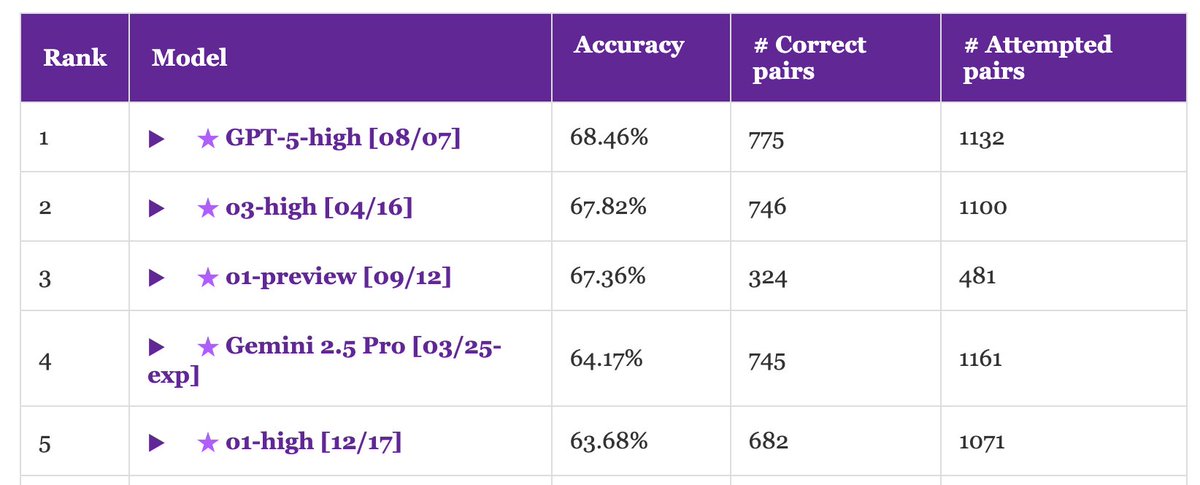
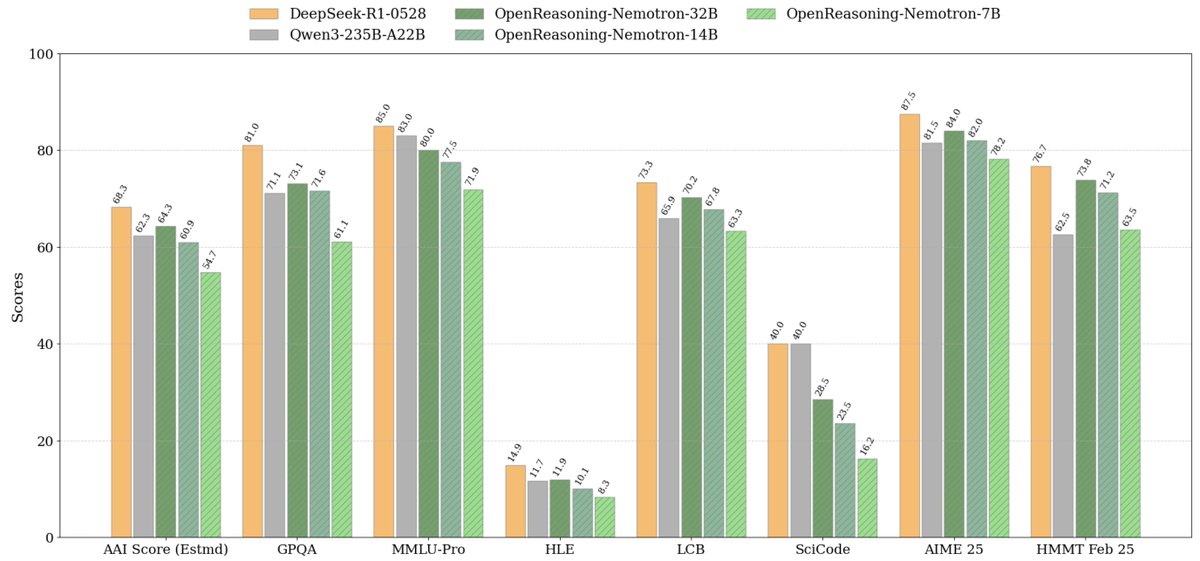
Simeng Sun retweetledi

AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:

English