
tancool
1.2K posts

@tancool_ @NateWitkin Aren’t most of the harnesses reusable with just changing the context you feed it
English

As time goes on, I become more and more confident in two key sources of AI forecasting error:
1. Overindexing on power-users.
The majority of LLM users are about as likely to get a net-negative as a net-positive outcome from AI due to a mix of sycophancy, hallucination, workslop-related productivity decline, and plain distraction and misuse. This has large implications for macro outcomes (GDP, employment, productivity, etc.).
2. Underestimating political and cultural backlash.
Only 46% of people are "willing to trust" LLMs (KPMG). Only 17% think Americans think AI will have a positive impact on the U.S. (Pew). Local opposition to data centers exploded in 2025. And the populist wings of both parties are gearing up to make AI opposition a pillar of their platforms in 2026 and beyond.
And this is all before we've experienced any major AI-related disruptions. If we begin to see steeper employment declines or electricity price increases, even very concentrated ones, opposition will ramp up very fast, with potentially large impacts on both scaling and diffusion.
Two takeaways.
First, forecasts accounting neither for the average person's LLM use habits, nor the prospect for major sociopolitical backlash are incomplete and not to be taken at face value.
Second, the most effective / powerful sorts of LLM use are and will continue to be concentrated among small, elite groups. Forecasting is therefore overweight on bloated 'what will AI do to society' questions and underweight on concrete 'will x group achieve y outcome' questions.
English
@willdepue Labor is already not necessary but something society actively chooses to have. Why do thousands of people need to work at a company whose job it is to get overpriced restaurant food delivered to your doorstep?
English

the agi pitch of ‘it will solve cancer’ is unfortunately weak because i would gladly trade having to risk cancer vs me and all my descendants losing all economic utility until the end of time, obviously
agi world needs to just miraculously great to counter losing all labor value
English

If you are seriously AGI-pilled, then one weird implication in the limit is that “talent” seemingly stops mattering as much for company success. It just becomes a game of hard power: access to the very best AI models, compute, data, land, etc.
Andrew Curran@AndrewCurran_
If OpenAI and Anthropic both finished training surprisingly capable large models at roughly the same time in early March, then this is potentially purely a result of scale. Q1 2026 was just the first time anyone had enough compute to train at this level. If this really comes down to how fast, and to what extent, you can scale physical infrastructure, then I think it probably becomes very difficult to beat Elon after around 2030. If the race goes that long, and we are still pre-transformative, he will just keep ramping up physical constructs. He will literally build a datamoon if that's what it takes to win a contest of scale. If orbital datacenters work, he probably also wins that way due to SpaceX. Mark Zuckerberg is just as scale-pilled. Last year, when he was pressed on capex during the earnings call, he said that he would rather overbuild now than risk missing the next leap that requires 10x more compute to train. The last eighteen months have shown how valuable top human talent in this industry still is, but even senior people at OpenAI and Anthropic now say openly that they do not know how long they themselves will still have these jobs. Once automated researchers are superhuman, top talent will be supplanted by how many super-researchers you can run simultaneously. It will be difficult to beat Elon and Zuck at this game by the end of the decade. This is what Stargate is for, but will it be enough? Against xAI, META, Microsoft, and Google, it seems that OpenAI and Anthropic have to blitz now; reach a sufficient capability threshold to surpass the human level, then automate as much of the economy as possible as fast as possible before they are outbuilt.
English

You must understand that every tech executive has AI psychosis
They’re puking out Claude-generated markdown files full of hallucinations asking if this means they can fire 500 people
They’re turning Google sheets into the shittiest vibe-coded apps in the world
English

Hyperacceleration is already starting to happen in theory fields. A very small number of people, who are very talented, and also good at using AI to prove stuff, are increasingly going to run entire fields. The second-tier of researchers is going to become totally irrelevant
English
"Writing is important because it helps you think"
Writing is an inefficient and antisocial way to think. The best way to think is to debate ideas with other smart people. Talking with an LLM pretty much replicates this, and is thus a strictly better way to think than writing
English
@alexolegimas Is this really positive? Where “everyone only works 3-4 days a week” and jobs are only in human services? Sounds terrible.
English

This is exactly the positive vision that I would outline. The last part in particular:
“Baumol's cost disease is a feature not a bug: the relative expense of human services stops being a budget problem and starts being a labor market solution. That is where the jobs are, and they're jobs worth having.”
Saffron Huang@saffronhuang
Here's a plausible positive scenario that doesn't require many further AI advancements. I wanted to clearly paint the path "from here to there" instead of hand-waving so it starts out negative but ends positive (I swear): A recession leads to slowed hiring and a breakdown of the early-career ladder. The political window opens for industrial policy on AI: governments encourage firms to launch apprenticeship programs to bridge the training gap between junior and senior white-collar roles, instilling discernment and judgment of AI outputs. Programs help reshuffle people with clerical jobs into education (especially elementary and middle school 1-1 tutoring) or nursing (and given AI tools to upskill into providing clinical care). Those with a risk-taking or strategic bent become entrepreneurs and executives overseeing AI agents. Industrial policy is important, but AI also helps to decrease regulatory and compliance burdens on construction; this sector expands, and the built environment starts improving (e.g. high speed rail becomes more possible). Later on, material abundance (robot manufacturing) means that goods are cheap and easier to manufacture domestically. Most people's spending is therefore on human-led services, today's luxuries. For example, high quality education: schooling in many places (including the US) has historically been low quality for most, with many knock-on effects. 1-1 personal attention by human teachers (for younger students) + AI personalized tutoring (for older students) bridges this gap. Everyone is healthy: cheap AI triaging of medical issues lowers the barrier to preventative as well as life-saving care. Entrepreneurship is enabled by easy access to AI agents. The bar for customer service is raised all-round (high-end retail and hospitality services, like what you see in Japan). Everyone works 3-4 days a week. Baumol's cost disease is a feature not a bug: the relative expense of human services stops being a budget problem and starts being a labor market solution. That is where the jobs are, and they're jobs worth having.
English

Narrative violation: young tech workers now have job finding rates on par with older workers
Callum Williams@econcallum
Important update: entry-level jobs in tech are no longer hard to find. Young tech workers have the same unemployment rate as tech workers overall.
English

The impact of AI on an industry depends on the elasticity of demand.
If the price to produce software goes down, the demand skyrockets.
Tax accounting or insurance brokerage? Not so much.
English

Conventional economic theory never accounted for intelligent machines that can do the equivalent of weeks of human work in minutes or seconds.
English

Jevons paradox is happening in real time. Companies, especially outside of tech, are realizing that they can now afford to take on software projects that they wouldn’t have been able to tackle before because now AI lets them do so.
We’re going to start to use software for all new things in the economy because it’s incrementally cheaper to produce. Marketing teams at big companies will have engineers helping to automate workflows. Engineers in life sciences and healthcare will automate research. Small businesses will hire engineers for the first to build better digital experiences.
And as long as AI agents still require a human who understands what to prompt, how to review when an agent goes off the rails, how it guide back, how to maintain the system that was built, how to fix the ongoing bugs, and more, we will still have humans managing these agents.
This is why all the advice you get of not going into engineering is wrong. The world is going to increasingly be made up of software, and the people that understand it best will be in a strong economic position. This will happen in other roles as well where output goes up and demand increases.
Lenny Rachitsky@lennysan
Engineering job openings are at the highest levels we’ve seen in over 3 years There are over 67,000 (!!!) eng openings at tech companies globally right now, with 26,000 just in the U.S. We don’t know if there would have been more open roles if not for AI or if AI is actually leading to more open roles, but since the start of this year, the increase in open eng roles is accelerating even more.
English
A decade or so ago, computer scientists started invading statistics with their fancy "machine learning" stuff. This pissed off the statisticians to no end, since the CS guys renamed everything, ignored most of the statisticians' work, etc.
ludwig@ludwigABAP
Everyone who is currently bombared by "solve math solve everything" "autoformalization -> AGI" psyops should read this and try to understand where this sentiment comes from
English
@ChaseBrowe32432 This study reassures me about the role of humans in research in the future. A totally “good looking” AI paper turned out to be absolutely unhelpful and misleading when you look at nuance. Anyone can vibe research but humans still retain ability of nuance on the big questions.
English

I painstakingly ran all 20 EsoLang-Bench hard problems through Claude webui. It solved 20/20 (100%).
No specialized scaffolding, no expert prompting, no few-shot examples, it just solves them natively.
This benchmark just suffocated the models with constrictive scaffolding.
Lossfunk@lossfunk
🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%. Presenting EsoLang-Bench. Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵
English

It really is like being an ML engineer
- how much compute to spend?
- when outputs are stochastic, how to measure & test?
- how do I run experiments?
- looking at data to form better hypotheses
ML engineers are so back
Thariq@trq212
an increasingly large part of the job of an engineer is deciding how much compute to spend on a problem
English

Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanoc…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

English
@Anubhavhing As cool as this is, this is an obviously automated part of research, it’s simple config/code changes! The main brain power here is on what the framework for experiments is, what data to use, what the questions are, etc.
English

Are you paying attention right now?
Karpathy just open-sourced a repo where an AI agent runs its own ML research. Autonomously. In a loop. While you sleep.
630 lines of code. Every dot in the graph is a full LLM training run.
The AI picks the architecture, tunes the hyperparameters, commits the code, and starts again.
No human involvement.
You spent 6 months on a Udemy course learning to tune learning rates.
This agent does it 50 times before your morning coffee.
The guy who taught the internet deep learning just automated the researcher.
ML PhDs are about to find out their dissertation was a 5-minute training run on a single GPU.
Andrej Karpathy@karpathy
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)
English

I'd like to answer questions about our work with the DoW and our thinking over the past few days. Please AMA.
English
@srini_hariharan Most people misunderstood what Sam said. He said that it hopeless for small startups to compete with OpenAI on building *SOTA proprietary foundation models*. That prediction has held true, where other than the top 3 no small startup is even close or trying to catch up.
English

I will be honest, i remember Sam Altman's comment few years back when he came to India, dismissing any thoughts of Indian sovereign models. I remember grudgingly accepting what he said. I was horribly wrong.
Thanks to Sarvam, IITM (and the GoI who backed them). Super bullish now
English

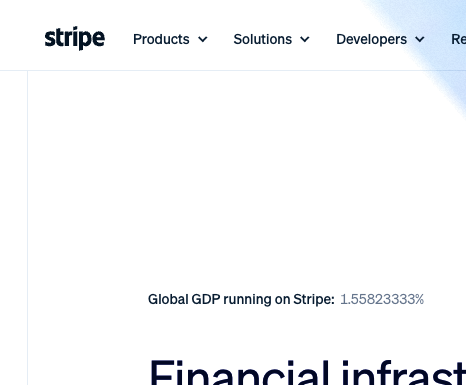
Stripe's new frontpage shows the scope of their ambition. A ticker for percent of global GDP! This is not a gimmick. Patrick and John have always thought in these terms.
English