D Par
13 posts





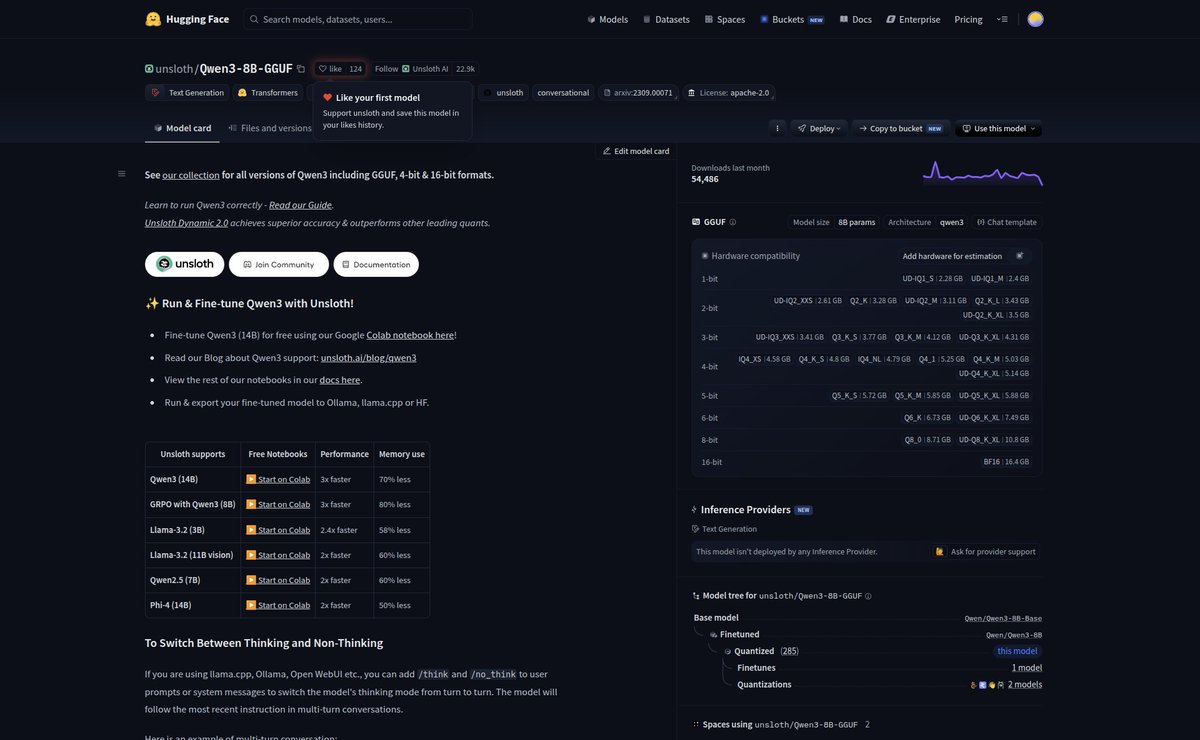
gtx 1080 8gb of vram launched may 2016. card turns ten this month. just ran three current open weight agentic models on one and the smallest of them fit 656,000 tokens of context at 38 tok/s gen speed. on a pascal arch card with no tensor cores. on 8gb of gddr5x that the discourse keeps telling me is unusable. three models, same hardware, same locked flags. qwen3 8b, qwen 3.5 9b, gemma 4 e4b. q4_k_m quant across the board. q4_0 kv cache, flash attention on, llama.cpp built for sm_61. one line setup. results vram ceiling on 8gb qwen3 8b, 78k qwen 3.5 9b, 248k gemma 4 e4b, 656k gen tok/s at small context qwen3 8b, 31.71 qwen 3.5 9b, 29.91 gemma 4 e4b, 42.13 gen tok/s at the ceiling qwen3 8b, 31.78 at 77k qwen 3.5 9b, 29.62 at 248k gemma 4 e4b, 38.73 at 648k agent workload combined throughput at 16k input qwen3 8b, 285.98 qwen 3.5 9b, 413.18 gemma 4 e4b, 543.63 gemma sweeps every category. 2.6x more context than qwen 3.5 9b, 8.4x more than qwen3 8b, 30% faster at the ceiling. sliding window attention keeps the kv cache nearly flat as context grows, which is why 8gb stretches an order of magnitude further on gemma than on a vanilla transformer. the part that gets me is qwen3 8b losing to qwen 3.5 9b at anything past 4k context. newer release, but heavier kv per token, less aggressive gqa, every release has tradeoffs and pascal exposes them by giving the architecture nowhere to hide. q4_0 kv cache is the practical unlock. flash attention on pascal still works in 2026, no special path needed. sm_61 compiles clean in llama.cpp. that's the entire stack. a card you literally might have in a drawer can run a coding agent with 600k+ tokens of context. raw perf is one axis. next drop is the other one. agentic coding on the same hardware. single file canvas demos, then multi file refactors. can these models finish a task without rails or do they fall apart the moment the agent loop gets deep. stay tuned. you might have this card in a drawer.









Burger King Internet corner, New York (1998)