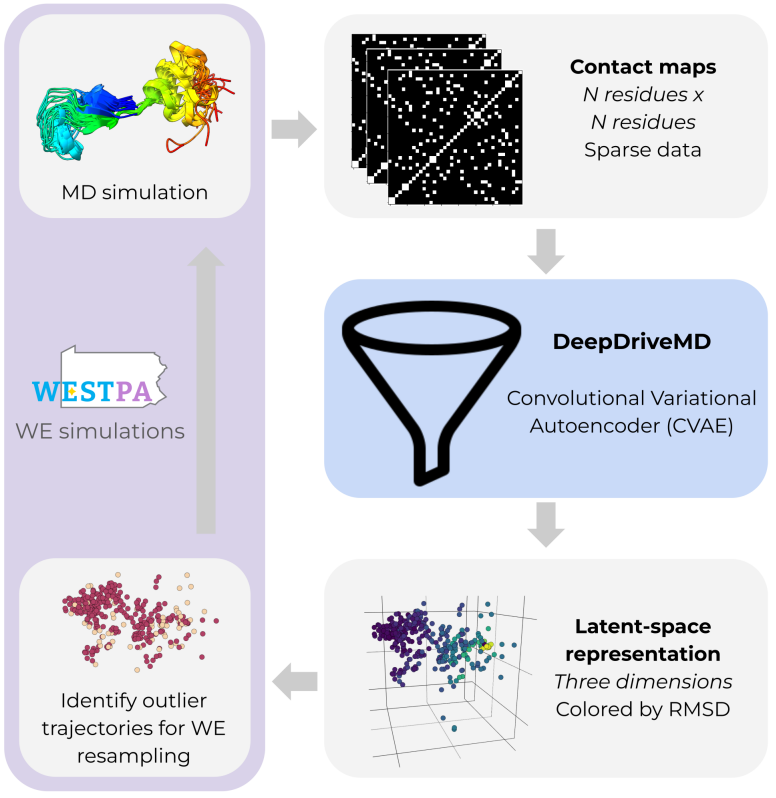
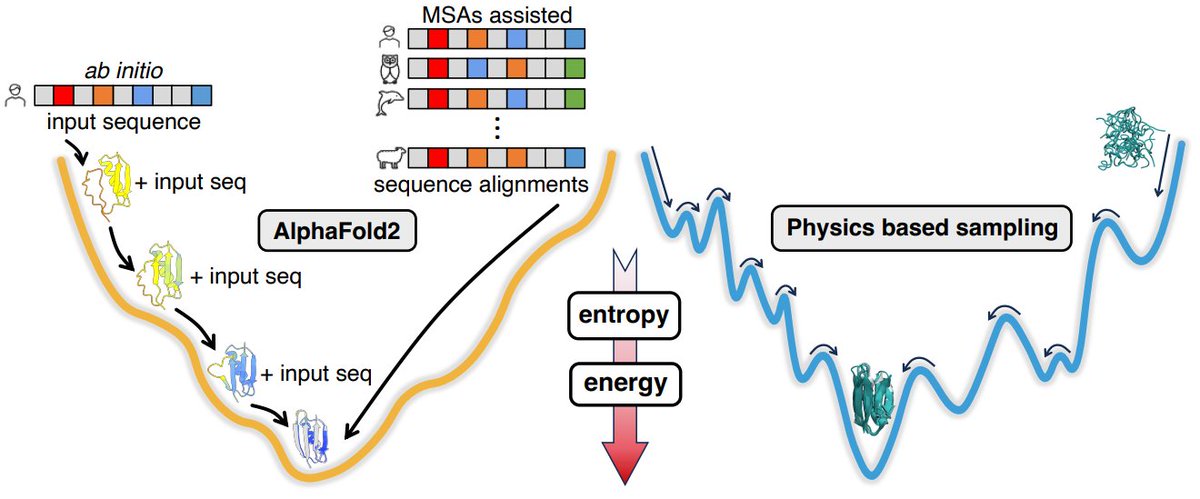
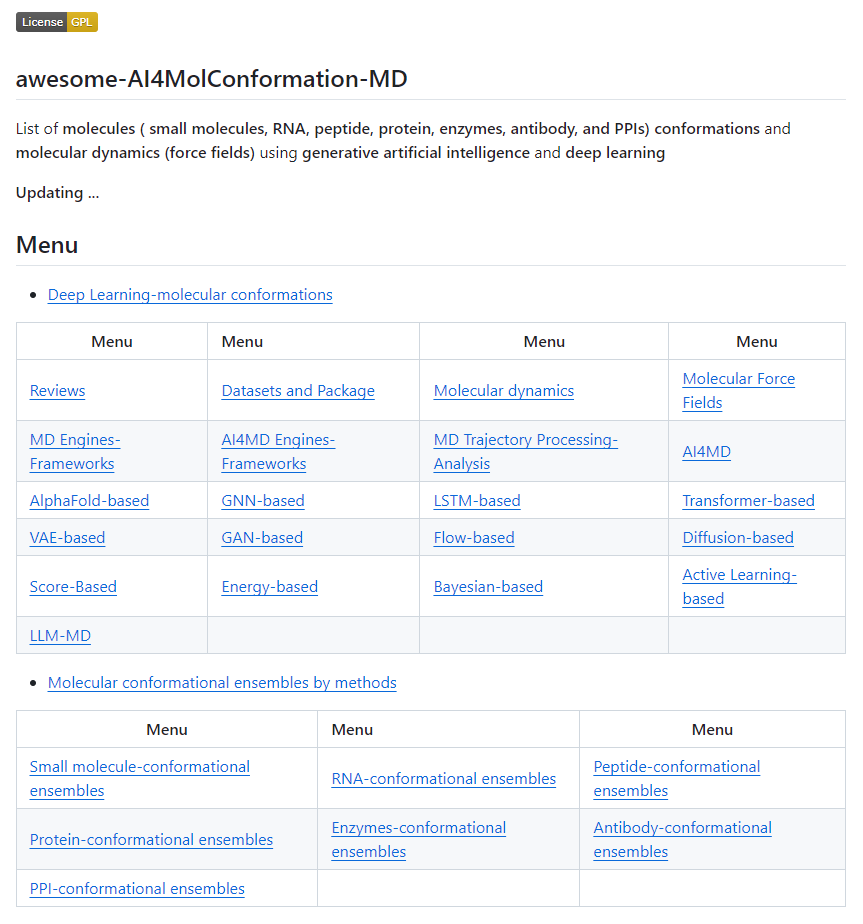
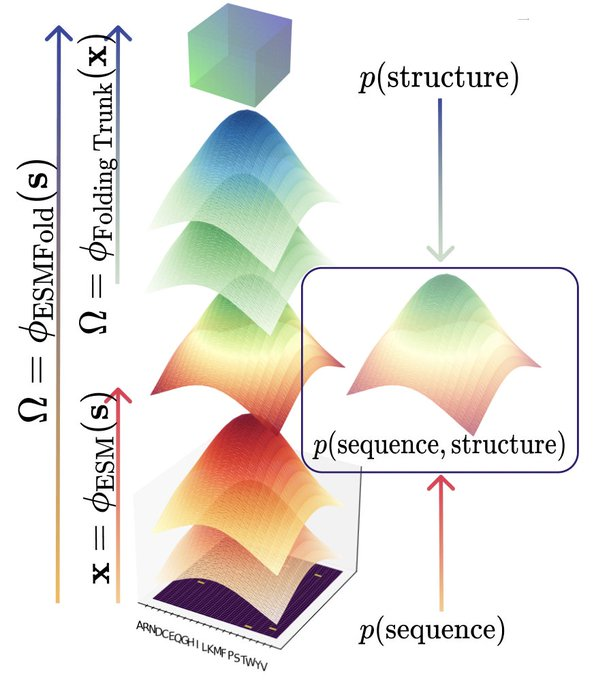
Gustaf Hemberg retweetledi

🚨New paper! Generative models are often “miscalibrated”. We calibrate diffusion models, LLMs, and more to meet desired distributional properties.
E.g. we finetune protein models to better match the diversity of natural proteins.
arxiv.org/abs/2510.10020
github.com/smithhenryd/cgm
English