
Sabitlenmiş Tweet

Introducing the SHA-RNN :)
- Read alternative history as a research genre
- Learn of the terrifying tokenization attack that leaves language models perplexed
- Get near SotA results on enwik8 in hours on a lone GPU
No Sesame Street or Transformers allowed.
arxiv.org/abs/1911.11423
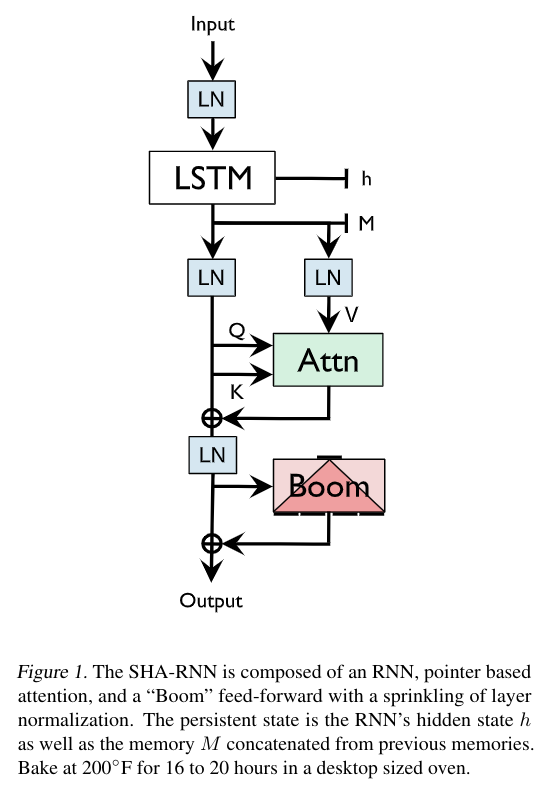
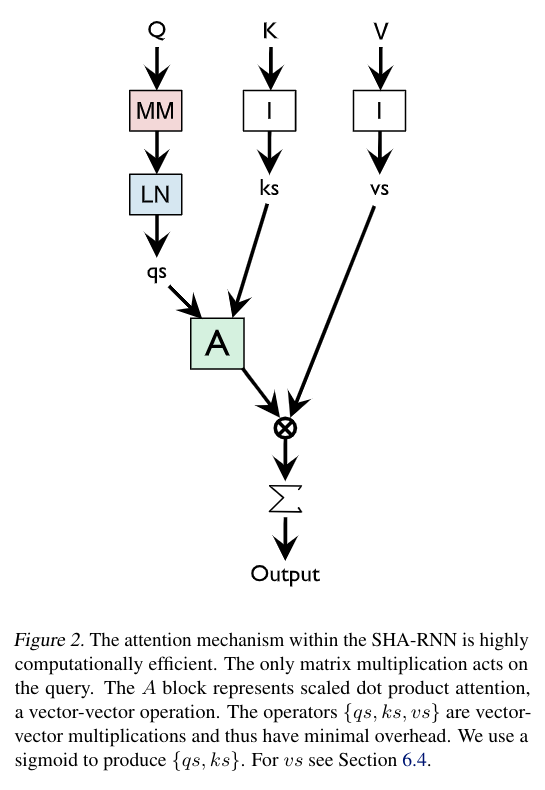
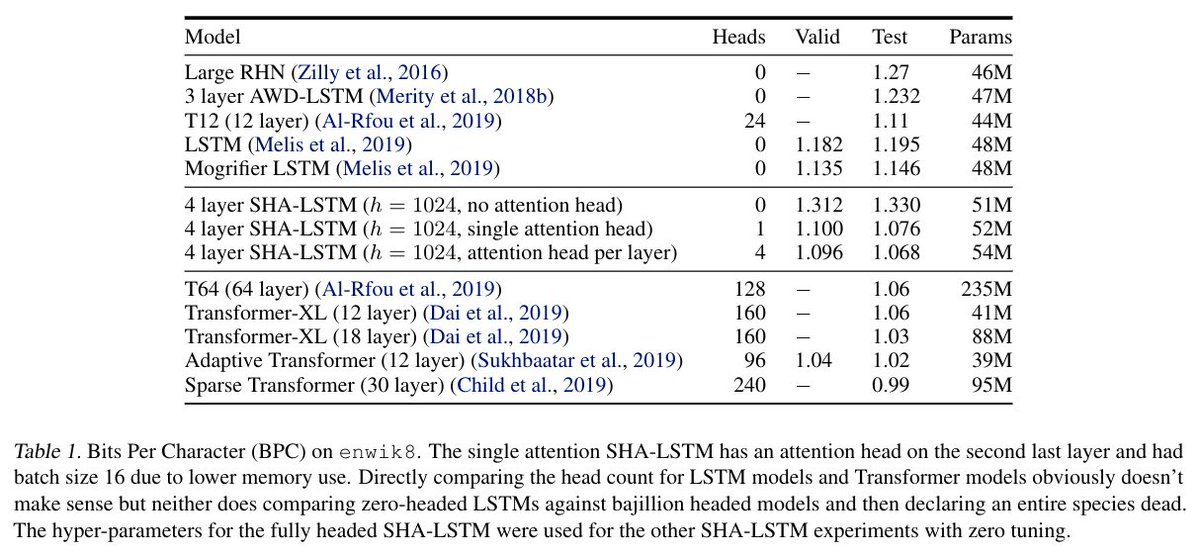
English





















