
Simon Kozlov
1.3K posts
Simon Kozlov
@sim0nsays
Researcher at MIT, generative AI for biology
New York, NY Katılım Mart 2009
317 Takip Edilen2.6K Takipçiler

Coding is solved by AI no more than protein folding is solved by AI
English
Simon Kozlov retweetledi

Former Roblox CTO Keith V Lucas joins the show to reminisce about the early days of the platform, share memories of David and Erik, and break down notable moments throughout Roblox history.
New episode out now on YouTube, Spotify, and anywhere else you listen to podcasts!
English
Simon Kozlov retweetledi

What could Alphafold 4 look like? (Sergey Ovchinnikov, Ep #3)
2 hours listening time
(links below)
To those in the (machine-learning for protein design) space, Dr. Sergey Ovchinnikov (@sokrypton) is a very, very well-recognized name.
A recent MIT professor (circa early 2024), he has played a part in a staggering number of recent great papers in the field: ColabFold, RFDiffusion, Bindcraft, automated design of soluble proxies of membrane proteins, elucidating what protein language models are learning, conformational sampling via Alphafold2, and many more. Of course, all these papers were group efforts, but Sergey's name comes up astonishingly frequently!
And even beyond the research that have come from his lab in the last few years, the co-evolution work he did during his PhD/fellowship also laid some of the groundwork for the original Alphafold paper, being cited twice in it.
This is a two hour conversation with him, asking every question I could think of. We talk about his own journey into biology research, an issue he has with Alphafold3, what Alphafold4-and-beyond models may look like, what research he’d want to spend a hundred million dollars on, and lots more.
Topics/institutions we discuss: @arcinstitute's Evo models, @HWaymentSteele's work, @IsomorphicLabs's AF2/AF3, and @EvoscaleAI's ESM models
Also, extremely grateful to Asimov Press (@asimovpress) for helping fund the travel + studio time required for this episode! They are a non-profit publisher dedicated to thoughtful writing on biology and metascience, such as articles over synthetic blood and interviews with plant geneticists. I myself have published within them twice! I highly recommend checking out their essays at asimov.press, or reaching out to editors@asimov.com if you’re interested in contributing.
Timestamps:
[00:00:00] Highlight clips
[00:01:10] Introduction + Sergey's background and how he got into the field
[00:18:14] Is conservation all you need?
[00:23:26] Ambiguous vs non-ambiguous regions in proteins
[00:24:59] What will AlphaFold 4/5/6 look like?
[00:36:19] Diffusion vs. inversion for protein design
[00:44:52] A problem with Alphafold3
[00:53:41] MSA vs. single sequence models
[01:06:52] How Sergey picks research problems
[01:21:06] What are DNA models like Evo learning?
[01:29:11] The problem with train/test splits in biology
[01:49:07] What Sergey would do with $100 million
English
@Shedletsky Can it generate the part list and the instructions though
English



Hey followers who are game developers: you should play Slay the Spire because it will teach you about game design & especially UX design.
Hey StS fans: you should try the Packmaster mod, it makes StS a whole new game.
Hey Packmaster fans: 👍
Hey Elon: let me link to this stuff without deboosting my tweets. Thx!
English

@ElliotHershberg The cost of testing out ideas is formulating them cleanly :)
Hmm didn’t realize connection to writing before.
English
I find myself more aggressively using version control when I use Cursor.
That way, I can plunge down a rabbit hole and just as quickly pop back out.
The cost of testing out specific ideas is basically zero.
English
@karpathy @patrickc explainpaper.com tries to do a similar experience for reading scientific papers. Haven’t tried it for books, but I can imagine scaling it.
English

Exactly, roughly what I tried and mostly failed. I want to highlight some text in the pdf, pull out the highlight, the preceding text of the chapter, maybe the generated summaries of the other chapters, put it all together, attach nearby images if any… there’s a whole design space on how to build the context before you submit different kinds of queries to the AI book club. Queries like explain, discuss, argue in favor or opposed, take notes, create anki cards, generate quiz or exercises for thinking through the content, …
English
One of my favorite applications of LLMs is reading books together. I want to ask questions or hear generated discussion (NotebookLM style) while it is automatically conditioned on the surrounding content. If Amazon or so built a Kindle AI reader that “just works” imo it would be a huge hit.
For now, it is possible to kind of hack it with a bunch of script. Possibly someone already tried to build a very nice AI-native reader app and I missed it.
English
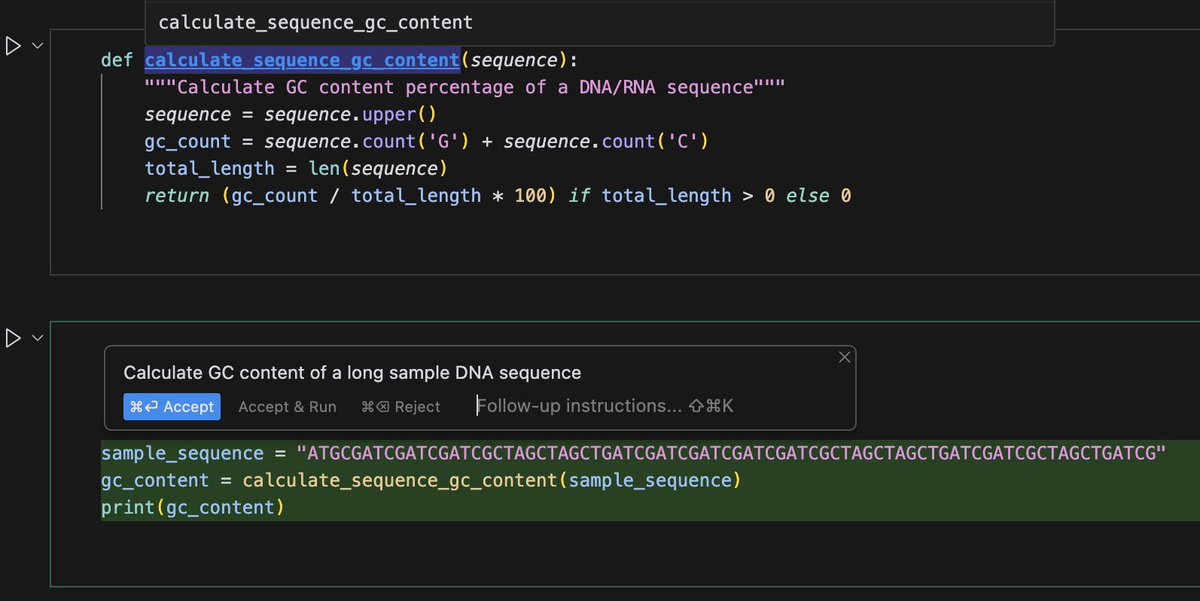
@ElliotHershberg @cursor_ai @ProjectJupyter Apply doesn't work from the side pane, but works from the inline chat (Cmd-K is the shortcut). Context from prior cells is weird - as you can see, it can see it sometimes, but often can't. My theory is all the notebook output is also passed and can quickly fill all the context.
English
@sim0nsays @cursor_ai @ProjectJupyter Maybe I'm missing something, but Cmd-K can't actually apply code suggestions into notebook cells, and seems to have a total lack of context for prior cells (which is surprising given the notebook file is attached as context!)
English
Finally giving @cursor_ai a test drive, and, damn... it's amazing.
But the total lack of @ProjectJupyter support is surprising and disappointing.
English
@ProfTomEllis Another theme is making all kinds of stretched arrangements for kids for an evening call and the other person not showing up
English

@ferruz_noelia Appreciate the response! Ok, so predicting structure is not a relevant problem, so no good analogy. How about an analog of Protein Language Models a few years earlier in Chem ML?
English

@sim0nsays Predicting 3D structures of molecules was never as much of a problem as it is for proteins because they have multiple quite different conformations in solution and the torsions can in either case be solved with various levels of QM theory
English
The easiest way to predict what we Bio+ML people will be publishing in two years is to look at what Chem+ML people are publishing today
English
@nickcammarata Was just playing with a prompt for Claude to reformulate comments in the private chat (say judgmental unsolicited feedback to supportive open-ended questions), kinda want to have this as a filter
English

@karpathy 100% agree. It feels connected to Goodhart’s Law - to measure something as a stable eval metric, you need to make it constrained, reduce the complexity of tradeoffs, get it to “right-wrong” answer, make context clear, etc. And all that makes it less and less real.
English
Moravec's paradox in LLM evals
I was reacting to this new benchmark of frontier math where LLMs only solve 2%. It was introduced because LLMs are increasingly crushing existing math benchmarks. The interesting issue is that even though by many accounts (/evals), LLMs are inching well into top expert territory (e.g. in math and coding etc.), you wouldn't hire them over a person for the most menial jobs. They can solve complex closed problems if you serve them the problem description neatly on a platter in the prompt, but they struggle to coherently string together long, autonomous, problem-solving sequences in a way that a person would find very easy.
This is Moravec's paradox in disguise, who observed 30+ years ago that what is easy/hard for humans can be non-intuitively very different to what is easy/hard for computers. E.g. humans are very impressed by computers playing chess, but chess is easy for computers as it is a closed, deterministic system with a discrete action space, full observability, etc etc. Vice versa, humans can tie a shoe or fold a shirt and don't think much of it at all but this is an extremely complex sensorimotor task that challenges the state of the art in both hardware and software. It's like that Rubik's Cube release from OpenAI a while back where most people fixated on the solving itself (which is trivial) instead of the actually incredibly difficult task of just turning one face of the cube with a robot hand.
So I really like this FrontierMath benchmark and we should make more. But I also think it's an interesting challenge how we can create evals for all the "easy" stuff that is secretly hard. Very long context windows, coherence, autonomy, common sense, multimodal I/O that works, ... How do we build good "menial job" evals? The kinds of things you'd expect from any entry-level intern on your team.
Epoch AI@EpochAIResearch
1/10 Today we're launching FrontierMath, a benchmark for evaluating advanced mathematical reasoning in AI. We collaborated with 60+ leading mathematicians to create hundreds of original, exceptionally challenging math problems, of which current AI systems solve less than 2%.
English
@Shedletsky Business opportunity: buy used Lego in bulk, use AI to come up with sets from the pieces you got, sell full sets
English
The price of used Lego on eBay has declined 75% in real terms over the past two decades.
Civilization is doomed.
English
