Daily retweetledi

SF Voice AI Meetup livestream. Presentations and panels start at 7:15 Pacific.
youtube.com/live/EWys7ij9T…

YouTube
English
Daily
2.3K posts


@trydaily
Build human and AI ultra low latency conversations. We maintain Pipecat with contributions from the developer community. https://t.co/tFy0gFjmb1 https://t.co/sLtBYxhhch


Sub-agents in (latent) space! We’ve been working on a side project. As far as I know, this is the first massively multiplayer, completely LLM-driven game. Come play Gradient Bang with us. See if you can catch me on the leaderboard. This whole thing started because I wanted to explore a bunch of things I’m currently obsessed with, in an application of non-trivial size, that felt both new and old at the same time. So … a retro-style space trading game built entirely around interacting with and managing multiple LLMs. Factorio, but instead of clicking, you cajole your ship AI into tasking other AIs to do things for you. Some of the things we’ve been thinking about as we hack on Gradient Bang: - Sub-agent orchestration - Partial context sharing between multiple LLM inference loops - Managing very long contexts, and episodic memory across user sessions - World events and large volumes of structured data input as part of human/agent conversations - Dynamic user interfaces, driven/created on the fly by LLMs - And, of course, voice as primary input If you’ve been building coding harnesses, or writing Open Claw agents, or doing pretty much anything that pushes the boundaries of AI-native development these days, you’re probably thinking about these things too! This is all built with @pipecat_ai, the back end is @supabase, the React front end is deployed to @vercel, and all the code is open source.
Join us on Thursday in SF for conversations about voice agents, speech models, and realtime AI infrastructure. I'm on a panel with: - @natrugrats from @DeepgramAI - @farazmsiddiqi from @getbluejay_ai - Aaron Lee from Parakeet Health There will be food and lots of opportunities to ask questions and share your knowledge. One thing I'm looking forward to is comparing notes about GTC last week.
Come by and see @EvanGrenda at the AWS booth at GTC. @tavus video avatars, voice agents built with NVIDIA Nemotron models, and new realtime AI architecture patterns in @pipecat_ai!

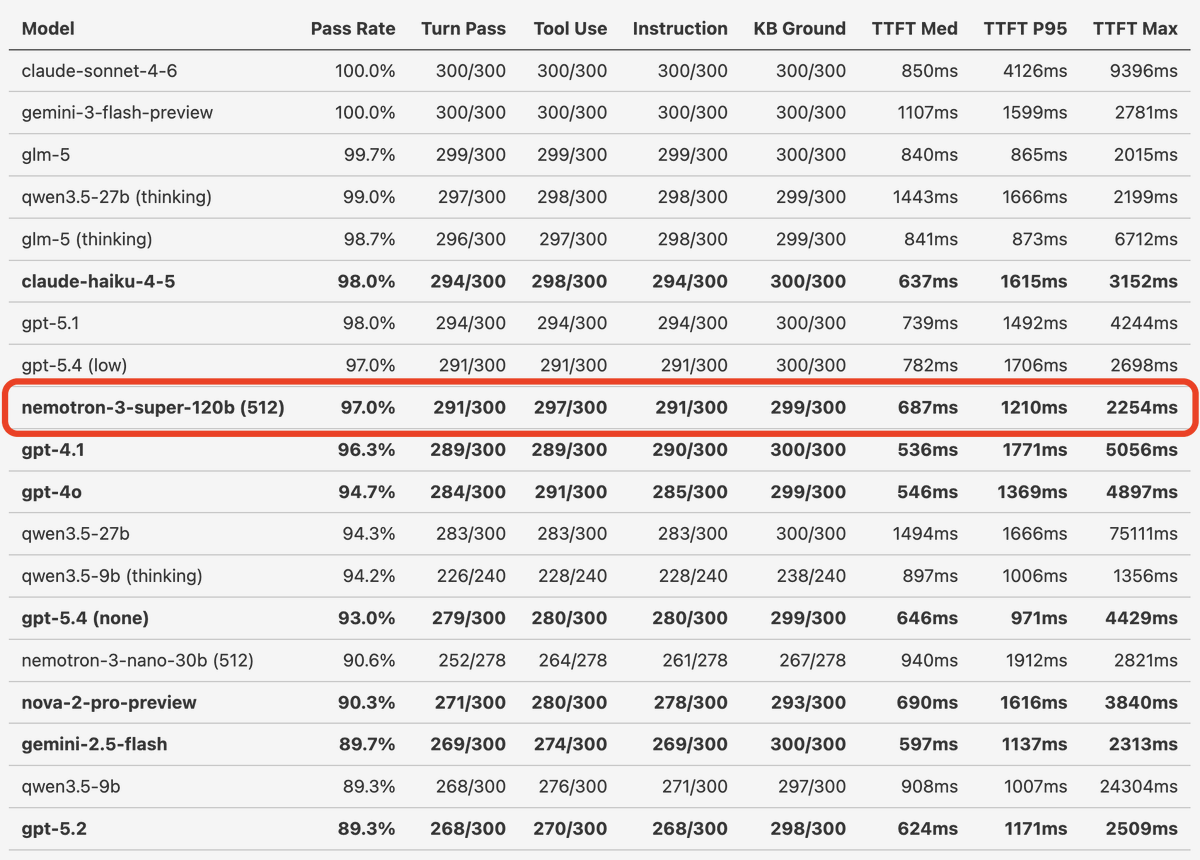
Real-time transcription just got a significant upgrade. Universal-3-Pro is now available for streaming — bringing AssemblyAI's most accurate speech model to live audio for the first time. Developers building voice agents, live captioning tools, and real-time analytics pipelines now get three things they've been asking for: 🔹 Best-in-class word error and entity detection across streaming ASR benchmarks 🔹 Real-time speaker labels — know who said what, as it happens 🔹 Superior entity detection for names, places, orgs, and specialized terminology in real-time 🔹 Code-switching and global language coverage built-in
Voice workflows just got stronger with gpt-realtime-1.5 in the Realtime API. The model offers more reliable instruction following, tool calling, and multilingual accuracy. Demo with @charlierguo

