Sabitlenmiş Tweet

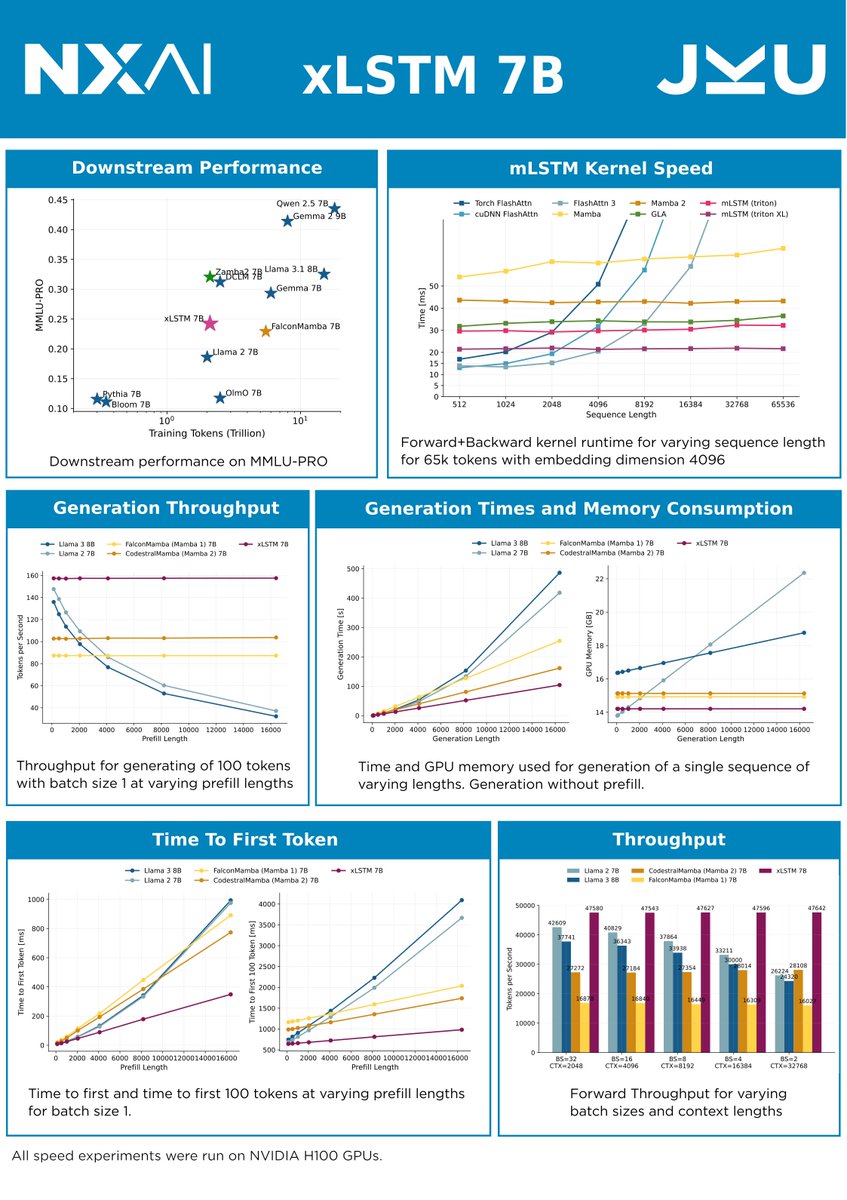
This is what we have been working on for the last few months. Advent of architectures like xLSTM open new frontiers of efficiency for generative models. The xLSTM not only provides constant memory consumption with increasing context length, but is extremely fast at inference.
Thomas Schmied@thsschmied
Transformers can be slow for real-time applications like robotics. We study if modern recurrent architectures, like xLSTM and Mamba, can be faster alternatives. Experiments on 432 tasks show that they compare favourably in terms of performance and speed 🎃 arxiv.org/abs/2410.22391
English