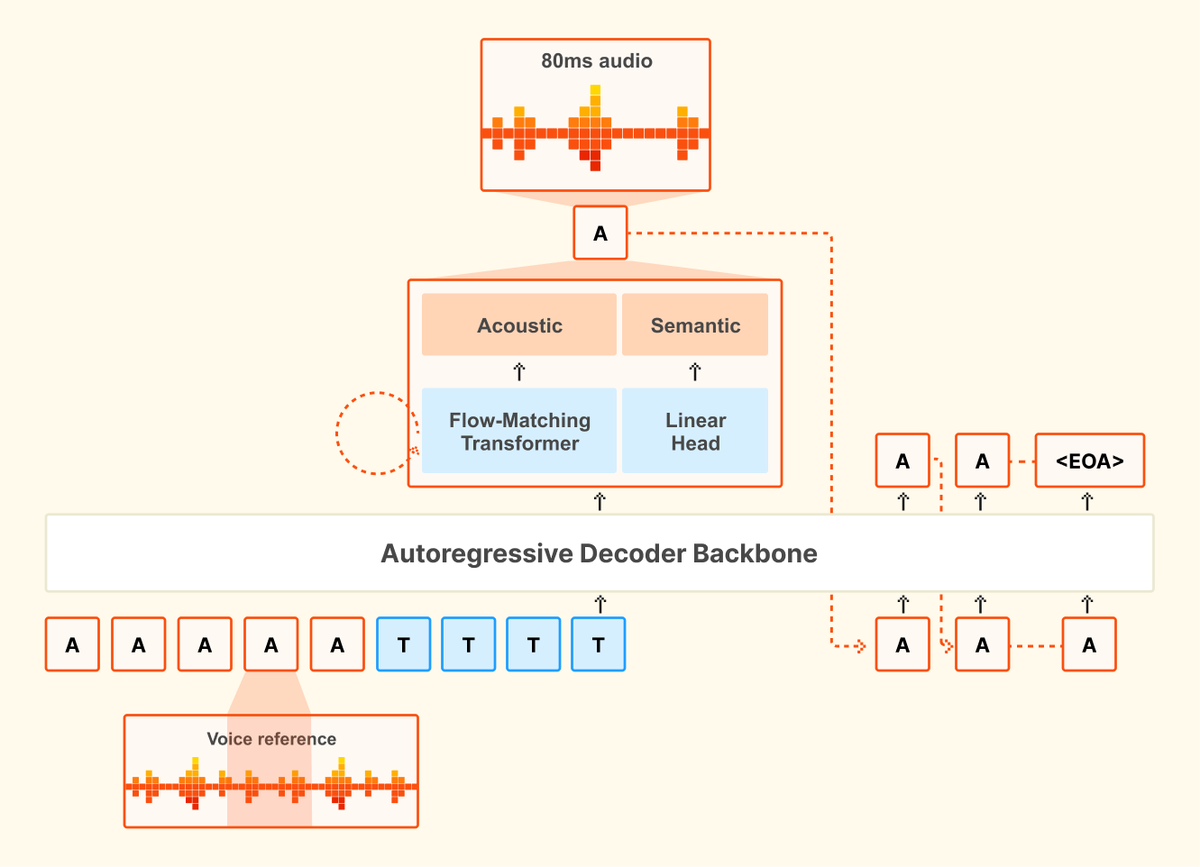
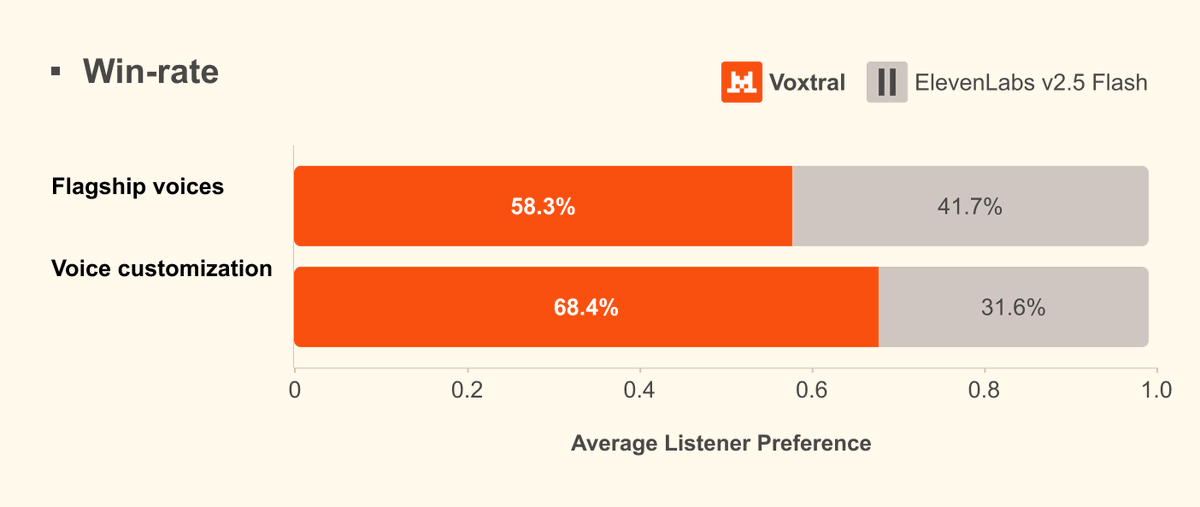
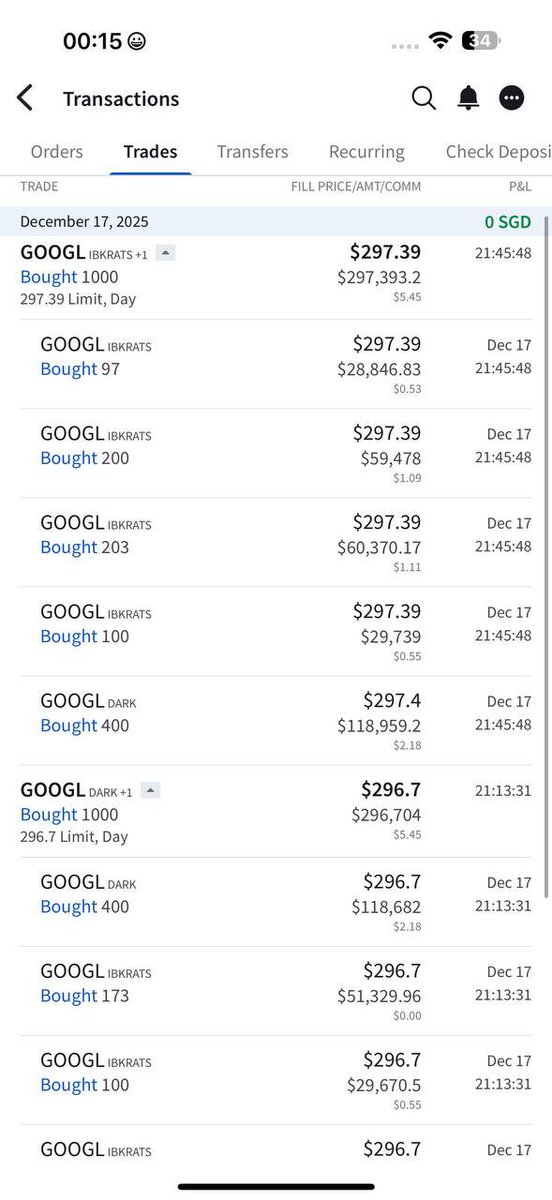
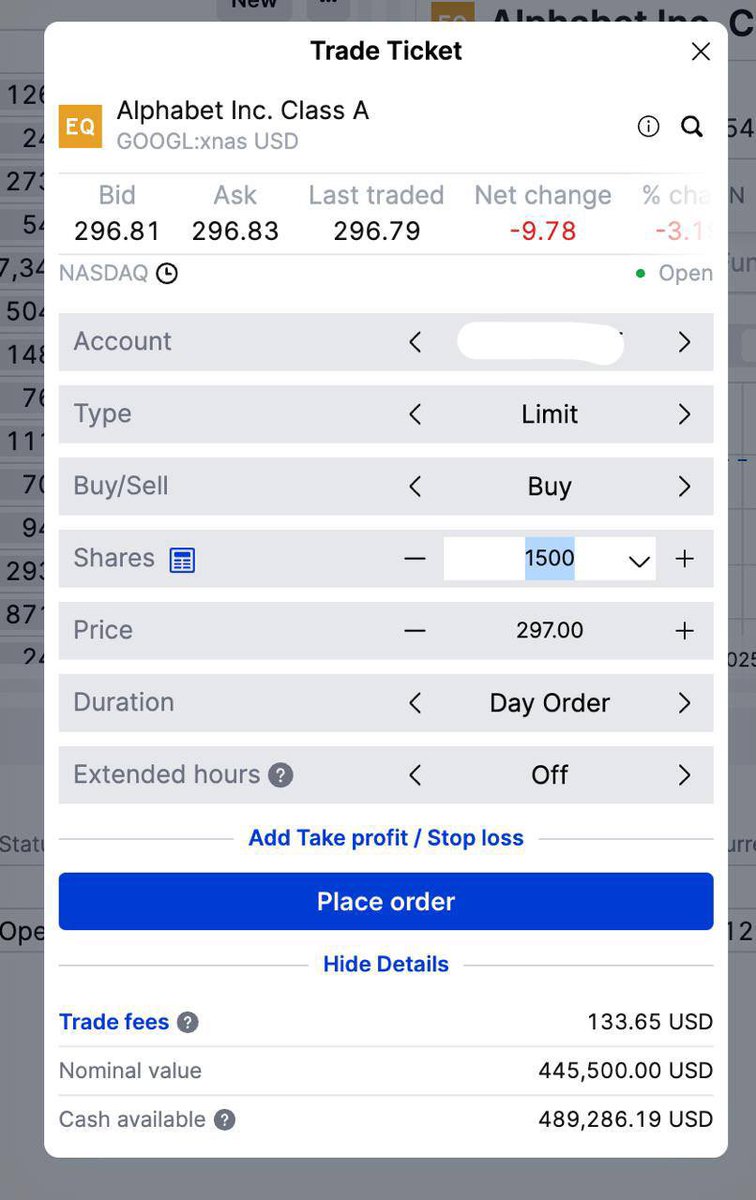
Soham retweetledi

Two truths, no lies:
- Most AI models are insanely powerful.
- Most people use a tiny fraction of that power.
Closing that gap isn’t about better models, it’s about better products.
NextToken puts AI’s power in your hands, for your day-to-day work.
English