teïlo retweetledi
teïlo
3.2K posts

teïlo
@teilomillet
curious layman interest in reasoning
Katılım Aralık 2022
1.1K Takip Edilen246 Takipçiler

teïlo retweetledi

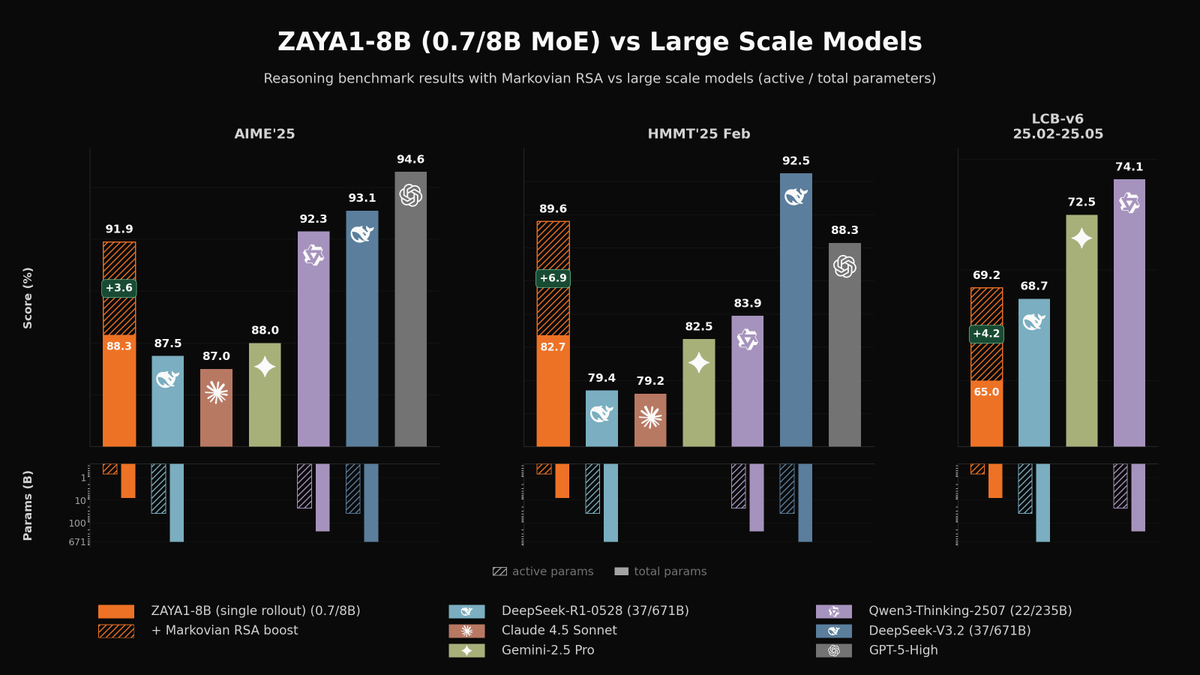
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density.
With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵
English
teïlo retweetledi

That being said,
🗣️model comparisons are scientifically uninformative unless we control for test task adaptation 🗣️
Absolute benchmark performance is nearly meaningless. Rate of progress on newly proposed benchmarks should be taken with a grain of salt.
arxiv.org/abs/2407.07890
English
teïlo retweetledi

In other words: their RL transfers/generalizes.
OpenAI@OpenAI
We’re talking about Goblins. openai.com/index/where-th…
English
@willccbb kinda building an abstraction layer to make every harness into one. so far it covers claude-code / opencode and codex. but it should be universal.
github.com/teilomillet/sa…
English

what cli agents do people use that support a proper server mode?
so far i got:
- codex, pi, opencode, hermes (openclaw? lol)
and not:
- claude, cursor, amp, droid
English
teïlo retweetledi

This is a super cool project, but I think there may be some data contamination. Either that, or its ability to predict the future is truly remarkable.

Nick Levine@status_effects
New work with @AlecRad and @DavidDuvenaud: Have you ever dreamed of talking to someone from the past? Introducing talkie, a 13B model trained only on pre-1931 text. Vintage models should help us to understand how LMs generalize (e.g., can we teach talkie to code?). Thread:
English
sometimes it's "hold up i gotta tweet this" others it's "hold up i gotta grab this on pypi"
English
@factorydoge69 what are the math? openai go bust if they dont reach the 10x yoy expected by dario?
English

teïlo retweetledi


teïlo retweetledi

Confirmed: Anthropic keeping Cyber capabilities of Opus 4.7 artificially low
"during training we experimented with efforts to differentially reduce these capabilities"

Lisan al Gaib@scaling01
big jump in coding capabilities by Claude 4.7 Opus SWE-Bench Pro 64.3% SWE-Bench Verified 87.6% TerminalBench 69.4% but interestingly, I think they kept CyberGym scores artificially low
English
@leothecurious @Noahpinion “you dont have to move on, I am enjoyiny it”
English

@Noahpinion how can u possibly conclude that from this particular clip. how much more sense does jensen have to make before this is intuitive?
English

lmao
“you dont have to move on, i am enjoying it”
Steven Adler@sjgadler
Dwarkesh: Why would we want to sell China the materials for a serious cyberweapon? It's like selling them nukes with a casing that says 'made by Boeing' and claiming that's good for the US Jensen: Comparing AI to nukes is lunacy. Enriched uranium is a lousy analogy. It's an illogical analogy. What we have to recognize is that AI is a five-layered cake.
English
teïlo retweetledi

teïlo retweetledi

We gave an AI a 3-year retail lease in SF and asked it to make a profit.
The AI interviewed and hired full-time employees, applied for credit, and stocked the store with the books Superintelligence and Making of the Atomic Bomb.
Visit Andon Market at 2102 Union St now.
English
teïlo retweetledi

Take this with mountain of salt but if true lol
Rahim Oramine@HereraMark45908
@IntCyberDigest APT IRAN hackers did this and published the source codes of the F-35. It is truly catastrophic.
English
teïlo retweetledi
