Igor Gitman retweetledi
Igor Gitman
77 posts


Igor Gitman retweetledi

⚡ NVIDIA Nemotron 3 Super is live on OpenRouter!
120B params, 12B active. Hybrid Mamba-Transformer MoE with highest throughput efficiency in its class.
1M context. Fully open weights, data, and recipes. Built for multi-agent systems that need to think fast.
English
Nemotron 3 Super is out! It's really good and it will only get better from here.
And we release all the details - tech report, training code, training data, model weights. Everything you need to build a model like this yourself!
Bryan Catanzaro@ctnzr
Announcing NVIDIA Nemotron 3 Super! 💚120B-12A Hybrid SSM Latent MoE, designed for Blackwell 💚36 on AAIndex v4 💚up to 2.2X faster than GPT-OSS-120B in FP4 💚Open data, open recipe, open weights Models, Tech report, etc. here: research.nvidia.com/labs/nemotron/… And yes, Ultra is coming!
English
Igor Gitman retweetledi

Igor Gitman retweetledi

Nemotron 3 Super is here — 120B total / 12B active, Hybrid SSM Latent MoE, designed for Blackwell.
Truly open: permissive license, open data, open training infra. See analysis on @ArtificialAnlys
Details in thread 🧵below:


English
Igor Gitman retweetledi

Nemotron Super (120B, 10B active, ≈"3B" class speed) destroys all Qwens, gpt-oss, matches Kimi K2.5, exceeds Step 3.5 Flash and V3.2, and to my knowledge is only beaten by two open models (309B MiMo and Speciale) on the most interesting benchmark today.
@htihle pls test

Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞)@teortaxesTex
Well, seems we're not getting DeepSeek V4 today but we're getting what amounts to its lite version runnable on normal hardware. New architecture, fast, 1M context… …and it's a bit weaker than the equivalent Qwen 3.5.
English
Igor Gitman retweetledi

At Nvidia we're really into synthetic data and how to make better agents, faster. I was really excited about this technique from @DongfuJiang , @zhuofengli96475 and team and I wanted to reproduce their SDG in Data Designer with our new release. Check it out!
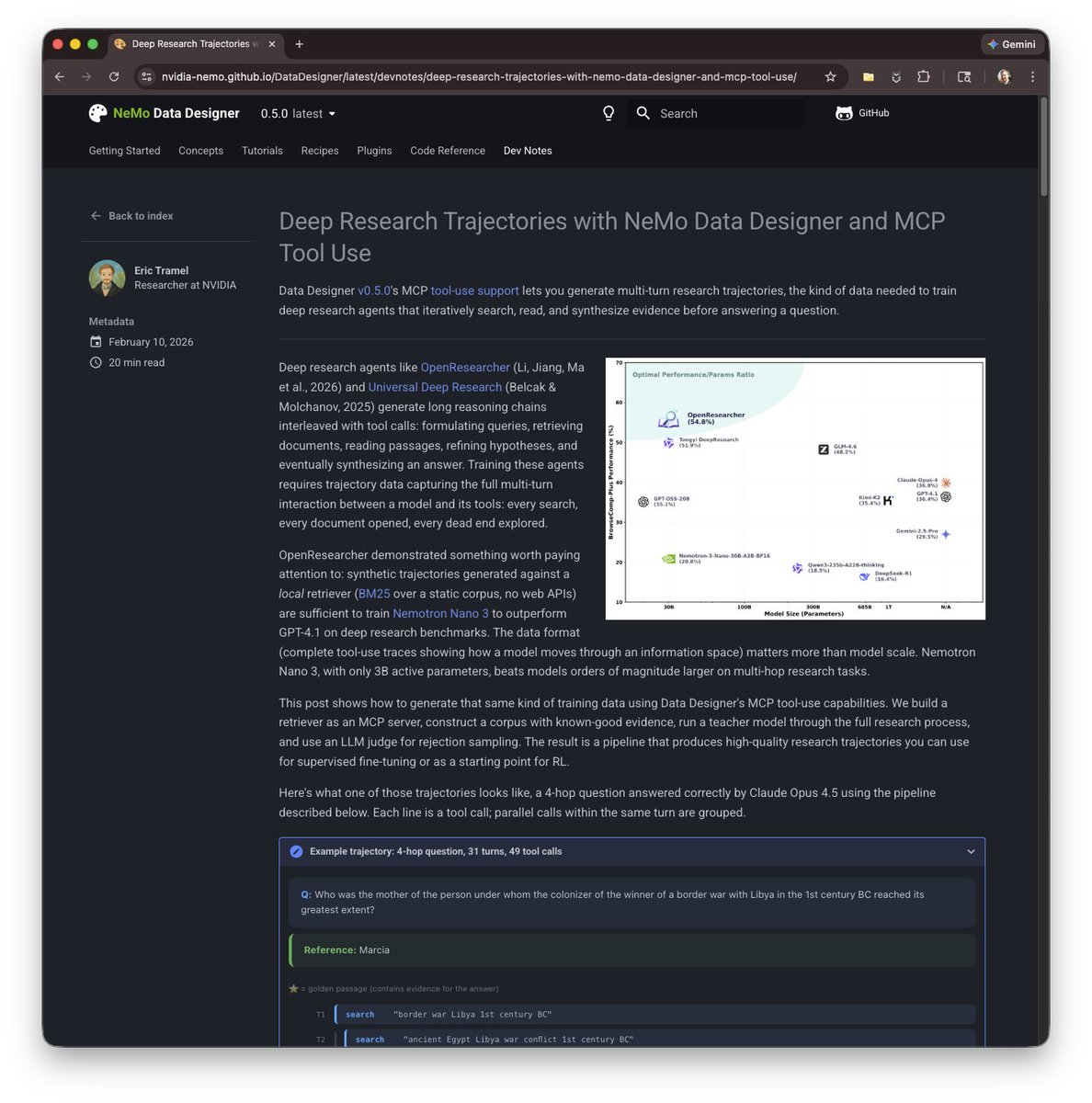
Dongfu Jiang@DongfuJiang
🚀 Introducing OpenResearcher: a fully offline pipeline for synthesizing 100+ turn deep-research trajectories—no search/scrape APIs, no rate limits, no nondeterminism. 💡 We use GPT-OSS-120B + a local retriever + a 10T-token corpus to generate long-horizon tool-use traces (search → open → find) that look like real browsing, but are free + reproducible. 📈 The payoff: SFT on these trajectories turns Nemotron-3-Nano-30B-A3B from 20.8% → 54.8% accuracy on BrowseComp-Plus (+34.0). 🧩 What makes it work? 🔎 Offline corpus = 15M FineWeb docs + 10K “gold” passages (bootstrapped once) 🧰 Explicit browsing primitives = better evidence-finding than “retrieve-and-read” 🎯 Reject sampling = keep only successful long-horizon traces 🧵 And we’re releasing everything: ✅ code + search engine + corpus recipe ✅ 96K-ish trajectories + eval logs ✅ trained models + live demo 👨💻 GitHub: github.com/TIGER-AI-Lab/O… 🤗 Models & data: huggingface.co/collections/TI… 🚀 Demo: huggingface.co/spaces/OpenRes… 🔎 Eval logs: huggingface.co/datasets/OpenR… #llms #agentic #deepresearch #tooluse #opensource #retrieval #SFT
English
Igor Gitman retweetledi

Need to accelerate inference for math problem solving?
Large language models can solve challenging math problems. However, making them work efficiently at scale requires the right serving stack, quantization strategy, and decoding methods—often spread across different tools.
This @nvidia blog post shows how to build a fast, reproducible inference pipeline with the NVIDIA NeMo-Skills library to manage NVIDIA TensorRT-LLM.
🔗developer.nvidia.com/blog/how-to-ac…
#PyTorch #OpenSourceAI #AI #Inference #Innovation
English
Igor Gitman retweetledi

Nvidia paper behind Nemotron-Math, a massive math tutoring dataset so smaller Large Language Models can learn long, tool checked reasoning.
It contains 7.5M step by step solutions, some as long as 128K tokens, meaning text pieces, written in 3 reasoning styles.
This dataset also shows self checking, where the model runs Python code to avoid simple arithmetic mistakes.
The authors mix competition problems from Art of Problem Solving with real questions from Mathematics Stack Exchange and MathOverflow.
They use open model gpt-oss-120b as a teacher, generating multiple solutions per problem at high, medium, and low depth.
For long context training, they sort examples by length and fine tune in stages, so most steps use shorter text before 128K.
That schedule gives about 2-3x faster training with roughly 1-3% less accuracy, and the extra Stack Exchange problems make the trained models handle messier questions better.
----
Paper Link – arxiv. org/abs/2512.15489
Paper Title: "Nemotron-Math: Efficient Long-Context Distillation of Mathematical Reasoning from Multi-Mode Supervision"

English
Igor Gitman retweetledi

🚀🚀🚀 We’re excited to support @NVIDIA and their new open family of models: NVIDIA Nemotron 3!
Open in weights, data, tools, and training, Nemotron 3 is built for multi-agent apps and features:
⚡️An efficient hybrid Mamba‑Transformer MoE architecture
🧾1M token context for long-term memory and improved reasoning
🧠 Multi‑environment reinforcement learning via NeMo Gym for advanced skill adaptation
Plus NVFP4 pre-training, latent MoE, 1T tokens of data, and more!
Read more about the model: blog.vllm.ai/2025/12/15/run…
English
Igor Gitman retweetledi
NVIDIA Nemotron 3 Nano is live on OpenRouter!
It is a small MoE reasoning model built for specialized agentic AI systems.
Just like others in the Nemotron family, Nano 3 is fully open with:
- Open weights, open data, & open recipes
- Designed for customization & optimization
English
Igor Gitman retweetledi

This is not just another strong open model. Nemotron actually releases training data (!), RL environments, and training code. This is a big difference: almost all model developers just want people to use their models; NVIDIA is enabling people to make their own models. We are excited to incorporate these assets into the next Marin models! Congrats to the @nvidia team!
Bryan Catanzaro@ctnzr
Today, @NVIDIA is launching the open Nemotron 3 model family, starting with Nano (30B-3A), which pushes the frontier of accuracy and inference efficiency with a novel hybrid SSM Mixture of Experts architecture. Super and Ultra are coming in the next few months.
English
Igor Gitman retweetledi

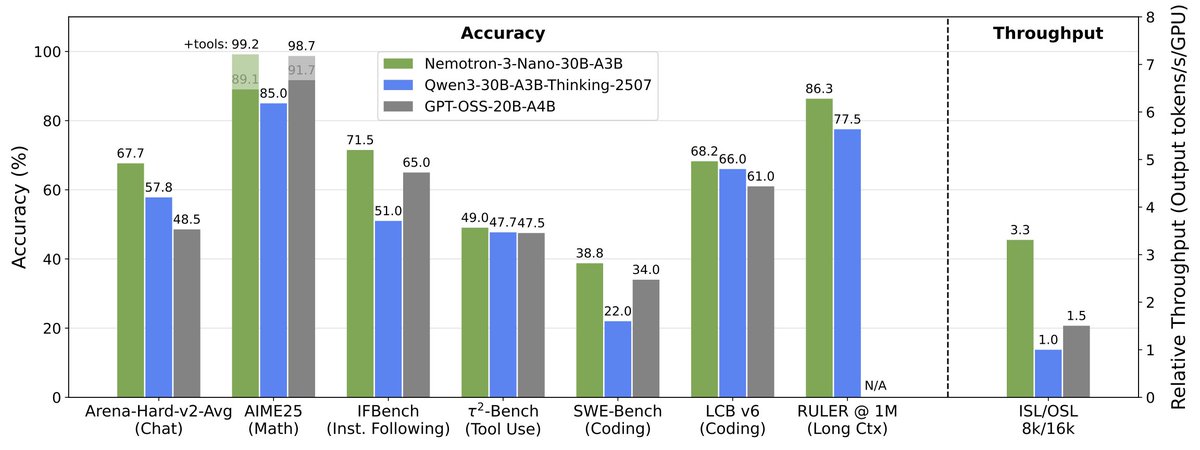
Nemotron 3 Nano by @nvidia, available now in LM Studio! 👾
> General purpose reasoning and chat model
> MoE: 30B total params, 3.5B active
> Supports up to 1M tokens context window
> Hybrid arch: 23 Mamba-2 and MoE layers, 6 Attention layers
Requires ~24GB to run locally.

English
Igor Gitman retweetledi

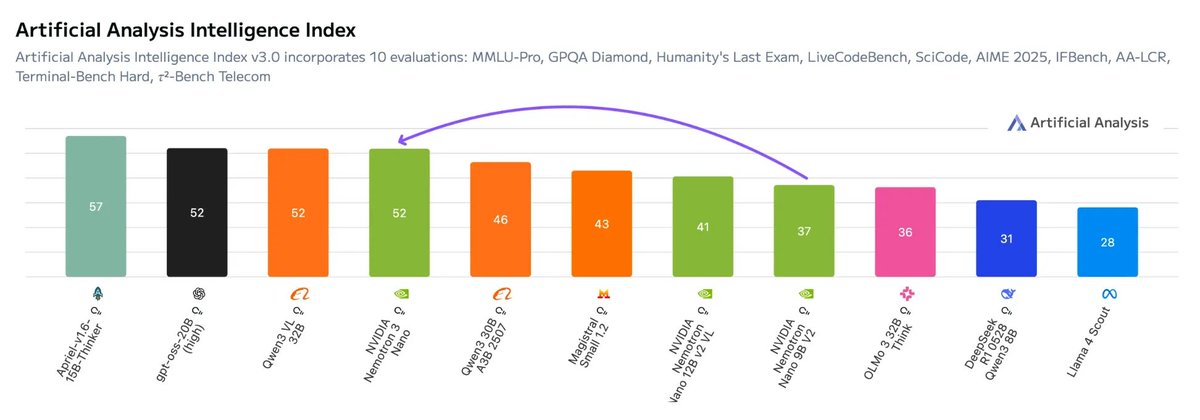
NVIDIA has just released Nemotron 3 Nano, a ~30B MoE model that scores 52 on the Artificial Analysis Intelligence Index with just ~3B active parameters
Hybrid Mamba-Transformer architecture: Nemotron 3 Nano combines the hybrid Mamba-Transformer approach @NVIDIAAI has used on previous Nemotron models with a moderate-sparsity MoE architecture, enabling highly efficient inference, particularly at longer sequence lengths
Small-model improvements: with 31.6B total and 3.6B active parameters, Nemotron 3 Nano scores 52 on our Intelligence Index, in line with OpenAI’s gpt-oss-20b (high). This represents a +6 point lead on the similarly-sized Qwen3 30B A3B 2507 and +15 improvement on NVIDIA’s previous Nemotron Nano 9B V2 (a dense model)
High openness: Nemotron 3 Nano follows other recent NVIDIA models in open licensing and releases of data and methodology for the community to use and replicate - it scores an 67 on the Artificial Analysis Openness Index, in line with previous Nemotron Nano models
Key model details:
➤ 1 million token context window, with text only support
➤ Supports reasoning and non-reasoning modes
➤ Released under the NVIDIA Open Model License; the model is freely available for commercial use or training of derivative models
➤ On launch, the model is being made available with a range of serverless inference providers including @baseten, @DeepInfra, @FireworksAI_HQ, @togethercompute and @friendliai, and it is available now on Hugging Face for local inference or self-deployment
See below for our full analysis and key announcement links from NVIDIA 👇
English
Igor Gitman retweetledi

🚀 Day-0 support for @NVIDIA Nemotron 3 Nano in SGLang
SGLang now supports Nemotron 3 Nano on Day 0 🎉
A highly efficient, fully open Hybrid MoE model with 1M context, thinking budget, and industry-leading accuracy per compute.
✅ Open weights, data, and recipes
⚡ Fast, low-latency inference with SGLang
🧠 Built for agentic workflows, coding, and reasoning
👇 Get started in minutes with the SGLang Cookbook!
Run BF16 / FP8, serve locally, and start building today.
#SGLang #Nemotron #Day0Support #OpenSourceAI #LLM #Inference



English
Despite the small size, this is by far the best model we've released! And as always, we don't just release the model, but we release pretty much everything you need to reproduce it.
If you're interested in math reasoning, we have two new datasets for you to try.
- Nemotron-Math, which is a collection of 350K "final-answer" math problems and 7.5M natural language solutions generated by gpt-oss-120b (with and without Python tool use and with all 3 reasoning regimes). Training on this data you can easily get a model to 100% on AIME 24/25 if you use majority voting and Python TIR.
- Nemotron-Math-Proofs, which contains 580k natural language proof problems, 550k formalizations into theorem statements in Lean 4, and 900k reasoning trajectories from Goedel-Prover-v2 culminating in valid Lean 4 proofs (some theorems have multiple proofs). We weren't able to formalize all statements and we weren't able to prove all that we formalized, but we release everything, so that others can improve it. Doing simple SFT on this data can fully reproduce (and slightly improve) the accuracy of Goedel-Prover-v2 8B model on Lean benchmarks.
You can find the datasets as well as more details here:
- Nemotron-Math: huggingface.co/datasets/nvidi…
- Nemotron-Math-Proofs: huggingface.co/datasets/nvidi…
Bryan Catanzaro@ctnzr
Today, @NVIDIA is launching the open Nemotron 3 model family, starting with Nano (30B-3A), which pushes the frontier of accuracy and inference efficiency with a novel hybrid SSM Mixture of Experts architecture. Super and Ultra are coming in the next few months.
English
@jaseweston @j_foerst Is there an example of a benchmark to measure this? As in, how do we focus it on the "collaboration" aspect? E.g. if we just ask people to solve problems using AI, we won't be able to distinguish between human-AI collaboration getting better vs AI alone just getting better?
English

🤝 New Position Paper !!👤🔄🤖
@j_foerst and I wrote a position piece on what we think is the path to safer superintelligence: co-improvement.
Everyone is focused on self-improving AI, but (1) we don't know how to do it yet, and (2) it might be misaligned with humans.
Co-improvement: instead, build AI that collaborates *with us* to solve AI faster, and to help fix the alignment problem together. More details in the paper!
Read it here:
📝:github.com/facebookresear…

English
Igor Gitman retweetledi

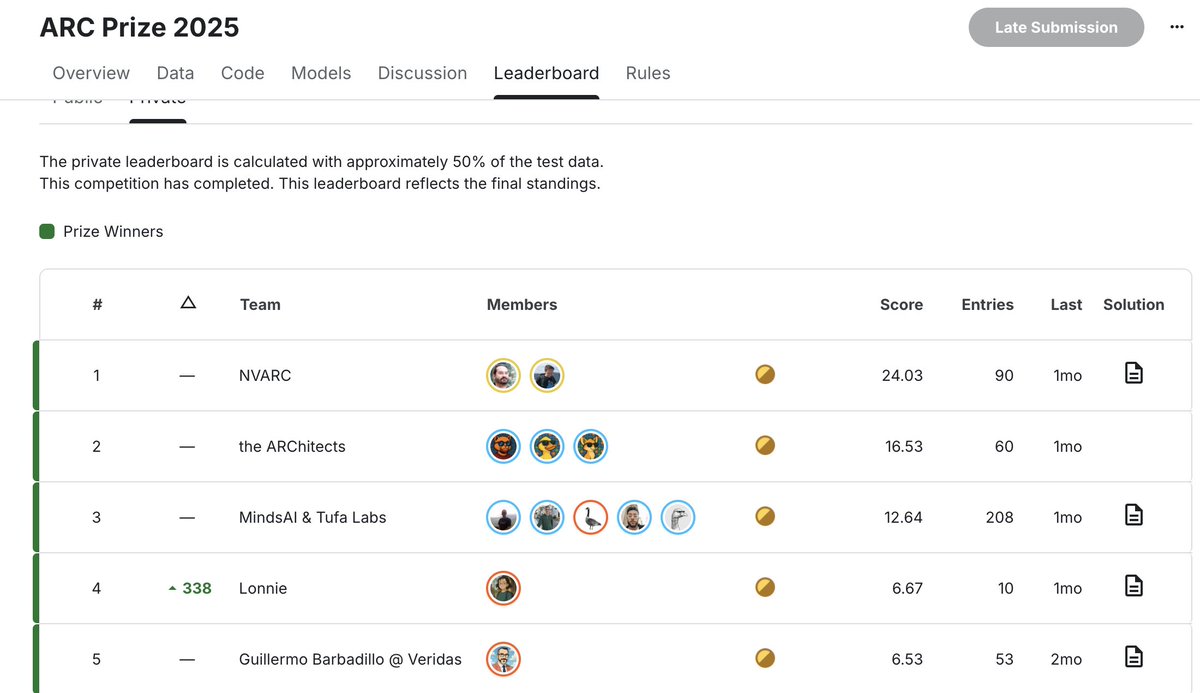
Ivan Sorokin and I are the official winners on the Arc Prize competition, with a significant lead over other teams.
Thanks to @kaggle and @arcprize for hosting the competition.
NVIDIA tech blog summarizing what we did: developer.nvidia.com/blog/nvidia-ka…
Our writeup: kaggle.com/competitions/a…
Our code: github.com/1ytic/NVARC
English
We will present this work at MathAI workshop at Neurips. If you're interested, come talk to us!
Paper link: arxiv.org/abs/2511.13027
Code and full instructions to reproduce our work in Nemo-Skills: github.com/NVIDIA-NeMo/Sk…
English
So, are LLMs reliable as mathematical proof judges? Unfortunately, we still see many critical mistakes even from best models like GPT-5 or Gemini 2.5, especially for hardest problems. We shouldn't rely on LLMs for evaluation purposes, especially when testing many candidate solutions. But hopefully they are good enough to provide a meaningful signal for RL, which we plan to explore next!
English
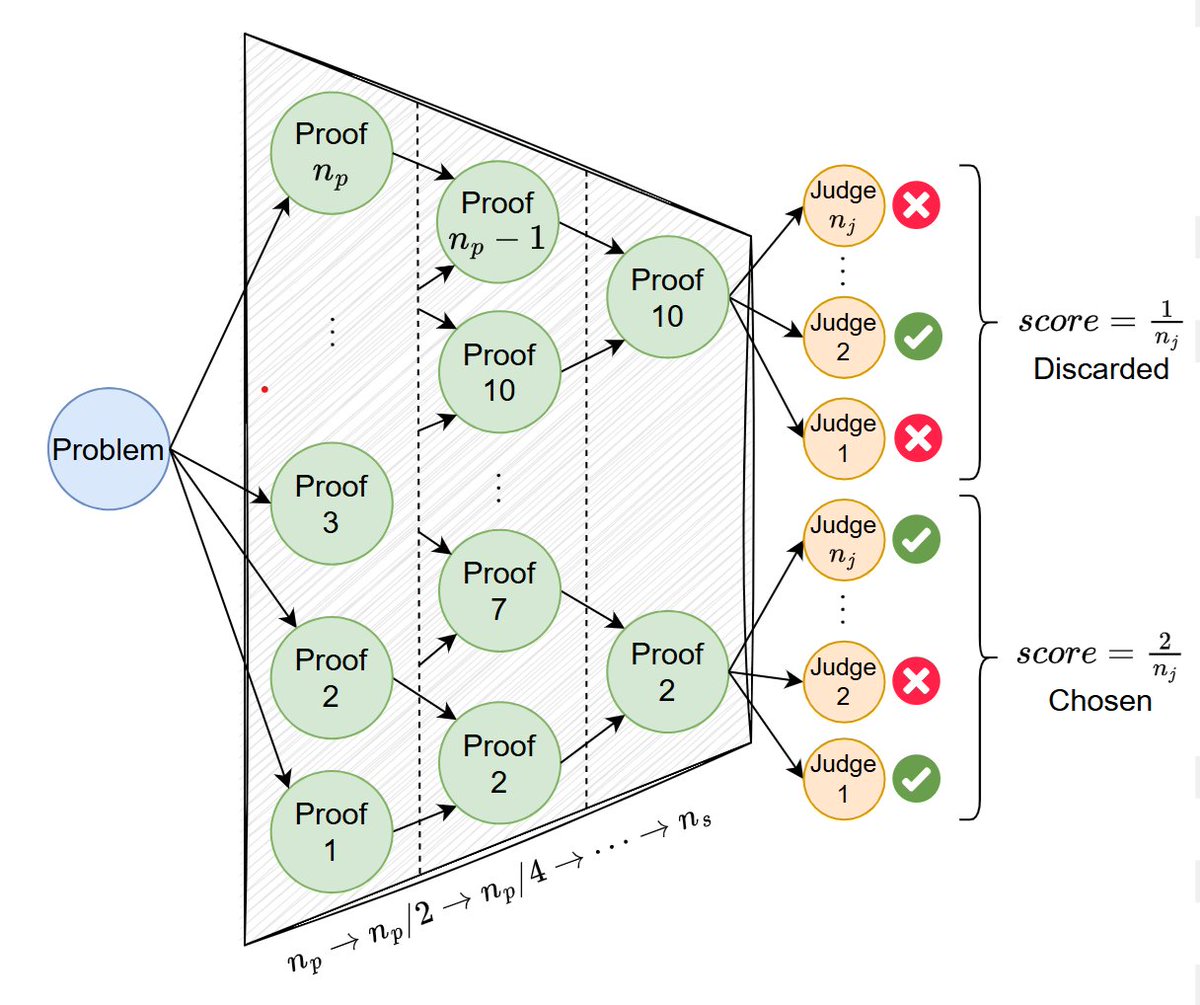
What do we need to win IMO gold with open-weight LLMs next year? If we want to do it in natural language (like OpenAI and DeepMind did), we most likely need the following 3 components.
1. A scalable way to evaluate correctness of LLM-written proofs.
2. A massive test-time compute to generate, refine and verify proof candidates.
3. A large-scale RL run combining (1) and (2) to produce proofs for hardest training problems and reinforce correct reasoning.
We published a paper "Scaling Generative Verifiers for Natural Language Mathematical Proof Verification and Selection" exploring (1) and (2). Here are a few highlights.
English