simmy sun
35 posts
simmy sun
@sysimmy
伪Geek,器材党,耳机控,背包控,常年收集电子垃圾,移动互联网关注者,坚信技术改变世界,IP 行业从业者,在曼谷开过玩具店,相信我是 AI 的 agent。
Katılım Aralık 2010
511 Takip Edilen21 Takipçiler





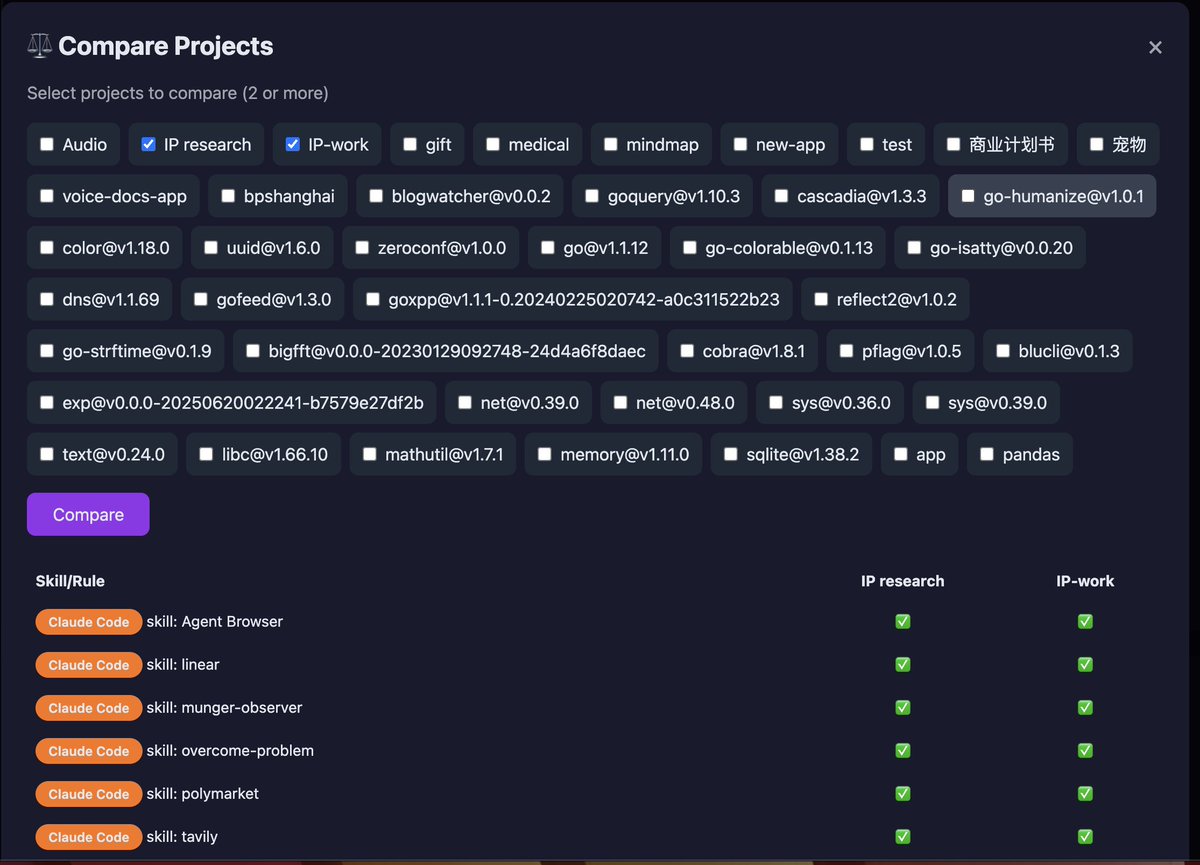
@jiunian github.com/sySimmy/excerp… 放在github上了,需要可以试试,让claudecode改一下未读和已读就行。英文翻译、打标、精读区都做好了
中文

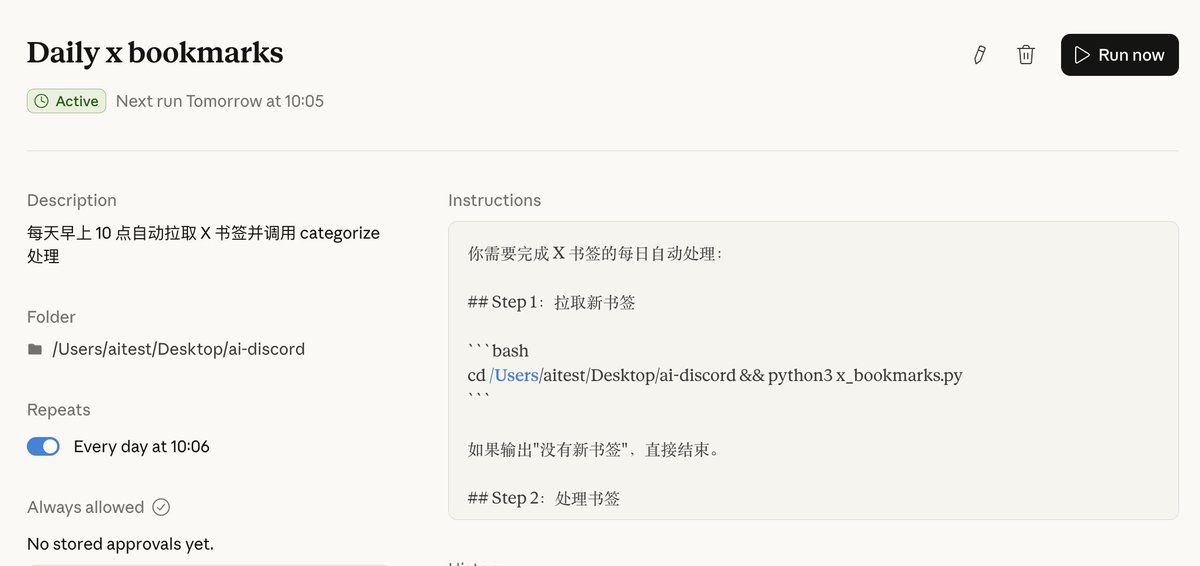
我把 X 书签接进 Obsidian 知识库了,全程不用 API Key,没有第三方插件,每天自动跑。
分三个阶段,思路是这样的:
阶段一
---------------------
手机 / 电脑收藏推文(跨设备同步)
↓
每早十点自动触发脚本(cc定时任务)
↓
用Cookie 调 X书签,增量拉取,拿回书签的 JSON 数据
↓
提取新书签 URL,写入 00_收件箱/Twitter-URLs.md
↓
更新 processed_ids.json,记录已处理 ID
↓
触发自建skill
阶段二
---------------------
自建skill触发
↓
对每条 URL 走三级降级:① fetch_tweet.py --url:结构化 JSON,拿原文 + Quote Tweet + Thread | ② r.jina.ai/[URL]:自动转 Markdown |
③ WebFetch:最后兜底→全败 → 标 UDF,等手动处理
↓
cc 按模板生成文件前缀+笔记+正反向链接
↓
清空Twitter-URLs.md
↓
确认继续操作
阶段三
---------------------
确认继续操作
↓
读文件前缀,分流到对应目录
↓
更新各目录的检索
↓
结束
至此,一个总结分类推文的自动化工作流程就结束了。
其实这三个阶段的流程,是可以缩减为两个阶段,甚至合并为一个阶段的,还是得看具体的需求去调整。
思路已经提供在这里了,具体的细节我还需要再调试。如果之后能够把它封装成一个 Skill,我会分享出来。
玖年🌿@jiunian
想达到这个目的,需要两点: 1. 收藏变成笔记,总结分类的自动化工作流 2. 笔记变成知识的流动系统和奖励机制 前者我做好了, 过几天分享下思路
中文





在新到的Macmini上安装OpenClaw,但到了最后还是有各种奇怪的问题,阻塞了一小时了。现在让Codex在解决问题。。。 我做了汉化版的Longxia,但因为着急先把X的相关服务部署好,所以没直接用自己的改良升级版。现在看来,手里还是少一个macOS的设备,仅管有了顶配的M4 Max 128G/8TB 的Macbook和M4的Macmini,但还少一个测试环境来用的macOS设备。。。 干IT的,也挺烧钱的。
中文
simmy sun retweetledi

This chart is a good reminder of how much opportunity there is in AI agents right now.
There will be plenty of horizontal opportunities for agents, but equally many workflows that need deep domain expertise to actually make the user successful at automating the unique processes in their vertical.
The template is to build agentic software that taps into proprietary data, handles the workflow in a way that bridges the user and the agent collaboration effectively, and has a deep domain-specific context engineering, and the ability to drive change management for customers.
There still are huge openings in many categories.

Han Wang@handotdev
what I would be working on if I started another company today
English