
刚刚把笔记写完,也给大家分享下。
多说一句,好多人问我这种笔记是不是 AI 写的。我说下自己的流程。
我会先完整听完播客,然后用语音输入法把感触尽量充分地讲出来,再让 AI 帮着整理初稿,最后自己逐字修改优化。
如果全部交给 AI 做总结,那等于把思考和理解的能力让渡给了 AI,对自己理解这件事其实没有任何价值。
OK,咱们进正题。
1
Demis 的态度非常明确,现在的大模型范式(大规模预训练 + RLHF + CoT)一定会是 AGI 最终架构的一部分,他不认为这会是条死路。
但要实现 AGI,还有几个关键问题要解决。这几个问题包括:持续学习、长程推理和记忆系统。
先从最容易看到的现象讲起,Context Window。
现在大模型处理长信息,最常用的招就是把 Context Window 一直撑大。一开始 8k,后来 32k,再后来 100 万 Token。听起来很厉害,但本质上是暴力堆砌。
Context Window 其实就相当于人脑里的 Working Memory,工作记忆。人的工作记忆能同时装多少东西?心理学里有个经典数字,7 个左右。背电话号码能记住 7 位上下,再多就溢出了。
大模型呢?已经做到 100 万 Token。
按理说,模型的工作记忆比人大几十万倍,应该比人聪明几十万倍才对。但显然不是。
问题也恰恰就出现在这。把所有东西都塞进 Context Window 里,里面包含了不重要的东西、错的东西、过时的东西。看起来信息很多,其实是一团乱麻。
那人为什么 7 个数字的工作记忆就够用?
因为人脑背后还有另一套机制在工作。我们记得几年前的事,记得童年的事,记得几小时前发生的事。这些都不塞在工作记忆里,而是另一套系统。
具体来说这套系统是海马体,大脑里负责把新知识整合进已有知识库的那个部分。
研究发现,人睡觉的时候,特别是 REM 睡眠阶段,大脑会重放白天重要的片段,让大脑从中学习。新东西在睡觉的过程里,温柔地融进了旧的知识体系。
这个把新东西融进旧知识库的过程,就是持续学习。
模型现在没有这套机制。每一次对话结束,刚学到的东西就会忘记。下次重新打开,还是上次那个模型,没长进。
2
再聊聊长程推理的问题。英文表达是 Long-term Reasoning。我翻译为了长程。
长程推理这个词太抽象了。Demis 讲了一个特别具体的故事,听完会立刻明白他说的是什么。
他说自己喜欢跟 Gemini 下国际象棋。下棋的过程里能看到模型的 thinking trace,也就是它在那里到底想了什么。
然后他发现一件怪事。
模型考虑一步棋的时候,思考链里清清楚楚写着,这步是个昏招。但接下来,它没找到更好的走法,于是又走回这步昏招。
明明知道是错的,还是把错的那一步走出去了。
这个细节比任何 benchmark 数据都说明问题。因为它暴露的是模型缺少对自己思考过程的某种内省能力。
正常人下棋,意识到一步是昏招之后,脑子里会有一个反应,停一下,再想想。停一下、再想想这个能力,模型现在没有。它能在每一步局部判断对错,但没法基于整盘棋的局势去调整整体策略。
这就是长程推理还没搞定的样子。模型可以一步一步往前走,每一步看起来都合理,但走到后面整盘棋的方向其实是错的。它没有那种退回到当前思考的上一层、重新审视一下的能力。
说到底,模型缺的是一种内省。
3
学习、长程推理、记忆,这是 Demis 在播客里点出来的三个 AGI 鸿沟。
除此之外,他还反复提到了创造力。
2016 年 AlphaGo 跟李世石下棋,第二局走出了著名的 Move 37。那一步棋走出来的瞬间,全世界的围棋高手都看呆了。
所有人类几千年下围棋积累的经验都告诉它不该下那里,但 AlphaGo 下了。下完之后大家发现,是一步神来之笔。
很多人觉得,这就是 AI 的创造力来了。
但 Demis 说,对他自己来说,Move 37 只是起点。他真正想看到的是另一件事。AI 能不能发明围棋这件事本身。
这两件事的区别非常关键。
Move 37 是在围棋这个现成的规则里,找到了一步人类没想到的招。但围棋的规则、棋盘的形状、黑白子的对弈方式,是人类发明出来的。AI 在已有的框架里非常厉害,但能不能自己造一个框架,是另外一回事。
Demis 给了一个具体的设想。
如果给 AI 一个高层次的描述。造一个游戏,五分钟能学会规则,要好几辈子才能精通,棋局有审美,一下午能下完一局。AI 能不能根据这个描述,自己倒推出围棋?
目前做不到。
为了把这件事讲得更清楚,Demis 还提了一个测试,他自己叫爱因斯坦测试。
用 1901 年人类已有的全部知识训练一个模型,看它能不能在 1905 年那个时间点,自己推出狭义相对论。
爱因斯坦在 1905 年那一年里,连写了几篇改变物理学的论文,后来叫爱因斯坦奇迹年。那些工作不是从已有的物理学论文里通过拼接得到的,是基于已有材料做了一次全新的概念跳跃。
爱因斯坦测试想问的就是这件事。AI 能不能做这种跳跃。
目前的大模型主要在做两件事,pattern matching 和 extrapolation。一个是从大量数据里找规律,一个是把规律往外延伸一点。但发现新东西需要的是类比推理的能力。从一个领域里抽出深层结构,搬到另一个全新的领域去用。
这个能力,模型现在还没有。也可能是有,但用法不对所以激发不出来。
4
除此之外,Demis 还分享了一个让我特别出乎意料的判断,他说未来 6 到 12 个月,真正的价值不在更大的模型,在更小的模型。
这一部分内容我反复听了好几次,确实突破我的已有认知。
不知道大家的想法,反正我自己,这一年来并没有怎么关注小模型的进展。毕竟行业的焦点就是把模型做大嘛。
那小模型的价值到底在哪?
最直接的是成本。同样一个任务,小模型的推理价格可能只是前沿模型的十分之一甚至更少。
但 Demis 说,比成本更重要的其实是速度。
这里有一个前提得先说清楚。Demis 不是在说速度可以替代智能。
他的原话是,当小模型的能力已经达到前沿模型的 90% 到 95%,也就是已经相当不错的时候,剩下那 5% 到 10% 的能力差距,比不上速度带来的好处。
比如现在工程师用 AI 写代码,已经形成了一种新的工作节奏。一个想法冒出来,几秒之内就能看到结果,不行就改,再不行再改。
这个一改再改的循环跑得越快,做出来的东西就越好。如果每次调用都要等十秒,整个工作流就被打断了。
更关键的是,快到一定程度,工程师在这种节奏里能进入心流。一个想法、一次尝试、一个反馈、再来一个想法,思维不被打断。
这件事写过代码的人都懂,进入心流和频繁掉出心流,产出的差距是数量级的。
Agent 也是同样的逻辑。一个 Agent 跑完一个任务可能要调几十次模型,每次慢一秒,整个任务就慢一分钟。慢到一定程度,Agent 就从一个能用的东西变成鸡肋。
小模型不是大模型的廉价替代品。有些事只有小模型能做。
比如手机、眼镜、家用机器人,需要的就是一个能在本地跑起来的模型。本地跑除了反应快,还有一个特别重要的好处,隐私。
家里机器人看到的视频、听到的对话,全部在设备本地处理,根本不上云。这件事对很多用户来说不是加分项,是底线。
成本、速度、边缘部署,这是小模型的价值。
5
讲完小模型的价值,接下来一个更关键的问题是,能力被压到这么小的参数里,会不会有上限?
Demis 的判断是,目前没看到信息密度有任何理论上限。小模型的智能天花板还远没看到。
支撑这个判断的,是 DeepMind 在蒸馏这件事上的积累。蒸馏简单说就是先训练一个超大的模型,然后用这个超大模型去教一个小模型。教完之后,小模型用极少的参数,能复现原来 95% 以上的能力。
为什么 DeepMind 这么重视蒸馏?因为要把 AI 能力放进谷歌的头部产品中,前提是低延迟、低成本。前沿模型再强,每次推理花几秒钟、花几毛钱...这条路,恐怕很难走得通。
一个前沿模型发布之后,6 到 12 个月内,他们就能把这个模型的能力蒸馏到边缘设备能跑的小模型上去。这个时间表比很多人想的要快。
在很多场景中,小模型和大模型会相互配合。
举个例子,一个端到端的智能助手,绝大部分日常任务在本地的小模型上跑。智能眼镜看到的画面、家里机器人听到的对话、手机里的私人助理,模型直接在设备里读懂,不需要往云端传一遍。
只有遇到特别复杂、本地搞不定的问题,才向云端的前沿模型发起请求。
也就是说小模型在边缘做主力,前沿模型在云端做后援。
不过,这个构想对小模型的要求也比较高,它不能只会处理文字,还得能理解物理世界。
这就是为什么 Gemini 从一开始就坚持多模态,不光处理文字,也处理图像、视频、声音。
一开始这么做比只做文本要难得多,但眼镜也好,机器人也好,需要的是一个能看懂周围世界的模型,不是一个只会聊天的模型。
讲到这里,小模型这条路的轮廓就完全清楚了。它独立成立,不是前沿模型的廉价替代品,而是另一条同样重要的路。
嗯,很有启发。
中文
silence retweetledi

吴恩达 2026 年新课《AI Prompting for Everyone》21 节看完,提炼最值得抄的 6 条:
1️⃣ 新手和高手差 5-10 倍产出,差在 4 个维度:问题难度、上下文、是否引导、写作流程
2️⃣ 信息获取分 3 层:pretrained / web search / deep research
复杂任务用 deep research 比手刷网页快几十倍
3️⃣ Context 窗口能塞 75 万字(≈ 哈利波特前 4-5 本)
换话题就开新对话防污染
4️⃣ 忘掉 "Let's think step by step",现在直接说 think hard 或 ultrathink
模型自己知道展开多少推理
5️⃣ ChatGPT 同意你的频率比不同意高 10 倍
反 sycophancy 4 招:中性提问 / 给评分卡 / 别埋偏见 / 列双方案
6️⃣ AI slop 4 大特征:滥用破折号、delve/nuanced、三人组排比、空洞 not X but Y
写作走渐进式大纲(出大纲 → bullet → 正文),不要让 AI 直接写正文
完整课程免费:learn.deeplearning.ai/courses/ai-pro…

Jason Zhu@GoSailGlobal
中文
silence retweetledi

silence retweetledi

🚨 行业大消息!华尔街顶尖机构Jane Street一名在校大三学生,直接拿下年薪22万至60万美元的高薪岗位。
核心原因很简单:他借助AI工具,处理分析海量数据的速度,远远甩开了机构里绝大多数资深交易团队。
这套逻辑,放在Polymarket预测市场同样适用,拼的从来不是直觉瞎猜,而是AI对海量数据的拆解与捕捉能力。
在一场一小时的干货讲座里,他完整拆解了整套落地系统的底层逻辑:
• 如何高效研读、梳理海量行业与市场数据集
• AI怎样精准捕捉人类肉眼容易忽略的行情规律、定价偏差
• 自建机器模型如何把原始数据,直接转化成可落地的交易决策
• 普通人怎么照搬这套思维,复刻到Polymarket等预测市场里赚钱
今晚别再刷剧追Netflix浪费时间了。
静下心花一小时看完这场分享就够了。
短短一个小时,足以颠覆你对市场研究、AI赋能,以及Polymarket机会红利的所有认知。
中文
silence retweetledi

自由图书《The Little Book of Deep Learning》
这本书的排版也非常适合在手机上阅读

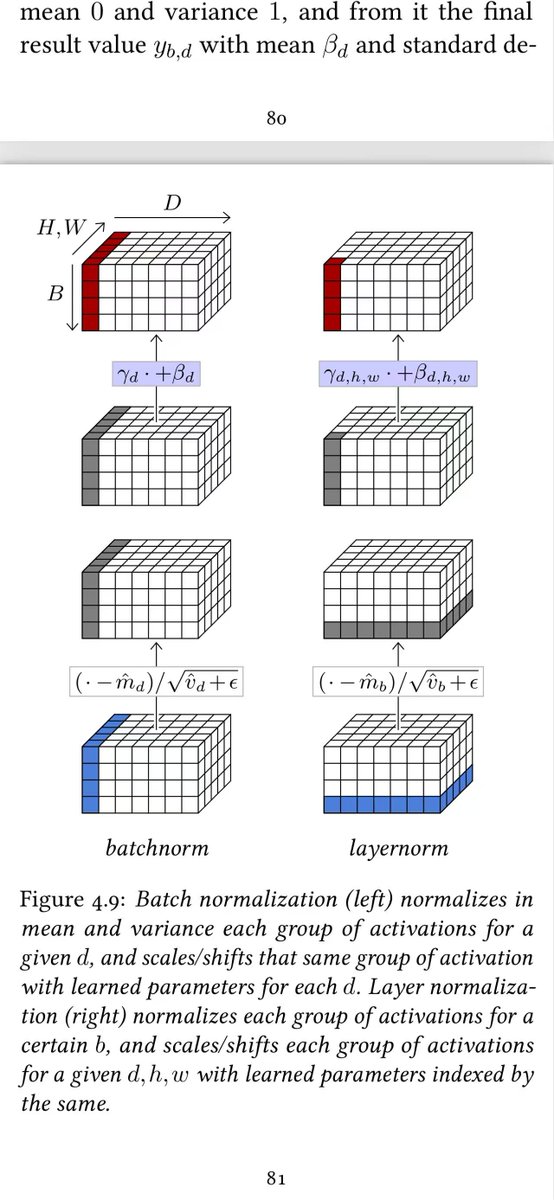
Mr Panda@PandaTalk8
176 页,50 万次下载,一本能装进手机的深度学习教科书。 日内瓦大学教授 François Fleuret 写的 The Little Book of Deep Learning,是我见过信息密度最高的 AI 入门读物: Part I 基础——机器学习、损失函数、梯度下降、反向传播、Scaling Laws Part II 模型——卷积网络、注意力机制、Transformer、GPT、ViT Part III 应用——图像分类、目标检测、语音识别、文本生成、图像生成 每一页都配图解,每个概念点到即止,不废话。 最适合两类人: 想系统补一遍 AI 底层知识的从业者, 以及被千页教材劝退过的初学者。 它做一件事:把深度学习从 CNN 到 Transformer 到 GPT 的完整脉络,压缩到了一个人能在一周内读完的体量,同时没有牺牲任何数学严谨性。 作者 François Fleuret 的原则很简单——不追求穷尽一切,只讲理解核心模型所必需的知识。 如果你一直想系统学一遍深度学习但被大部头劝退过,这本书可能是最好的起点。 免费:fleuret.org/public/lbdl.pdf
中文
silence retweetledi

网上的机器学习教程常见两种极端:要么满屏公式、讲得抽象难啃;要么只教你调框架、原理一笔带过。结果学完能跑代码,却抓不住算法的核心。
我在 GitHub 上挖到一本开源免费电子书《Applied Machine Learning in Python》,路线清晰、体系完整,把数学推导和 Python 实现紧密绑在一起,真正做到“懂原理,也会写”。
从线性回归一路到神经网络,每个算法不仅有完整推导,还给出纯 Python 的手工实现;再配上交互式可视化,把原本晦涩的数学概念变成看得见、摸得着的训练过程。
GitHub:github.com/GeostatsGuy/Ma…
在线阅读:geostatsguy.github.io/MachineLearnin…
你将学到:
- 覆盖 30+ 算法:回归、分类、聚类、降维一网打尽
- 每个算法:详细推导 + 纯 Python 手写实现,不止会用,更能理解
- 深度学习:ANN、CNN、自编码器、GAN 等主流架构系统讲透
- 交互式可视化:训练过程、参数变化一目了然
- 配套资源齐全:YouTube 讲座 + 完整代码仓库
全书免费在线读、代码全部开源,适合想系统入门并真正吃透机器学习原理的开发者。

中文
silence retweetledi

MIT 静悄悄放了 12 本 AI 教材出来,全部免费。同样内容去美国念个学位,学费要 5 万美元。
cyrilXBT 整理的清单,分四类。
【基础】
1. Foundations of Machine Learning(Mohri 等):经典 ML 教材,PAC 学习理论到核方法
cs.nyu.edu/~mohri/mlbook/
2. Mathematics for Machine Learning:ML 背后的线代、概率、微积分
mml-book.github.io
3. Probabilistic Machine Learning Part 2(Kevin Murphy):概率视角下的 ML 高级篇
probml.github.io/pml-book/book2…
【深度学习】
4. Deep Learning(Goodfellow/Bengio/Courville):业内俗称"花书"
deeplearningbook.org
5. Understanding Deep Learning(Simon Prince):2025 新版,配 Python notebook,比花书更新更友好
udlbook.github.io/udlbook/
【强化学习】
6. Reinforcement Learning: An Introduction(Sutton & Barto):RL 圣经,做 Agent 必看
incompleteideas.net/book/the-book-…
7. Distributional Reinforcement Learning:第一本系统讲分布式 RL 的教材
distributional-rl.org
8. Multi-Agent Reinforcement Learning:多 Agent 协作完整入门
marl-book.com
【应用与工程】
9. Foundations of Computer Vision(Torralba 等):现代 CV 全景图
visionbook.mit.edu
10. Machine Learning Systems:ML 模型的系统工程化
mlsysbook.ai
11. Machine Learning in Production:从模型到真正的产品
mlip-cmu.github.io/book/
12. Fairness and Machine Learning:AI 公平性问题
fairmlbook.org
啃下来需要一点数学和编程基础。如果你只是想"了解 AI",这些书太硬,去找科普书更合适。但要真搞懂 AI 是怎么回事的人,看这些比看 100 篇科普文章都管用。
CyrilXBT@cyrilXBT
MIT just quietly dropped a free AI curriculum that puts $50,000 university courses to shame. 12 books. Zero tuition. From the same institution that produced the people building the models everyone is talking about. FOUNDATIONS 1. Foundations of Machine Learning — lnkd.in/gytjT5HC 2. Understanding Deep Learning — lnkd.in/dgcB68Qt 3. Machine Learning Systems — lnkd.in/dkiGZisg ADVANCED TECHNIQUES 4. Algorithms for ML — algorithmsbook.com 5. Deep Learning — lnkd.in/g2efT6DK REINFORCEMENT LEARNING 6. RL Basics (Sutton & Barto) — lnkd.in/guxqxcZZ 7. Distributional RL — lnkd.in/d4eNP-pe 8. Multi-Agent Systems — marl-book.com 9. Long Game AI — lnkd.in/g-WtzvwX ETHICS & PROBABILITY 10. Fairness in ML — fairmlbook.org 11. Probabilistic ML Part 1 — lnkd.in/g-isbdjj 12. Probabilistic ML Part 2 — lnkd.in/gJE9fy4w This is a complete MIT-level AI education. Not a YouTube playlist. Not a Twitter thread full of fluff. Textbooks written by the researchers who built the field. The people who actually study this will not just understand AI better than their peers. They will understand it better than most people currently getting paid to work in it. Most people will bookmark this and never open it. The ones who open it tonight are the ones who show up in 12 months having built something nobody around them understands yet. Bookmark this. Open the first one tonight. Follow @cyrilXBT for more resources that actually compound.
中文
silence retweetledi

silence retweetledi

silence retweetledi

silence retweetledi

silence retweetledi

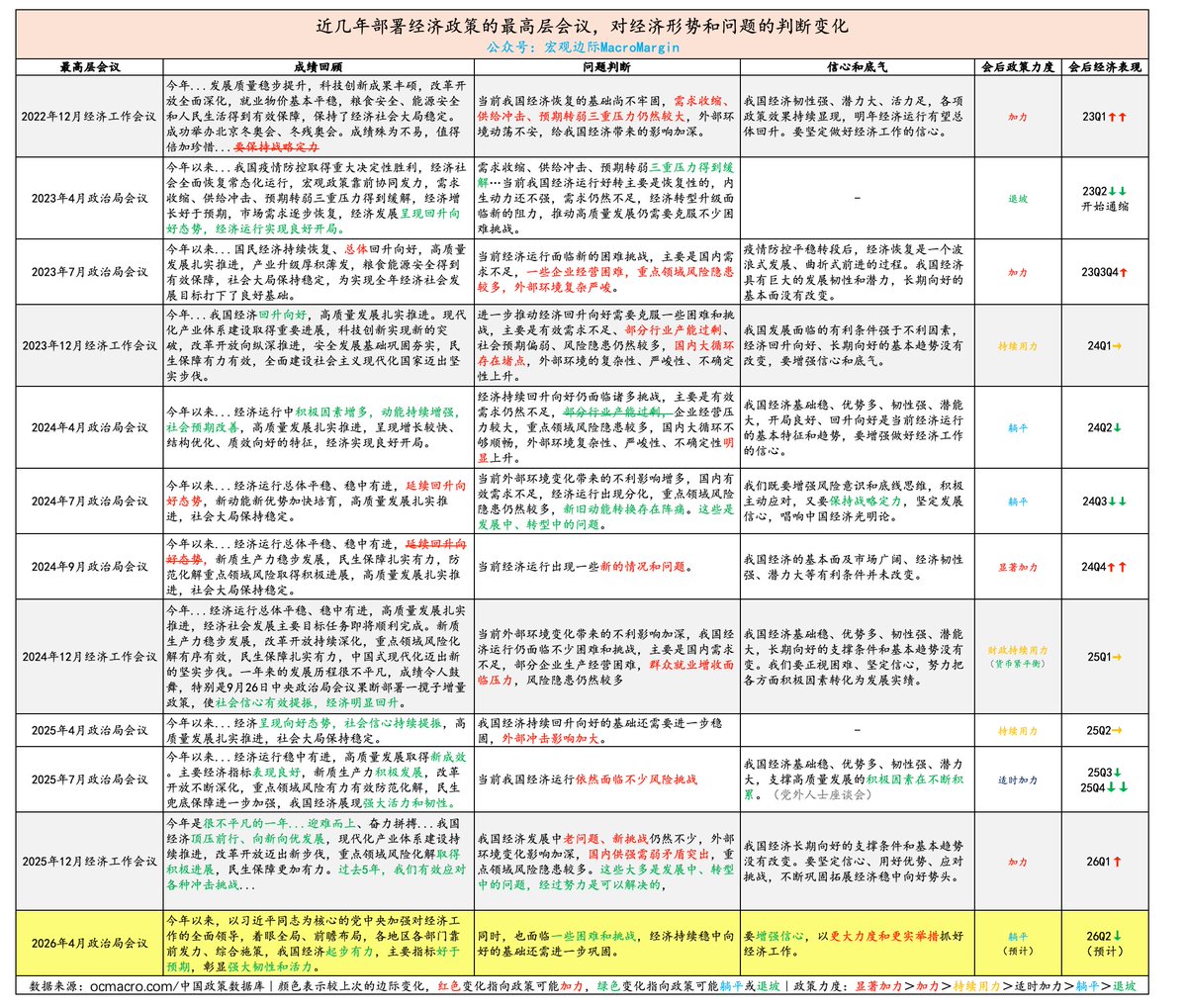
方才有空暇,简单写个4月政治局简评:
1、对今年以来的经济形势评价颇高:“我国经济起步有力,主要指标好于预期,彰显强大韧性和活力”。
这个评价基本是完全照搬了何的评价(上期简报总结过),这个评价甚至比统计局同志的评价还要高。
2、对当前问题的判断,相应也比较保守:“也面临一些困难和挑战,经济持续稳中向好的基础还需进一步巩固”。
这是认为问题有所好转的表现,比如上周简报前瞻认为“供强需弱”问题可能被弱化,这里直接没有再提及。 如果以价格指标衡量“供强需弱”的话,该问题确实在好转。
对经济评价颇高,问题又边际降级,确实足以“增强信心”,对应宏观政策也自然应该降级。
虽然有提“以更大力度和更实举措抓好经济工作”,但这放在的是过去应对中长期的“信心底气”的部分,是一个务虚的位置,也是一个务虚的提法,不是对接下来经济工作的指导标准。
3、因此,对宏观政策的定调已经做出重大改变,不再提“更加积极有为”,转而说“用好用足”。
变化脉络:“超常规+更加积极有为”(924之后) → “更加积极有为”(25年) → “用好用足”(如今)
4、对于财政和货币政策的定调,还是“更加积极”和“适度宽松”。
这没问题,一般情况下4月政治局不会这么快推翻此前经济工作会议定下的基调,而且这两者的定调改变对预期影响也非常之大,这么着急做改变,也不利于稳预期。
但还是再这两者前面加了一句“精准有效实施”的限定语,这也是对财政货币政策的弱化表述,与前面对宏观政策的弱化相呼应。
4、所以宏观增量政策就别想了。
上周简报提出的“政策天平”,几乎是快全面导向高质量发展(产业政策、监管政策、适当的改革政策、应对外部冲击的未雨绸缪,如能源安全等)。
所以后面部署的任务基本与高质量发展有关,比如侧重于生产性的服务业、电网等六网、统一大市场和内卷、人工智能+(座谈会部署)、能源安全、拖欠企业账款问题等等,这些都是高质量发展和外部冲击的方向,上周简报前瞻中也基本都有提及,大致政策方向可以说和此前的前瞻基本一致。
5、不过,这次没有提及“城乡居民增收计划”,这是上周简报有提及,经济工作会议也有部署,市场也翘首以盼的关键政策。但这里没有提及,不知道是要继续难产推迟,还是因为经济和预期转好,这项工作的紧迫性下降,又可以稍微放一放了?
不过不止这一个文件没有提及,其他也没有。比如此前座谈会应该有讨论过两个文件,一个是教育科技人才发展方案(上周简报有提及),另一个就是城乡居民增收计划。
前者应该不久能出来,后者可能就不一定了,希望即使又推迟 也不要推迟太久。
6、直接提生猪价格,是非常罕见的。
不过此前经济工作会议已有迹象,当时没有这么直白,说的是稳定农产品价格。今年以来,显然生猪价格是最不稳且影响也最大的,所以直接点名批评生猪了。
前两周农业部开过生猪座谈会,当时韩俊在会上的措辞确实比过去更加激烈,难怪,原来是上升到最高级别关注事项了,肯定也是挨了批评的。
接下来这方面应该会有更大的力度,比如调整能繁母猪目标保有量等手段,去年简报也有提过。
7、房地产一如预期没有什么变化。
说没有变化也不对,由此前经济工作会议“着力稳定”,变为了“努力稳定”,这一字之差,不能说明政策方向上的边际变化。
但往往有强调的意味,能说明的是,决策层还是关注房地产,并且认为还是房地产还是需要“努力稳定”,没有因为最近市场一致鼓吹“企稳甚至回升”的形势大好,而这么快改变对房地产的政策基调。
当然也有和前面财政货币基调不改,有类似考虑,即为了稳定预期。
...更多会在本周简报中展开
中文
silence retweetledi
4 月政治局会议,最重要的是对宏观政策的定调,拿掉了“更加积极有为”的说法,改用“用好用足”是很明显的弱化。
变化脉络:
“超常规+更加积极有为”
↓
“更加积极有为” (不再“超常规”)
↓
“用好用足” (不再说“积极有为”)
本次会议定调和关键方向,与我上周简报分析完全一致,转向高质量发展和外部冲击。
中文
silence retweetledi

Andrej Karpathy 本可以将这个打包成一个 2000 美元的大师课程。 相反,他免费上传到了 YouTube。 三小时内容,涵盖现代 LLM 的实际工作原理: 分词、神经网络、RLHF、幻觉、工具使用、强化学习,以及像 AlphaGo 和 DeepSeek 这样的系统。
《Andrej Karpathy 大师》中字
pan.quark.cn/s/b019ffff1c5d
Allen Braden@allen_explains
Andrej Karpathy could have packaged this into a $2,000 masterclass. Instead, he uploaded it to YouTube for free. Three hours covering how modern LLMs actually work: tokenization, neural nets, RLHF, hallucinations, tool use, reinforcement learning, and systems like AlphaGo and DeepSeek. This isn’t about prompts. It’s about understanding the machine behind the magic.
中文