
tears lee 绿柚子
916 posts

tears lee 绿柚子
@tears_lee
平平无奇的小透明/0.2%的右派0.8%的自由主义/素食喜辣/沉默观测/让子弹飞一会儿/现实主义/如果我爱国,爱到失业、衣食无着,那就叫不可持续爱国
Sichuan Katılım Ekim 2017
161 Takip Edilen32 Takipçiler

@janson282 @cuichenghao 建议爱美国的人平时发帖和评论要用英语,不要混在简体中文圈了,你这样思想还是在跟中国人打交道,怎么能顺利顺畅的融入西方文化中呢?
中文




@jooney0909 @cheatyyyy 1.你不懂api中转站,你也不明白什么叫system prompt
2.也不懂婊子立牌坊这个词怎么用。
中文




習近平が高市早苗に対して持つ強烈な嫌悪感は、ハンナ・アーレントが警告した嘘の帝国のアイドルに対する、現実世界の住人が持つ絶望感だと思う。
現実を無視し、言葉のトリックだけで世界を騙せると思い込み、国内の権力闘争と海外への挑発を同じ軽さで行う。
その凡庸さを極めた高市政権の精神性に対し、こいつらとは一切の外交交渉が成立しないと絶望し、激昂した。
何より、日本人の生活を窒息させている張本人のトランプに擁護されて喜んでいるという、言い表す言葉も思いつかない日本の政治中枢のむなしさ。
James F. ガメ・オベール@gamayauber01
面白いことに習近平には珍しく激昂して怒りが抑えきれない様子だったという 「怒ってみせた」わけではないらしい 感情を隠せないほど嫌悪が募るなんてことが、習近平にもあるんだね なぜなんだろう
日本語

They're not actually that cheap
I'm burning through $3-5/day on DeepSeek. So, this is comparable to ClaudeMax subscription. Yes, it's hundreds of millions of tokens (mostly cache hits), but tokens flow fast with agents.
I hope they'll figure out how to use these traces.
J A Z I I@notjazii
AI price war is getting brutal > deepseek made its v4 Pro model cheaper for good > xiaomi’s mimo v2.5 Pro dropped prices by up to 99% at this point Chinese AI labs are basically giving intelligence away but wait how do these companies even make money when the models are this cheap?
English

@2chocolatebar @angeloinchina 美国呢,美国这个穷兵黩武的国家,一直在仗着军事和经济霸权欺负全世界,中国的国防开支是为了防备美国,并不是什么日本,菲律宾。在中国眼里,日本和菲律宾不堪一击,如果中国像美国那样好战而不是爱好和平,日本和菲律宾已经亡国了
中文

@angeloinchina You are the one using misleading data to avoid the main argument. Which is China’s concern over Japan’s military spending. China is spending increasingly more compared to JPN. Yes GDP percentage remains low but it doesn’t mean their military isn’t getting an upgrade.
English

Defense spending in percent of GDP 2026
China 1.7%
Japan 1.9%
USA 3.5%
Don’t fall for misleading graphs/datas.
Be informed/not entertained.
Rush Doshi@RushDoshi
Presented without comment.
English
@teortaxesTex 用GDP分析中国经济已经没有多大作用了,某种程度上中国这种数据分析会偏离经济规律。中国人贫富分化,收入差距过大确实是不争的事实,不应该忽略
中文
this sounds terrifying lol. It means they won't need any immigrants to continue crushing it for another decade. At this rate of skull charts📈📈, they'll put half the world out of business.
> Japan achieved a highly uniform, structurally sound, high-income society
and what of it?

UnveiledChina@Unveiled_ChinaX
China’s dazzling coastal skylines are a magnificent illusion masking a deeply fractured, economically divided nation. A data-driven report from The Economist completely dismantles the myth of China as a unified economic powerhouse, exposing a jaw-dropping internal chasm. The analysis reveals that China’s four richest cities, boasting a combined population of 84 million people, now command a nominal GDP per capita that exceeds Japan's national average. Yet, in stark contrast, its four poorest provinces, home to 140 million citizens, languish with per capita incomes closer to Vietnam. This internal chasm provides Beijing with a highly disruptive global trade advantage. Economists refer to this as a demographic "pterodactyl's downdraft," a massive force crushing traditional economic development models. Unlike historical economies that gradually abandoned low-end manufacturing as their coastal cities grew wealthy, China retains it all. Because of its massive regional wealth disparity, China can simultaneously run world-class, high-tech semiconductor hubs in its coastal megacities while utilizing its deeply impoverished inland provinces as low-wage, state-subsidized labor engines. It behaves like a developed Western nation and a struggling emerging market all at once. However, comparing China's absolute peak performers to Japan’s national average obscures the reality of true economic development. When evaluating peer-to-peer urban performance, Japan’s leading metros continue to decisively outperform China's premier hubs. While Beijing and Shanghai hover around $32,000 to $33,000 in nominal GDP per capita, Tokyo Prefecture towers over them at $48,000 to $52,000, with secondary Japanese centers like Kanagawa and Osaka also comfortably beating out China's top tier. Japan achieved a highly uniform, structurally sound, high-income society. China, conversely, remains a fragile economic paradox, masking hundreds of millions of low-income citizens behind the dazzling, state-funded facades of a few hyper-developed coastal fortresses. #UnveiledChina #ChinaInequality #TheEconomist #EconomicShock #SupertankerSuites #TokyoVsShanghai #GlobalTrade #TwoChinas
English


@MSZE15 这也算严厉吗?她去越南去澳大利亚,跪拜当地的纪念碑,只是为了反驳中国的指责她“右倾军事化日本”。给国际社会一股糊弄的操作即跪拜“靖国神社”= 跪拜“英雄纪念碑”。 但是靖国神社里未被移除的甲级战犯表明这种操作毫无作用,只是表演罢了
中文



王丹豪的自杀,是隐藏在大科技公司、新闻媒体和科研机构中的中共渗透网络所造成的一个极端后果。
我来到美国之后,才更深切地体验到,中共的触角确实无处不在。
但由于美国有法治与人权制度,美国不可能像中国那样直接枪杀所谓“间谍”。2010年至2012年间,据报道约有30名CIA特工和线人先后在中国遭到杀害、逮捕或监禁。
当年我在中国某门户网站担任主编,曾接触到大量后台新闻,也见过关于美国CIA线人被当众枪杀的报道-----据称是在某市政府大院内发生的。
在美国,间谍案件不可能被立刻以枪杀方式处理,除特殊危机事件外,通常都必须经过完整的法律程序和公开审判。
而在法治和人权保障较强的国家里,证据的收集、整理和呈现都极其复杂。自2025年至今,我一直遭受傅希秋团伙的污蔑和多种袭击;向美国执法机构举报,也必须提供完整、清晰、可核实的证据。
这类工作远远超出一般个人的能力范围。
与此同时,还必须突破并防范傅希秋团伙在美国国会、国会警察局以及多个联邦执法机构中可能存在的人脉和关系网络。
在美国,几乎没有华人敢召集两位美国公民,去伪造某人是中共统战部特务的指控;但傅希秋却做到了。他甚至还找来十多名特工,对我进行没有正式手续的调查。
这正是美国现实的一部分:由于人权与法治的存在,执法系统对证据的要求极其严格。
这种环境也使得学术机构、新闻媒体和大科技公司的后台,可能存在更隐蔽的中共控制网络。
例如,推特公司后台很可能已经受到这类网络人员的污染。我录制的下面段截屏显示,中共为我定制了大量水军账号,这些账号只为我一个人注册,针对我一个人抹黑,他们甚至嘲笑我已经没有流量了。
推特显然对此知情,却始终拒绝承认所谓“影子操作”。无论我如何投诉,都没有结果,因为这触及了推特最根本的价值底线,也直接揭示了大科技公司背后的黑暗面。
这就是中美之间的现实:王丹豪的自杀,是中美利益冲突下的一个悲剧性结果。
我也相信,那些在推特上打压我、限制我言论自由的中共眼线,终有一天会被CIA或FBI调查。
但我希望你们不要步王丹豪的后尘,你们必须接受法庭的公开审判。
我同样会把那些污蔑我人格、并持续袭击我一年多的傅希秋团伙成员,依法举报并追究他们的刑事和民事责任。
我不惧中共水军、推特后台暗线以及傅希秋团伙支持者的压力,我会把真相通过法律程序更清晰地呈现给世人。


赵兰健 Lanjian Zhao@uyunistar
Yes, only with an honest conscience can one calmly face any investigation. At the end of 2025, I was subjected to long-term slander by Bob Fu's group(Xiqiu Fu group), labeled a "CCP United Front Work Department spy," and consequently underwent informal investigations by more than ten agents from various US law enforcement agencies. I always cooperated fully and proved my innocence. I will never commit suicide—because I firmly believe in the rule of law system in the United States based on the separation of powers and checks and balances.
中文

日本电视台拍过一个叫木村风斗的24岁软件工程师,把他包装成"年薪3万美元也能活得很好"的国民榜样。记者跟着他回了家。
很小的公寓。他对着镜头说,自己觉得舒服的室温是29度——因为空调太贵了,舍不得开。
这段视频48小时播放了300万次。二十多岁的日本年轻人在转发:看,工资不高也能过得好。父母也在转发:看,咱家孩子没问题的,放心。
然后有人在评论区写了一句话:暂停在1分16秒。
停在1分16秒。别看他表情,别看桌上那个碗。看酱油瓶后面那台笔记本屏幕。
屏幕上那个标签页,不是他的银行账户。是一个实盘钱包。
ID:gabagool22。利润:86万8862美元。2025年10月注册的。
他跟电视台说自己靠一年3万美元过日子。桌面上那个钱包,4个月赚了86.8万美元。28620个仓位,全是比特币,全部跑15分钟窗口,全绿,一笔亏的都没有。
评论区直接变成了侦探现场。有人把视频放慢到0.5倍,一帧一帧截下笔记本入镜的画面,拼在一起,从4秒的背景镜头里完整还原出了那个钱包页面。
进场价2到10美分,兑付金额几千美元。28620条记录,没有一行是红的。
最大的一笔赢了4696美元,来自某个周二早上一个15分钟的窗口。
29度不是因为他真的心疼空调。29度是为了让电视台相信他的穷。他每隔一天就把空调开到最大,只有摄像机来的那个早上才关掉。
地上那碗面不是他的晚饭。晚饭在楼上吃过了。那个碗是他开拍前一小时在便利店买的道具。
那双带洞的鞋是他专门藏在床底下的。衣柜里全是好的。
他不是什么"年薪3万也能活得好的榜样"。他是一个在电视台面前把86.8万美元藏得滴水不漏、配合演出了一下午"穷工程师"的榜样。记者想要一个感人的故事,他就给了一个。
原片300万播放。笔记本的放大截图,又有150万播放。
日本观众还在转发,还在感动,还在省空调费,还在信。
他还在交易。那个代理还在跑。那个碗早就放回便利店货架上了。
故事讲得越漂亮的地方,钱包越小。故事讲得越少的那个,钱包越大。他只是假装穷了一个下午而已。
中文


郑丽文强硬表态:军购案,3800亿+N就是党版!党内很多同志一直跟我讲,美国军售第二批马上就来了,所以先匡算8000亿。我从去年11月就听说要来第二批,听到现在,怎么还没来?现在台北已经是军火商满天飞了,这增加的约4000亿预算,真的是要买美国政府军火吗?还是未来不明不白就买了别的军火商的东西?我这一下,挡了多少人的过路财?我知道党内很多同志有压力,那丢给我来扛就好了。民进党说我们卖台,我们就是卖台吗?我们没有嘴,不能说清楚、讲明白吗?台湾的价值,真的就仅仅局限于军购吗?台湾不接受这笔军购,在美国眼里就毫无价值了吗?当然不是这样!绝对不是这样!也一直不是这样!
RJ@RJDAIGOGO
国民党中央连夜发文,隔空叫阵赵少康:3800亿+N的军购方案就是“党版”,是党中央开会决定的!(具体内容见评论区) 赵少康假日召集记者,隔空叫阵党中央:季麟连必须开除!幕后指使者必须揪出来!既然是党版,为啥又要开会讨论?讨论了有人不同意你们又不听?以前党版也改过,况且民众党到时候提出来的跟你们的不一样,你们改不改?郑习会累积的一点红利,眼看就这样被消耗了,真的很可惜!
中文




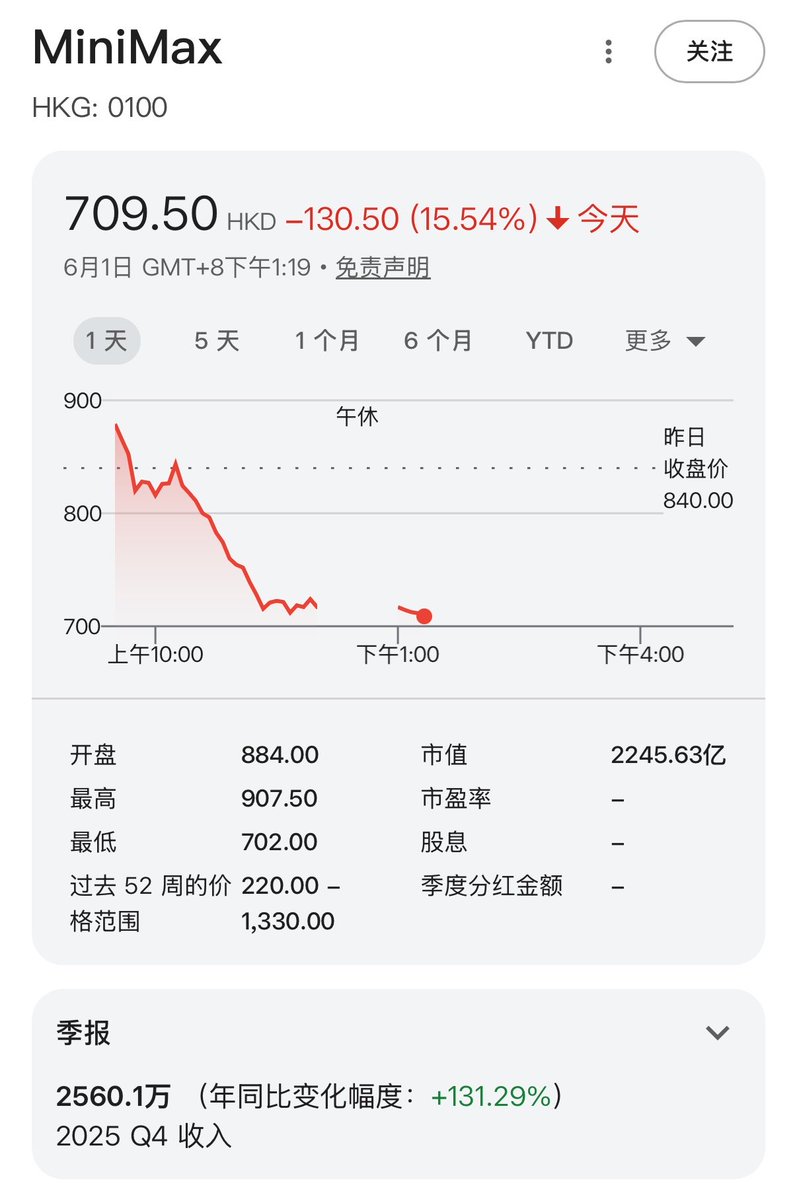
字节跳动前员工爆料中国头部AI公司内幕,和我的看法基本一致:
1)他认为中美 AI 差距在扩大不是缩小。
2)蒸馏走捷径很普遍。
3)训练用的都是英伟达的卡。
4)国产的AI Agent完全不实用。
思维怪怪@0xLogicrw
张驰,浙大本科,UCLA 博士(导师朱松纯),2025 年加入字节 Seed 做数学推理,干了一年后离职去北大当助理教授。最近上播客 Into Asia 回顾了在字节的一年,不少判断跟目前的公开叙事直接冲突。 他的核心观点: 1. 字节跑完一轮完整迭代(预训练+后训练)要大约半年,谷歌据传三个月。他认为迭代速度差距是追不上的根本原因。 2. Seed 内部 benchmaxxing 严重。领导按 benchmark 分数考核,大家都在刷榜,但他说纸面追平了不等于真的好用,「实际体验不行」。 3. 2024 年底 Seed 自认追平了 GPT-4o,结果 DeepSeek 一出来才发现差距还在。他入职时全组紧急转强化学习。 4. 他认为中美 AI 差距在扩大不是缩小。原话:「我甚至不同意中国在追赶这个说法,我们仍然远远落后。」同事和学生同意,但智谱、MiniMax 这些上市公司的领导层不会同意。 5. 蒸馏走捷径很普遍。很多公司直接调 Claude/GPT/Gemini 的输出当训练数据。不过他也承认 DeepSeek 在 V3/R1 上有真正的架构创新。 6. 字节主力芯片是 NVIDIA H20,最快的卡留给预训练和后训练团队。国产芯片有但没人用于训练。字节在海外采购新一代 NVIDIA 芯片,但「肯定不在中国大陆」。 7. 美国公司有用户反馈飞轮,模型好用→用户多→反馈好→模型更好。中国模型起步差,没人愿意用在重要工作上,数据拿不到,恶性循环。 8. 他在谷歌实习时觉得基础设施「太好了」,跟字节差距巨大。不只是芯片,训练框架和整个基础设施都差一截。 9. 中国 AI 从业者普遍用美国 Agent 工具。他自己用 Claude Code 和 Copilot,中国模型的编码 Agent 他评价「完全不实用」。字节海外团队直接用 Cursor。 10. Claude Code 好用到让他在想还要不要培养博士生,但又怕不培养下一代,以后没人做研究。 背景补充:张驰在字节只待了约一年,所在的数学组他自己说偏宣传性质,不在核心的预训练/后训练团队。他的观点是个人视角,不代表字节全貌。
中文

美国芯片禁售这事可能已经变成一根筋两头堵了
4月24日,DeepSeek V4正式发布,并且宣布V4在华为昇腾上完成了验证和首发适配。 技术报告里明确写了,V4的细粒度专家并行方案,在英伟达GPU和华为昇腾NPU两个平台上都验证通过了。
推理侧已经实打实地跑在了国产芯片上完成了国产化适配,训练侧仍需英伟达,但使用昇腾卡训练模型这件事已经完成验证,架构上已经把适配昇腾的路铺平了。
而就在几天前,老黄在播客中直言:"如果DeepSeek先在华为平台上发布,那对美国来说将是灾难性的。" 虽然目前来看训练主力还不是昇腾,但V4这一步迈出去,黄仁勋担心的那个方向,确实被踩出了第一个脚印。
在黄仁勋看来,出口管制非但没遏制住中国,反而逼出了一个在架构和生态层面逐渐摆脱对英伟达依赖的自主体系。他在播客里甚至直接说美国的做法"极度愚蠢",是在人为制造两个割裂的AI世界—一个是跑在美国技术栈上的封闭生态,一个是跑在外国技术栈上的开源生态—最终受损的恰恰是美国自己。
实际上就在V4发布前一天,美光正在华盛顿积极游说国会通过"MATCH法案",要把管制范围扩大到设备维护和售后服务,甚至计划在中国境内全面收紧浸没式DUV光刻机的供应。
那么,对美国来说,有没有更好的选择?
如果美国换一种策略呢?不禁售了,改成低价倾销,用价格优势压住中国本土芯片的成长空间,这种打法是不是更"聪明"?
过去或许有类似成功案例。但放在今天中美AI竞争的语境下,我觉得这条路同样走不通。原因很简单——中美之间有一道无法逾越的成本鸿沟:电力。
AI时代,算力的背后就是电力。一个数据中心,电力成本能占到运营总成本的40%到55%,AI训练集群的能耗占比甚至更高。这意味着电价直接决定了你的算力成本,进而决定你大模型训练、推理的竞争力。中国在一些电价控制水平上,特别是能源基地所在的地区,往往只有美国的三分之一甚至更低,不少地方还有专门的数据中心电价补贴。在同等规模的算力中心运营中,仅电力成本这一项,就构成了几乎无法追赶的代差。
先说数据。 美国今年计划新建的数据中心项目里,将近一半面临延期甚至直接取消。2025年美国数据中心项目取消数量从上一年的6个飙到25个,翻了四倍多。光是号称全美规模最大的PJM电网圈——覆盖从华盛顿到芝加哥13个州、承载美国近40%的数据中心用电量——就预计未来十年会出现60吉瓦的供电缺口,现货电价已经飙到每兆瓦时1000美元以上。PJM电网的数据中心并网等待时间,长的要排好几年,有的电网运营商甚至直接要求开发商"自带发电设施来",意思是:电你自己想办法,我这没有了。弗吉尼亚州北部那个全球数据中心密度最高的区域,备用电力短缺2023年全年才3次,2025年飙到19次,2026年头两个月就已经6次了,电价涨了61%,而且从冬季集中缺电蔓延到全年常态化。
再说案例。 微软为了让数据中心有电可用,跑去签了重启宾州三里岛核电站1号机组的协议——就是1979年出过核事故那个三里岛。那个机组2019年因经济原因关停,现在为了给AI供电,硬是被微软买断了20年的全部电力输出,美国能源部还给了10亿美元的联邦贷款支持。但即使这样,因为输电工程滞后,全面并网可能要推迟到2031年,比原计划晚了四年。
Meta的做法更直接——直接拍板在路易斯安那州给它最大的数据中心新建三座天然气发电厂,满负荷发电2.25吉瓦,随着算力持续扩建,电力需求最终要上到5吉瓦。至于环保承诺,暂时顾不上了。
OpenAI在德克萨斯州规划的多个大型数据中心园区,卫星图像追踪显示施工进度明显滞后。其中一个1.4吉瓦的项目,六处规划设施里目前只有一处出现了施工迹象,首批交付可能推迟到2027年底。
除了电不够用,还有一个特别讽刺的环节——电力设备造不出来。 美国想建数据中心,但连变压器、开关设备这些关键硬件都严重依赖进口。大功率变压器的交货周期从2020年之前的24到30个月,已经拉长到了最长5年,而AI企业的部署周期普遍在18个月以内——光等一个变压器就要等5年,黄花菜都凉了。美国虽然一天到晚在芯片上卡中国脖子,但美国建数据中心的关键电力部件,反而离不了中国的供应链。
你看,这就是美国算力建设的真实处境。不缺钱、但缺电、缺设备、缺工人,基建速度远远跟不上AI扩张的速度。
而中国这边呢?电不仅够,还便宜。中国部分地区给数据中心补贴后的工业电价可以低到每千瓦时不到四毛钱。西部那些能源丰富的省份——甘肃、贵州、内蒙古——已经成了数据中心扎堆的热门地区。"东数西算"把算力中心布局在能源基地旁边,电从源头直供,成本优势巨大。
现在我们可以回到那个假设了:如果完全没有出口管制,美国的科技巨头们会怎么做?英伟达可以敞开了卖,但买得起芯片是一回事,跑得起算力是另一回事。他们很快会发现,在美国本土扩建数据中心又贵又慢——电不够用,变压器要等好几年,并网还要排队。而到了中国,电价低、基建快、供应链齐全。带着最先进的芯片和技术到中国建算力中心,才是最"多快好省"的商业选择。
实际上即使禁售拦住了销往中国的路,美国的巨头们也早就在往其他国家跑了。他们需要更便宜的电、更快的基建、更宽松的建站条件,这些东西美国本土恰恰给不够。
但是海外建算力中心,门槛远比想象中高。 不是随便找一个国家就行,能源、基建、电力设备供应链这三个硬条件缺一不可。比如说日本有280亿美元的AI数据中心投资热潮,但因为电网扩容跟不上,数据中心并网可能要排十年队;西班牙阿拉贡那个900亿美元的AI数据中心项目虽然规模巨大,但选址和当地社区产生了矛盾,推进并不顺利。
所以到头来不管禁不禁售,美国的电力短板都是客观存在的。 不禁售,资本会为了逐利流向中国的能源洼地,用自己的先进芯片养肥中国的AI产业。禁售了,结果我们也看到了,中国企业用实力证明自己能在美国的制裁下打造出一套不依赖美国的独立生态。
要我说,牢美这就是伸头是一刀,缩头也是一刀。怎么都得死,无非是长痛还是短痛。

中文

you got pissed over this, this is the joke. other stuff is only what i think is true. the comment you highlited now is not western propaganda, even chinese people who know what s happening with llms think it might be true, as i said it might be true but not 100%, but it s a legitimate claim. if your job is to defend china against western propaganda, it s better to be objective
English

This is what Jensen Huang actually fears.
Not losing a few chip sales.
Not one export-control hearing.
Not even one strong Chinese model.
What he fears is China turning open models into the center of a different AI stack — one optimized for domestic chips, domestic deployment, and eventually global diffusion.
Chips can be replaced.
Ecosystems are much harder to win back.
The day DeepSeek-class models run first on Huawei, the question is no longer who sells more GPUs.
It becomes who defines the standards, the tooling, the developer habits, and the future default infrastructure of AI.
It’s the real nightmare:
not China catching up inside the American system,
but China building a parallel one the rest of the world can actually use.
That is why Washington’s panic sounds like “national security,”
but what it really reveals is fear of technological replacement.

Dwarkesh Patel@dwarkesh_sp
Distilled recap of the back-and-forth with Jensen on export controls: Dwarkesh: Wouldn’t selling Nvidia chips to China enable them to train models like Claude Mythos with cyber offensive capabilities that would be threats to American companies and national security? Jensen: First of all, Mythos was trained on fairly mundane capacity and a fairly mundane amount of it by an extraordinary company. The amount of capacity and the type of compute it was trained on is abundantly available in China. Dwarkesh: With that, could they eventually train a model like Mythos? Yes. But the question is, because we have more FLOPs, American labs are able to get to this level of capabilities first. Furthermore, even if they trained a model like this, the ability to deploy it at scale matters. If you had a cyber hacker, it's much more dangerous if they have a million of them versus a thousand of them. Jensen: Your premise is just wrong. The fact of the matter is their AI development is going just fine. The best AI researchers in the world, because they are limited in compute, also come up with extremely smart algorithms. DeepSeek is not an inconsequential advance. The day that DeepSeek comes out on Huawei first, that is a horrible outcome for our nation. Dwarkesh: Currently, you can have a model like DeepSeek that can run on any accelerator if it's open source. Why would that stop being the case in the future? Jensen: Suppose it optimizes for Huawei. Suppose it optimizes for their architecture. It would put others at a disadvantage. As AI diffuses out into the rest of the world, their standards and their tech stack will become superior to ours because their models are open. Dwarkesh: Tesla sold extremely good electric vehicles to China for a long time. iPhones are sold in China. They didn't cause some lock-in. China will still make their version of EVs, and they're dominating, or smartphones, they're dominating. Jensen: We are not a car. The fact that I can buy this car brand one day and use another car brand another day is easy. Computing is not like that. There's a reason why x86 still exists. There's a reason why Arm is so sticky. These ecosystems are hard to replace. Dwarkesh: It's just hard to imagine that there's a long-term lock-in to the Chinese ecosystem, even if they have this slightly better open-source model for a while. American labs port across accelerators constantly. Anthropic's models are run on GPUs, they're run on Trainium, they're run on TPUs. There are so many things you can do, from distilling to a model that's well fit for your chips. Jensen: China is the largest contributor to open source software in the world. China's the largest contributor to open models in the world. Today it's built on the American tech stack, Nvidia’s. Fact. All five layers of the tech stack for AI are important. The United States ought to go win all five of them. in a few years time, I'm making you the prediction that when we want American technology to be diffused around the world—out to India, out to the Middle East, out to Africa, out to Southeast Asia—on that day, I will tell you exactly about today's conversation, about how your policy ... caused the United States to concede the second largest market in the world for no good reason at all.
English