swiderek
3.6K posts


swiderek
@swiderek
Cloud | Cyber Security | Innovation | Startup | Consulting | Expert | Problem Solver
Katılım Mayıs 2008
3.1K Takip Edilen6.2K Takipçiler

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
U mnie to działa - wiem, jak to brzmi 😁 Po wykorzystywaniu GitHub Projects ( choć kazdy ai woli issues) wróciłem do epików w Markdown i działa to lepiej. Mam też mocne poczucie, że projekty w JS i Pythonie są lepiej ogarniane przez Claude Code. Z praktyki widzę, że język ma znaczenie. I tak, zarządzanie agentami to nie to samo co zarządzanie ludźmi.
Polski

Eksperyment autonomicznego kodowania systemu Antec (personal agentic system - jak OpenClaw). dobiega końca - 60h (myślę, że jeszcze potrzeba z 8h).
Ant-ec -> techniczna, pracowita mrówka -> eksperyment wielki w odpowiedzi na liczne twierdzenia. że systemy agentowe do kodowania to:
- to może ... za kilka lat
- prędzej mi kaktus na ręce wyrośnie niż on zakoduje system
- tylko do projekcików weekendowych
- małe repo (kilka plików) później już się gubi
- do niczego się nie nadaje bo nie umie kodować
- mnóstwo generuje kodu bez sensu
- jedno naprawi, 10 zepsuje
Satystyki eksperymentu:
- Timing: 24h+24h+12h (non stop) - właśnie leci 70 "fala" (w sumie 78). Dzień i noc - bez nadzoru człowieka (na początku był bo musiałem co chwila poprawiać skrypty orkiestrujące, prompty itd. - teraz chodzi 100% bez czlowieka).
- git - na początku były commity tylko po fazach (w sumie pewnie ponad 100 fal będzie - na koniec przekształcę wszystko w taką strukturę - jako lessons learned z eksperymentu - tak działa znacznie lepiej).
- testy - w sumie już 1350 test casów,
- kod - 56201 linii kodu w 100 plikach Rust (100% rust'a wybrałem - szybkość będzie znacznie, znacznie szybszy niż OpenClaw, świetny język tak ogólnie).
Efekt:
Ocenię dzisiaj późnym wieczorem albo jutro rano (zobaczymy kiedy skończy). Są trzy możliwości:
1. Nic z tego nie wyjdzie - kompletny szmelc ....
2. Trzeba będzie poprawiać .... ale to i tak lepiej niż pisać od zera.
3. Pójdzie od "palca".
Oczywiście możecie oczekiwać wpisu na temat stau i liczby koniecznych zmian. Będzie ocena interfejsu, zaimplementowanych funkcjonalności. Jeśli zda egzamin udostępnię repo do wglądu.
Lessons learned:
- Przegląd 16 systemów agentowych typu OpenClaw -> wiedza jak takie systemy budować (komponentów jest kilkadziesiąt od orkiestracji, poprzez multiagentowość, tools, MCP, skills, llm hub, wielojęzyczność, kanały dostępowe, security, sandboxing, REPL, cron etc.)
- Wybrane najlepsze techniki - z każdego coś tam wyciągnąłem co pozwala podnieść jakość produktu w sumie backlog technicznych trickow to kilkadziesiąt rozwiązań.
- CLI Claude Code 100% - jako yolo mode - zarządzanie kontekstem, sandboxing, tools, mcp, claude.md.
- Podział zakresu projektu na fazy, fale, user stories, kryteria akceptacji - odpowiednia budowa repo pod yolo mode.
- Specyfikacja architektury, zakresu (PRD), głównych komponentów, UI (+Figma)
- Autonomiczne testy
- Zarządzanie repo w ciągłym procesie
- Specyfikacja pod dobre benchmarki kolejnych modeli do kodowania - Codex, Gemini, Claude Code - będę to uruchamiał i testował, który lepszy.
- Być może oddam gotowy system do uruchomienia na jakimś separowanym środowisku - planuję to uruchomić na Nvidia Orin u siebie w domu.
Polski
“The Leftwing nut jobs at Anthropic have made a DISASTROUS MISTAKE trying to STRONG-ARM the Department of War” - Donald Trump
This is the best news I wasn’t waiting for. Anyone who knows Dario Amodei’s story, leaving OpenAI because AI safety mattered more than growth, saw this coming. The man is consistent to the bone.
Today thousands of AI engineers around the world are probably losing their minds that the best model just got kicked out of the Pentagon. But this is exactly the moment that separates companies with principles from companies with slide decks about principles.
Values in business cost real money. That’s exactly why they matter, you pass that test only when it actually hurts.
If anyone deserves an award for courage in tech it’s Amodei. Also Skynet is not coming as fast as I thought, because OpenAI models are definitely not Cyberdyne Systems.
#Anthropic #AI #Claude #Skynet
English
swiderek retweetledi

We’re building an LLM chip that delivers much higher throughput than any other chip while also achieving the lowest latency. We call it the MatX One.
The MatX One chip is based on a splittable systolic array, which has the energy and area efficiency that large systolic arrays are famous for, while also getting high utilization on smaller matrices with flexible shapes. The chip combines the low latency of SRAM-first designs with the long-context support of HBM. These elements, plus a fresh take on numerics, deliver higher throughput on LLMs than any announced system, while simultaneously matching the latency of SRAM-first designs. Higher throughput and lower latency give you smarter and faster models for your subscription dollar.
We’ve raised a $500M Series B to wrap up development and quickly scale manufacturing, with tapeout in under a year. The round was led by Jane Street, one of the most tech-savvy Wall Street firms, and Situational Awareness LP, whose founder @leopoldasch wrote the definitive memo on AGI. Participants include @sparkcapital, @danielgross and @natfriedman’s fund, @patrickc and @collision, @TriatomicCap, @HarpoonVentures, @karpathy, @dwarkesh_sp, and others. We’re also welcoming investors across the supply chain, including Marvell and Alchip.
@MikeGunter_ and I started MatX because we felt that the best chip for LLMs should be designed from first principles with a deep understanding of what LLMs need and how they will evolve. We are willing to give up on small-model performance, low-volume workloads, and even ease of programming to deliver on such a chip.
We’re now a 100-person team with people who think about everything from learning rate schedules, to Swing Modulo Scheduling, to guard/round/sticky bits, to blind-mated connections—all in the same building. If you’d like to help us architect, design, and deploy many generations of chips in large volume, consider joining us.
English
I’m an AI & cybersecurity specialist. What I see daily terrifies me. I’ve waited for someone to show the world what’s coming. “The AI Doc: Or How I Became an Apocaloptimist” — from the Oscar-winning creators of EEAAO. Most important film of the decade. Share this. Algorithms suppress it.
youtu.be/xkPbV3IRe4Y

YouTube
English
swiderek retweetledi

I'm Boris and I created Claude Code. Lots of people have asked how I use Claude Code, so I wanted to show off my setup a bit.
My setup might be surprisingly vanilla! Claude Code works great out of the box, so I personally don't customize it much. There is no one correct way to use Claude Code: we intentionally build it in a way that you can use it, customize it, and hack it however you like. Each person on the Claude Code team uses it very differently.
So, here goes.
English
swiderek retweetledi

New research just dropped: this prompting technique cuts AI hallucinations by 50%.
It's called Model-First Reasoning.
Instead of asking "How do I solve [xxx] problem?"
You first force the AI to list: what's involved, what can change, what actions are possible, and what's not allowed.
THEN you ask it to solve using only what it wrote down.
So what makes this different from Chain-of-Thought?
CoT lets the AI think and solve, but at the same time.
It sounds smart. It flows well. But it makes stuff up along the way.
Model-First Reasoning creates a hard wall instead.
Define first. Solve second. No mixing.
The AI can ONLY use what it wrote down in step one. That's the trick.
The researchers tested it on medical scheduling, route planning, resource allocation, and logic puzzles.
Same pattern everywhere: fewer broken rules, more consistent outputs.
Why it works:
✦ LLMs make things up because they assume stuff you never told them.
✦ When you force them to write everything down first, there's nowhere to hide.
✦ It makes a stronger case for why "Human-in-the-loop" works much better, too: we make sure every step is validated before going to the next.
You can read the paper here: arxiv.org/pdf/2512.14474.

English
swiderek retweetledi

OpenAI, Anthropic, and Google AI engineers use 10 internal prompting techniques that guarantee near-perfect accuracy…and nobody outside the labs is supposed to know them.
Here are 10 of them (Save this for later):

English
swiderek retweetledi
I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.
English
swiderek retweetledi

swiderek retweetledi
I love the expression “food for thought” as a concrete, mysterious cognitive capability humans experience but LLMs have no equivalent for.
Definition: “something worth thinking about or considering, like a mental meal that nourishes your mind with ideas, insights, or issues that require deeper reflection. It's used for topics that challenge your perspective, offer new understanding, or make you ponder important questions, acting as intellectual stimulation.”
So in LLM speak it’s a sequence of tokens such that when used as prompt for chain of thought, the samples are rewarding to attend over, via some yet undiscovered intrinsic reward function. Obsessed with what form it takes. Food for thought.
English
swiderek retweetledi

swiderek retweetledi

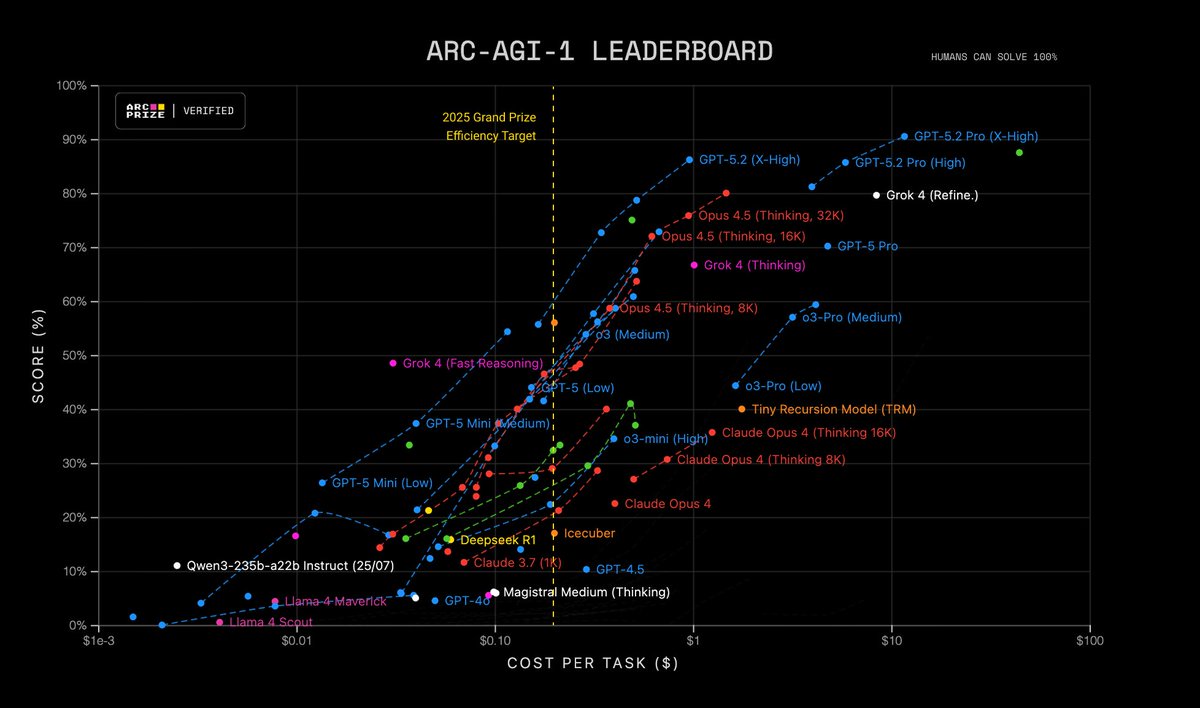
A year ago, we verified a preview of an unreleased version of @OpenAI o3 (High) that scored 88% on ARC-AGI-1 at est. $4.5k/task
Today, we’ve verified a new GPT-5.2 Pro (X-High) SOTA score of 90.5% at $11.64/task
This represents a ~390X efficiency improvement in one year
English
Chinese Hackers Use CloudScout Toolset to Steal Session Cookies from Cloud Services
#cloud #cybersecurity #hackers
thehackernews.com/2024/10/chines…

English
Azure VM internet access changes coming Sept 30, 2025! Default outbound access for Internet will be removed. Learn new routing options: Set “defaultOutboundAccess” to false & configure explicit outbound connectivity.
#Azure #Networking #CloudSecurity buff.ly/4eNg7Lu
English
swiderek retweetledi
here is sora, our video generation model:
openai.com/sora
today we are starting red-teaming and offering access to a limited number of creators.
@_tim_brooks @billpeeb @model_mechanic are really incredible; amazing work by them and the team.
remarkable moment.
English
swiderek retweetledi

Do you store your "DNS dynamic update registration credentials" in a DHCP?
Cute, it means I have a new tool for you 😁😈
Enjoy the DHCP Server DNS Password Stealer. The C source code, and the compiled exe, as usual: github.com/gtworek/PSBits…

English
swiderek retweetledi

Explore the frontier of AI with #Google's Gemini 👾. Dive into its revolutionary capabilities and what it means for the future of tech. 🔗 clouds.news/gemini #ArtificialIntelligence #Innovation

English
swiderek retweetledi
Ok, if Clippy Was Pregnant I think it would look like this 😂😂😂 #microsoft #openai #office #microsoft365 techcommunity.microsoft.com/t5/word/ok-if-…
English
swiderek retweetledi

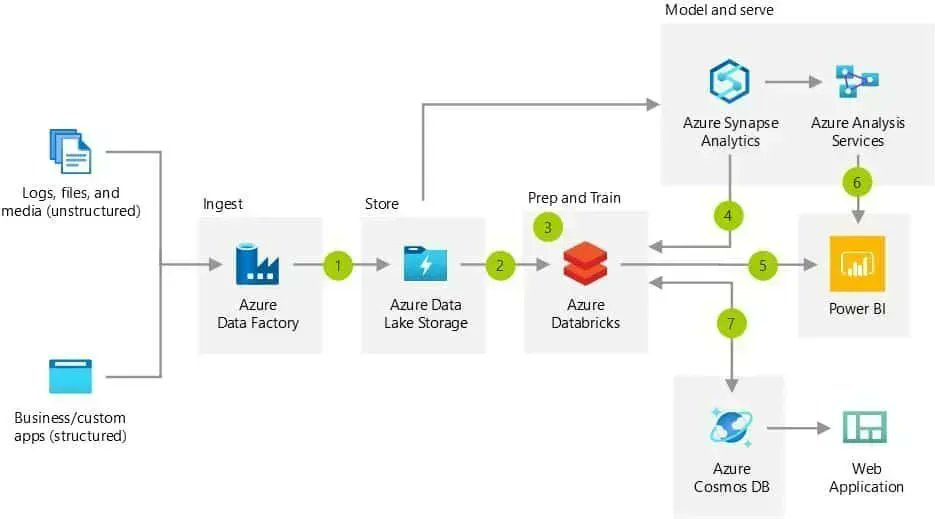
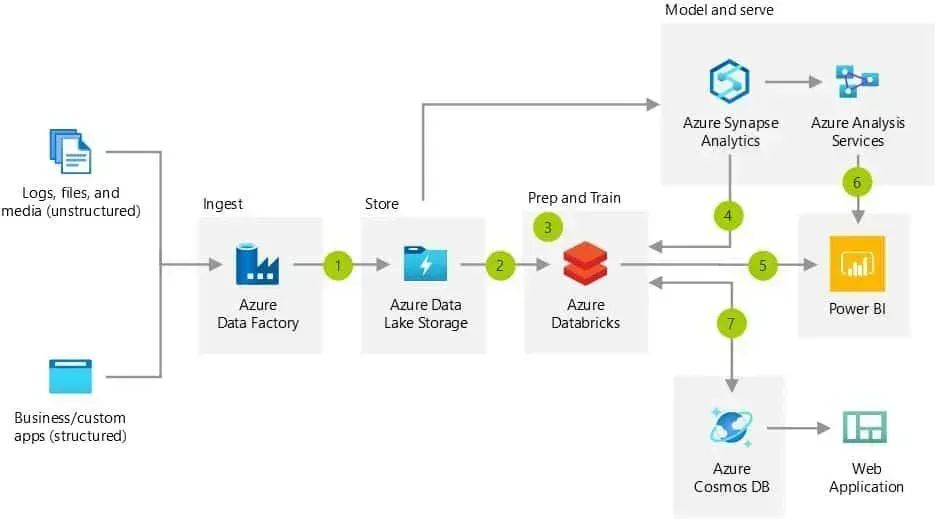
Need the Azure Icons to draw your architectures? Here is how to download the new Azure Architecture Icons ⚡
thomasmaurer.ch/2020/07/downlo…
#Microsoft #Azure #MicrosoftAzure
English