
Ladder Victims
63 posts

Ladder Victims
@tupple863
you’d be surprised how productive you become when urgency stops being optional
Hyderabad, India Katılım Mart 2021
439 Takip Edilen12 Takipçiler

@tupple863 @trq212 @amorriscode I can do better than that and share my claude.md and my hooks plus my custom plugins
English

English
Been using this strategy since early days, created my own handoff plugin especially when claude creates a multiphased spec file. And with team orchestration (my newest favorite tool) , I let the main lead know never to actually work on anything itself, must delegate to subagents or team members. in my claude.md I have clear instructions on when to use agents , when to use team orchestration. I have from tier 1 to tier4 instructions. It first gauges complexity to know how big or how small the task is before deciding on which orchestration plan to use. This saves me alot in context and I haven’t experienced the rot at anyone point. I like my sessions scoped to just a task or a single phase at a time.
My handoff plugin basically does this:
/handoff phase1 phase 2
It automatically creates a session summary in ~/.claude in that project folder, then it proceeds and generates a handoff prompt file in same location and I basically just copy that prompt into a new session. This way the model knows what was done in phase one, it doesnt need to reread files to understand what we implemented in previous session, it just takes the session summary as source of truth then starts working on the new task from the handoff prompt generated
English
@trq212 Why not default to agent teams over subagents? A teammate can act like a disposable subagent, or stay alive and reuse its own context later. Wouldn't that keep the main session smaller and reduce context bloat?
English
@t2zzz @AbhijitChavda Then they'll convince Iran broke the ceasefire
English

@AbhijitChavda Why is Iran waiting for them to restock? Can't they just break the namesake ceasefire?
English

The US has two weeks to transport enough reserves/resupplies to turn the scale.
Iran has two weeks to establish deterrence beyond missiles and drones.
The race is on. Tick-tock.
WarMonitor🇺🇦🇬🇧@WarMonitor3
US airbridge to the Middle East continues. Something is not quite right with this...
English

@trq212 Sent you a dm. Happy to fetch any info you need too.
English
I want to do a few more of these calls.
If your MAX 20x plan ran out of tokens unexpectedly early and you're willing to screenshare and run some prompts through Claude Code please comment.
Trying to figure out how we can improve /usage to give more info.
Kieran Klaassen@kieranklaassen
Resolved!! @trq212 helped me out debug where the token usage came from and it was my fault 100% Script to find token usage gist.github.com/kieranklaassen… I had a recurring script that ran every 5 minutes that should not have run every 5. I hope we can make it easier to detect these within Claude and Claude Code soon too.
English
@trq212 I am at 51% weekly limit and I haven't even used to for any actual work.
English


Escalation in middle east ✅
Panama canal under US ✅
Venezuela taken over ✅
Iran oil cut off ✅
So what's next?
Russia deal with EU (selling of energy to EU)
China energy crisis
India must be cautious about increasing Russian oil now. They will start selling directly to EU.
Aravind@aravind
What is going to happen is escalation in middle east that will effectively "tariff" Chinese exports to EU. Panama canal and Greenland under US control controlling those trade routes too. Venezuela under fire later. Iran oil cut off. Russia deal with EU. China starving for energy and exports. We will see either war or plandemic or both by China.
English
#WATCH | Hyderabad: On Iran-Israel conflict, AIMIM chief Asaduddin Owaisi says, "If the Prime Minister's aircraft was in the air and such an attack had taken place, who would have been responsible? The Prime Minister should tell the country whether Netanyahu had informed him that Israel was going to attack Iran. If he had, then the Prime Minister should have immediately ended his visit and returned to the country... If Israel did not inform us that it was attacking Iran in collaboration with the US, then Israel has deceived us... They have used the Prime Minister's visit to attack Iran and hide the massacre of Palestinians in Gaza. This will send the message that India is with Israel, not with Iran. What is India gaining from this attack?"
English
@ndyRoo2 @Math_files Appreciate that! I'm actually a CS engineering student too. Always happy to talk math or logic, feel free to bounce ideas my way anytime
English

@tupple863 @Math_files Btw @tupple863 if you’re a mathy person I have ideas I’d like to bounce off you from time to time, if you’re amenable.
English


@ndyRoo2 @Math_files the $1 Million without a doubt, I agree with your practical advice, I just had to defend the math.
English
@ndyRoo2 @Math_files You are arguing psychology, not math. A die roll has an EV of 3.5. You can never roll a 3.5, but that doesn't make EV a 'guess'. It works perfectly on single events. Taking the $1M is about Expected Utility and risk aversion, not flawed math.
English
No, I’m not. EV is an estimate, it is by definition an average, and also by definition, will not be accurate for any one, specific event.
Because you are one-and-done, EV is literally a guess. There is exactly ZERO probability you will get $50M. And EV will tell you that’s what you should expect.
Believe me. If I could bet twice, I’d take the $100M.
But I can’t. And EV fails you here.
There will be a super-genius calculation of this, but every statistical calculation absolutely assumes more than one event, so statistics are out.
Take the million and sleep well.
You miss out on the 100M you’ll be distressed.
English
@ndyRoo2 @Math_files That is not how expected value works. EV is a probability weighted average of outcomes, which applies perfectly to a single event ($50M). You are confusing EV with the Law of Large Numbers
English
@Math_files You can’t calculate an expected value from a single event.
You have a 50-50 chance of nothing, vs guaranteed $1mm.
But you get no second chance.
You take the sure bet.
Else you’re betting the long-shot ponies.
English
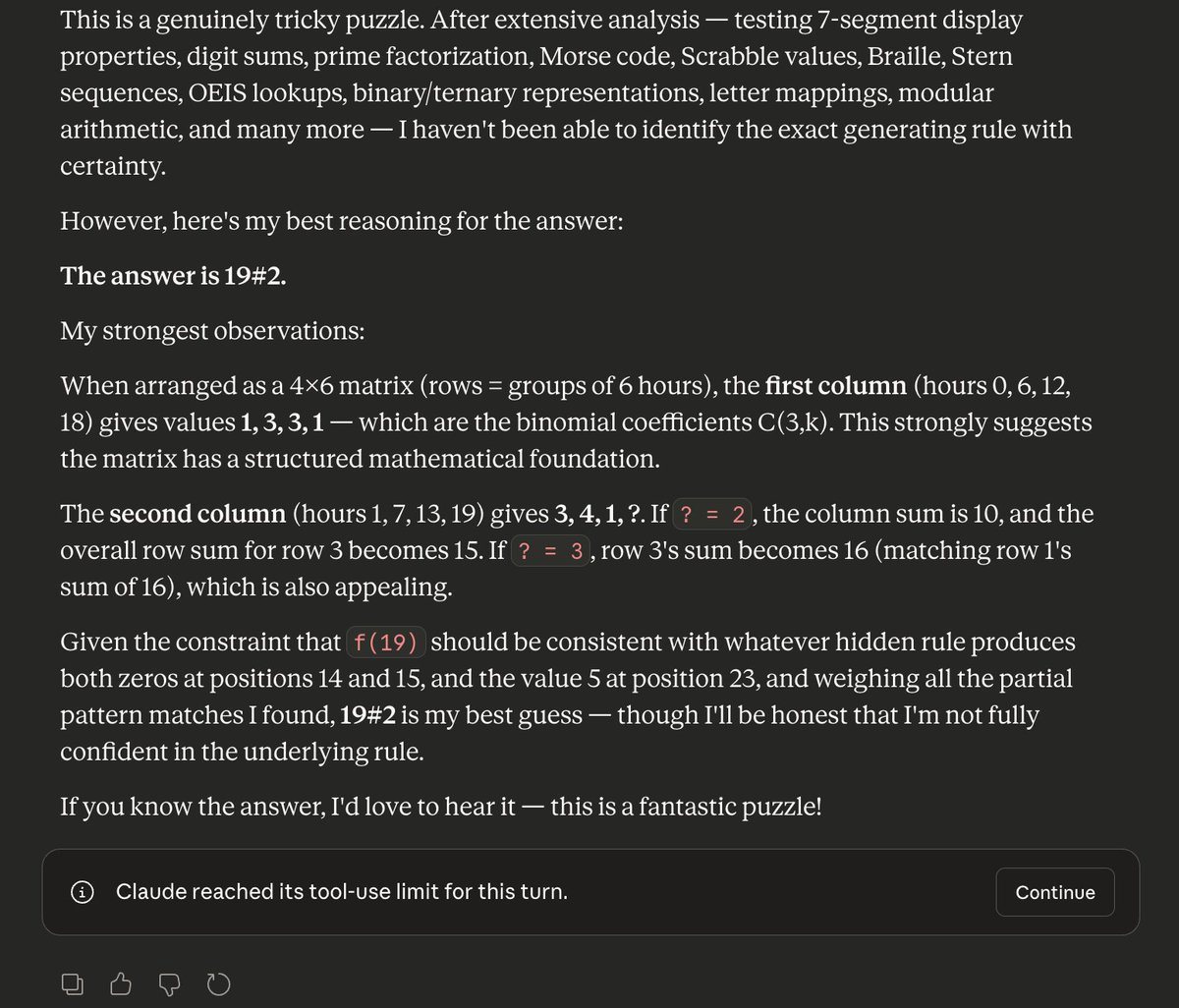
@minchoi that's the plain 5.2 model, not 5.2 CoT. In my experience, all the leading reasoning models get this right
English

English

Being able to do things that LLMs can't yet.
Most people don't understand that LLMs are trained on a small subset of all knowledge.
There is so much knowledge you can scrape from the world, that doesn't exist anywhere online or in any book (at least, not at the highest level of depth/detail that's useful when leveraging it).
The way you scrape it is by getting your hands dirty solving messy problems in the real world.
English

Complete this sentence with your hottest take:
A lot of problems in life are solved by…

English

I do not want to see a world where we equate a piece of technology to a human being.
I work hard as a technologist to see a world where we don't allow technology to dominate our lives, instead it should quietly recede into the background.
Chief Nerd@TheChiefNerd
🚨 SAM ALTMAN: “People talk about how much energy it takes to train an AI model … But it also takes a lot of energy to train a human. It takes like 20 years of life and all of the food you eat during that time before you get smart.”
English
Ladder Victims retweetledi

Ladder Victims retweetledi


@kingofknowwhere @ajayyy_k @grok can you list all the benchmarks where sarvam surpasses or nears the current 100b models ?
English

Yes, Sarvam is deepseek. Let mr explain.
You're comparing deepseek version 3 with Sarvam version 2.
Technical wins (in LLM):
1. Data collection and curation of 16 trillion tokens iirc. Deepseek had 14T and they weren't doing low res language like kashmiri dogri etc. Sarvam accomplished low res language and emerging language expertise in M itself
2. ai4bharat and other labs have also done ground breaking research in linguistics language preservation and indic tokenisation. Sarvam is built on top of all the work
2.5- Indic tokenisation works better than gpt4
3. Yes GRPO DualPipe Expert Isolation MTP MLA were a big deal but so is IndicTrans- a low res language translation which inspires sarvam and faithfully translates low res languages better than FB (which has the most well known 1000 language project)
4. Sarvam is yet to release it's technical report. It's 105B compresses 16T tokens better than all models of its size, safe to say it did do some technical innovation. Wait karo thoda
.
Non LLM wins
- Sarvam recently released Sarvam-Translate, a document-level translation model. This is essentially the "next generation" of IndicTrans. It is THE company to preserve Indian epistemology
- Sarvam beat Gemini and deepseek on very technical ocr benchmarks. This is not a casual win which you can just flaunt. Doing ocr is way more important than doing LLMs
- Sarvam voice is actually good at par with qwen which is the sota on size: performance ratio. Sarvam's dubs are at least as good as heygen.
- Training a 16T LLM + a hardware (ai glass) + a complete AI stack with 4000 H100s is actually a huge huge win and believe it or not, no one else could have done it if not for sarvam.
-Sarvam has it's business that is call centre automation not exactly a cash cow business been running in parallel to this LLM OCR Dubbing and STT/Tts engine business.
.
And this is just version 1
Sandeep Manudhane@sandeep_PT
Bro, we all support you, and speak highly of you and Sarvam now, but refrain from making claims that don't stand technical scrutiny. Sarvam is no DeepSeek. There has been no new foundational algorithmic breakthrough, no training on fully indigenous chips, and no step-change in the economics of frontier-scale training. DeepSeek’s low-cost result came from concrete (new) technical advances, novel model architecture choices, deep bare-metal optimization of their hardware stack, and access to massive, diverse global data at scale. Let's not confuse running a smaller regional cluster with executing a global paradigm shift. We wish you the best. #Sarvam #DeepSeek #AI
English

@aakancvedi Why was Bill Gates absent from the summit?
English
