Assoc. Prof. Dr. M. Umut Demirezen retweetledi
Assoc. Prof. Dr. M. Umut Demirezen
44.9K posts


Assoc. Prof. Dr. M. Umut Demirezen
@udmrzn
Associate Professor of Computer Science & Engineering, Artificial Intelligence Researcher, #artificialintelligence, #deeplearning, #machinelearning, #genai
Turkiye Katılım Şubat 2011
7.4K Takip Edilen2.3K Takipçiler

Assoc. Prof. Dr. M. Umut Demirezen retweetledi

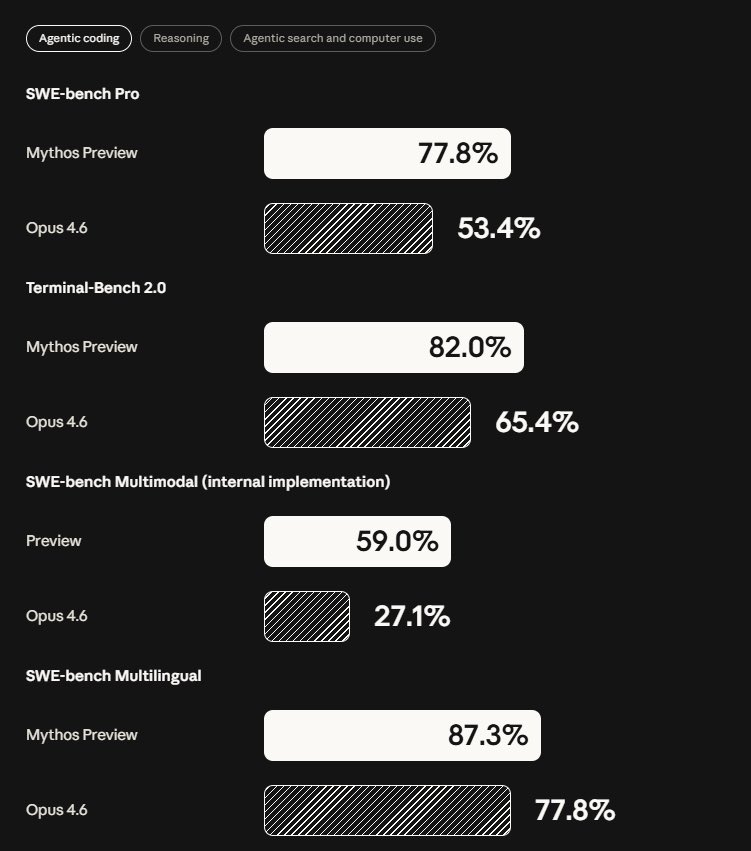
We released Claude Opus 4.6 just two months ago. Today we're sharing some info on our new model, Claude Mythos Preview.

English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

Anthropic is truly unstoppable.
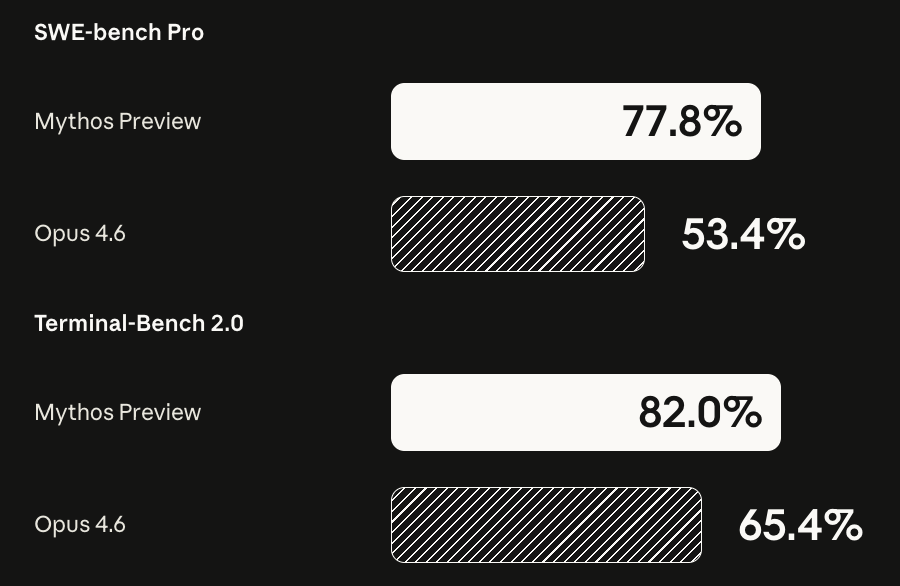
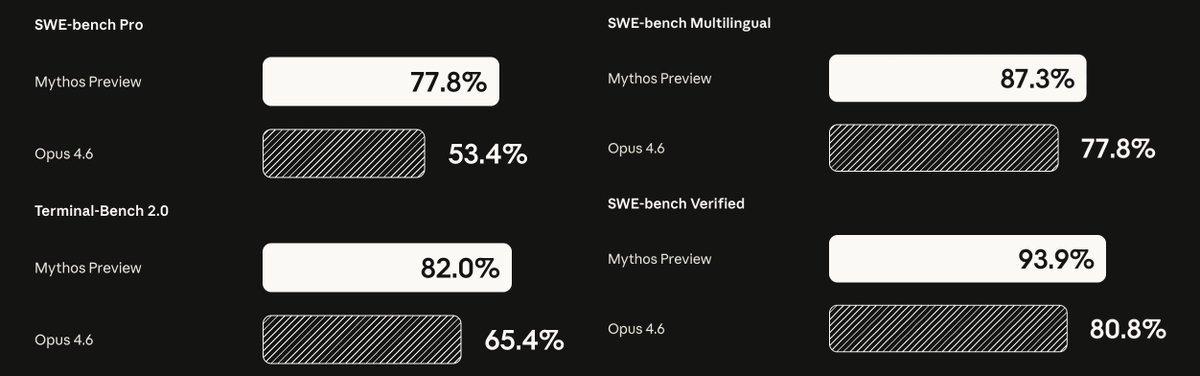
Mythos is crushing Claude Opus 4.6 across every serious agentic coding benchmark.
It has found vulnerabilities in the Linux kernel, a 27-year-old vulnerability in OpenBSD, and a 16-year-old vulnerability in FFmpeg.
No wonder folks at big labs keep telling me AGI is already here.
English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

Okay this one seems real. First time ever an OSS model beats Sonnet 4.6(!!) on our evals. Now begins vibe testing, but this is promising.
Arcee.ai@arcee_ai
Today we're releasing Trinity-Large-Thinking. Available now on the Arcee API, with open weights on Hugging Face under Apache 2.0. We built it for developers and enterprises that want models they can inspect, post-train, host, distill, and own.
English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

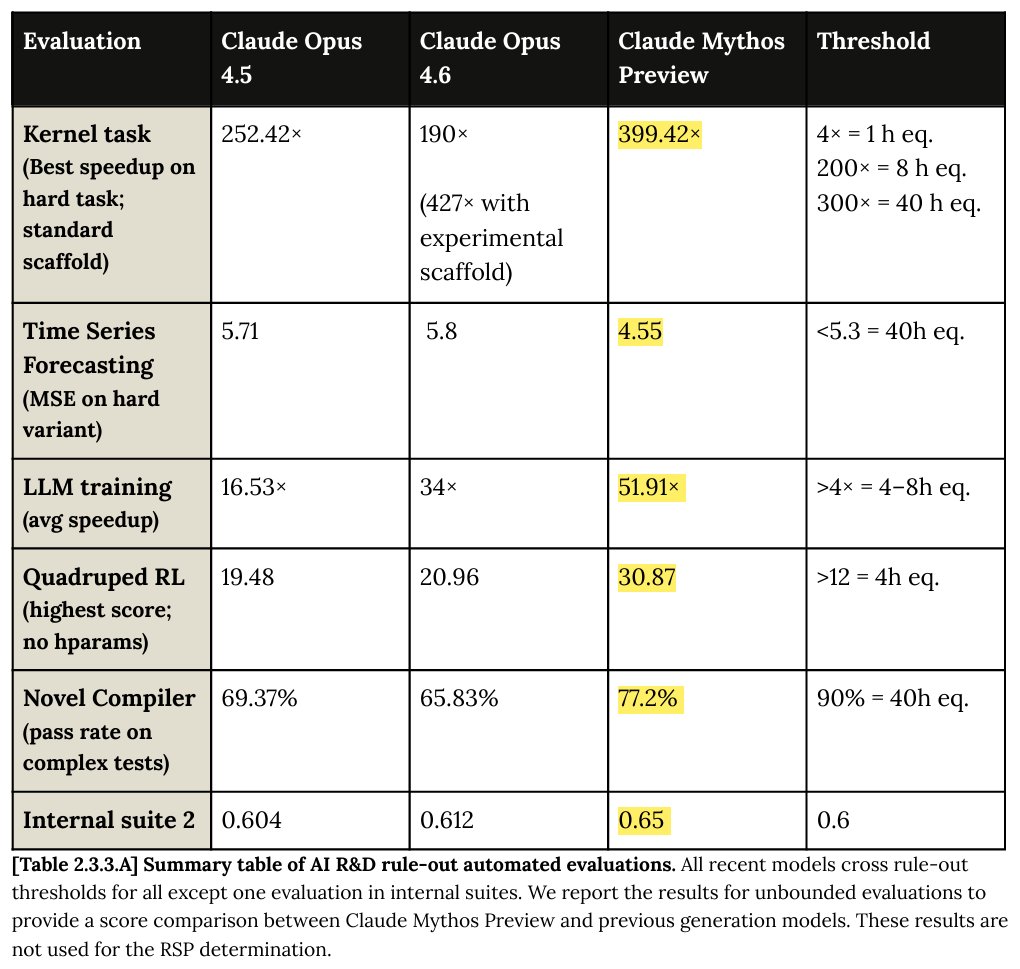
Mythos speeds up AI research by up to 400 times
A 300X speedup over the baseline requires 40 hours of work by a human expert
It also clears the >8h threshold of human equivalent work time on ALL tasks!
English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

Excited to announce a new open-source, free-to-use memory tool I have been developing with my good friend @MillaJovovich.
The project is called MemPalace and it is an agentic memory tool that scored 100% on LongMemEval - the industry standard benchmark for memory… this is higher on than any other published results - free or paid - and it is available now on GitHub.
You can check out Milla’s video about it on her Instagram.
I’ll also put some links in the comments below - please try it out, critique it, fork it, contribute to it - and join our discord.
English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

The Claude Mythos Preview system card is available here: anthropic.com/claude-mythos-…
English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

Assoc. Prof. Dr. M. Umut Demirezen retweetledi

🚀 DeepSeek is rolling out a limited V4 gray release.
A new mode switcher now appears in the chat UI with three options: Fast Mode (default), Expert Mode and Vision Mode。
1️⃣Fast Mode:
• File uploads → text-only extraction
• Likely a lightweight, low-latency model optimized for speed
2️⃣ Expert Mode:
• No file uploads supported
• Restriction likely for compute/cost control, since heavy models + file tokens are expensive
• Likely routes to a larger, more powerful reasoning model
3️⃣ Vision Mode:
• Enables multimodal inputs
• Builds on earlier OCR tests
• May signal DeepSeek’s multimodal capability is moving toward end users
#DeepSeek #AI #LLM #Multimodal #AIGC #Tech
English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

Excited to share that OctoTools has been accepted to ACL 2026. 🐙
OctoTools is our training-free, extensible framework for tool-using agents on complex reasoning tasks.
Grateful to the broader community for the support. Our GitHub repo has now reached 1.4K stars. 📣
Huge thanks to our amazing team: @chenbowen118, @ShengLiu_, @connect_thapa, and Joseph Boen. Special thanks to @james_y_zou.
Code: github.com/octotools/octo…
Project: octotools.github.io
See you in San Diego!🏖️🌴 @aclmeeting
#OctoTools #ACL2026
Pan Lu@lupantech
🐙 Introducing OctoTools: an agentic framework with extensible tools for complex reasoning! 🚀 🧵 🔗 Explore now: octotools.github.io OctoTools tackles challenges in complex reasoning—including visual understanding, domain knowledge retrieval, numerical reasoning, and multistep problem-solving. It introduces: 🔹 Standardized tool cards to encapsulate tool functionality 🔹 A planner for structured high-level & low-level planning 🔹 An executor to carry out tool usage Featured Highlights 💡 ✅ Standardized tool cards for seamless integration of new tools-no framework changes needed (🔎 examples: #tool-cards" target="_blank" rel="nofollow noopener">octotools.github.io/#tool-cards
) ✅ Planner + Executor for structured high-level & low-level decision-making ✅ Diverse tools: visual perception, math, web search, specialized tools & more ✅ Long CoT reasoning with test-time optimization: planning, tool use, verification, re-evaluation & beyond (🔎 examples: #visualization" target="_blank" rel="nofollow noopener">octotools.github.io/#visualization) ✅ Training-free & LLM-friendly—easily extend with the latest models ✅ Task-specific toolset optimization: select an optimized subset of tools for better performance 📊 Performance: OctoTools achieves generalizable gains across 16 tasks, outperforming: 📈 GPT-4o (+9.3%) 📈 AutoGen (+10.6%) 📈 GPT-4o Functions (+7.5%) 📈 LangChain (+7.3%) 🤗 Try the live demo (supported by @huggingface @_akhaliq): huggingface.co/spaces/octotoo… 🐙 OctoTools in action on diverse real-world examples: ✅ How many r letters are in the word strawberry? ✅ What's up with the upcoming Apple Launch? Any rumors? (credit: @karpathy) ✅ Which is bigger, 9.11 or 9.9? ✅ Solve gane of 24 with [1,1,6,9] ✅ Research trends in tool agents with LLMs for scientific discovery from ArXiv, PubMed, and Nature ✅ How many baseballs are there? (visual perception, GPT-4o ❌) ✅ What is the organ on the left side of this image? (radiology, GPT-4o ❌) ✅ What are the cell types in this image? (pathology, GPT-4o ❌) ... and more! Dive deep into OctoTools: 📄 Read our 89-page paper: arxiv.org/abs/2502.11271 💻 Explore the codebase: github.com/octotools/octo… Huge thanks to our amazing team: @chenbowen118, @ShengLiu_, @connect_thapa, Joseph Boen! Special thanks to @james_y_zou, @StanfordHAI, @ChanZuckerberg for the support! 🙌 #Agent #LLMs #ToolUse #Reasoning #OctoTools English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

Assoc. Prof. Dr. M. Umut Demirezen retweetledi

We’re thrilled to open-source TriAttention! 🚀
🦞 Deploy OpenClaw (32B LLM) on a single 24GB RTX 4090 locally
💻Full code open-source & vLLM-ready for one-click deployment
⚡️ 2.5× faster inference speed & 10.7× less KV cache memory usage
TriAttention is a novel KV cache compression method built on rigorous trigonometric analysis in the Pre‑RoPE space for efficient LLM long reasoning.
Github Repo: github.com/WeianMao/triat…
Paper Link: huggingface.co/papers/2604.04…
Homepage: weianmao.github.io/tri-attention-…
English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

for those interested in distributed reinforcement learning I just finished a ~1h tutorial on the echo2 framework by @Gradient_HQ
we check:
- how to do async RL
- infra split between rollout workers and centralized learner
- interview with gradient cofounder eric yang himself!

English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

OpenClaw 2026.4.5 🦞
🎬 Built-in video + music generation
🧠 /dreaming is now real
🔀 Structured task progress
⚡ Better prompt-cache reuse
🌍 Control UI + Docs now speak 12 more languages
Anthropic cut us off. GPT-5.4 got better. We moved on. github.com/openclaw/openc…
English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

🌱 AI-powered farming, without chemicals.
@Aigenio’s solar-powered robots use vision AI to identify and remove weeds at the plant level—helping farmers reduce herbicides and adopt more sustainable practices.
Powered by simulation, real-world data and edge AI, this is what physical AI looks like in agriculture.
📖 nvda.ws/4vfwRUc
English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

Assoc. Prof. Dr. M. Umut Demirezen retweetledi

Day 93/365 of GPU Programming
Studying parallelism today and stumbled upon this incredible blog post/book The Ultra-Scale Playbook: Training LLMs on GPU Clusters by Hugging Face that dives deep into data parallelism, expert parallelism, tensor parallelism, pipeline parallelism and context parallelism.
I've read a bit about each of these methodologies before but this is the best resource I've found that really pieces them all together into a unified coherent picture. Kinda like its name implies, the team goes into actual empirical examples based on the 4000 scaling experiments (across up to 512 GPUs!) they conducted.
E.g. how does tensor parallelism reduce activation memory for matmuls but still require gathering full activations for LayerNorm? When does pipeline parallelism's bubble overhead outweigh its memory savings? When and why would you combine TP/PP/DP on a specific cluster topology? What's the real memory breakdown between params, gradients, optimizer states and activations and which parallelism strategy targets which? et cetera
Also loved all the beautiful and sometimes interactive diagrams that reminded me of distill.pub (which makes sense given they used distill's template to create the post). I wish more blog posts in ML would use a similar approach to help visual learners understand the content at an intuitive level. Especially now that rich visualizations/animations are so easy to spin up with LLMs.
Really wonderful work by @Nouamanetazi @FerdinandMom @xariusrke @mekkcyber @lvwerra @Thom_Wolf. In times when things are going more and more closed source in, this is such a good example of what great open source AI education and research can look like.
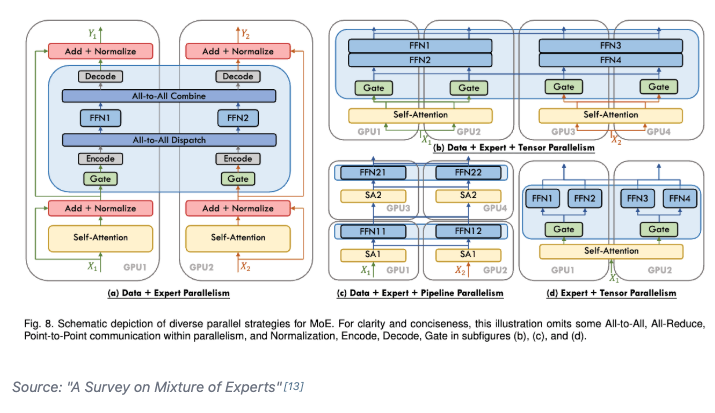
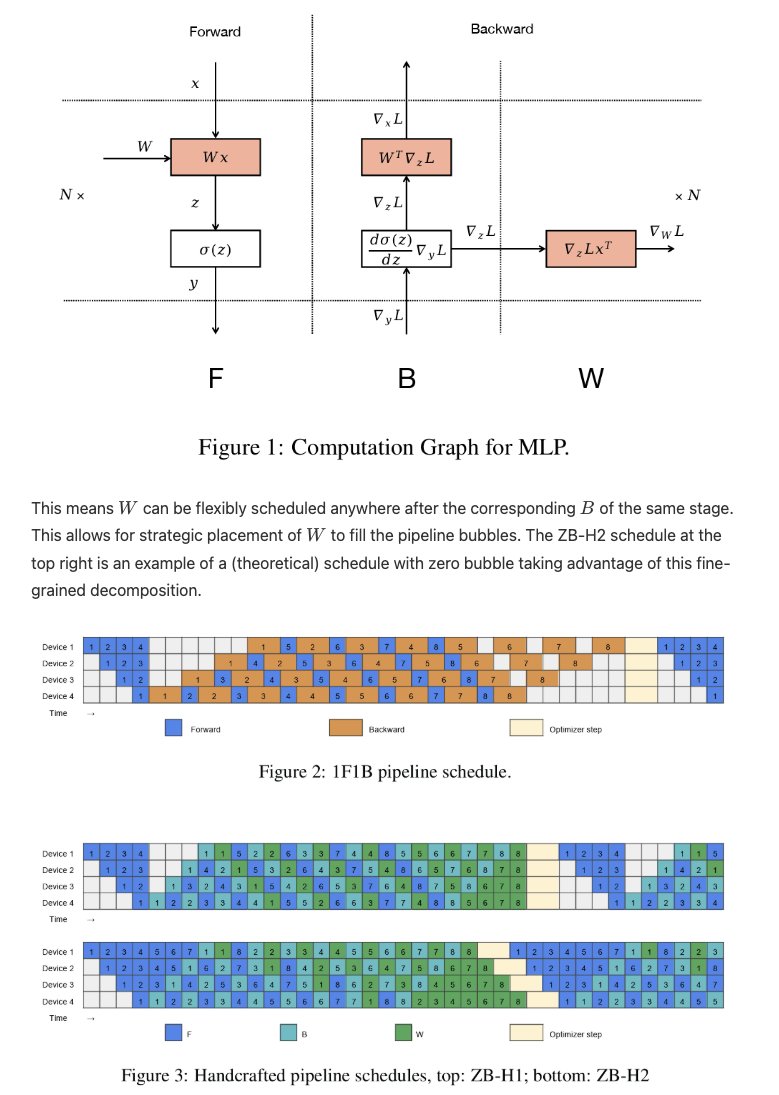
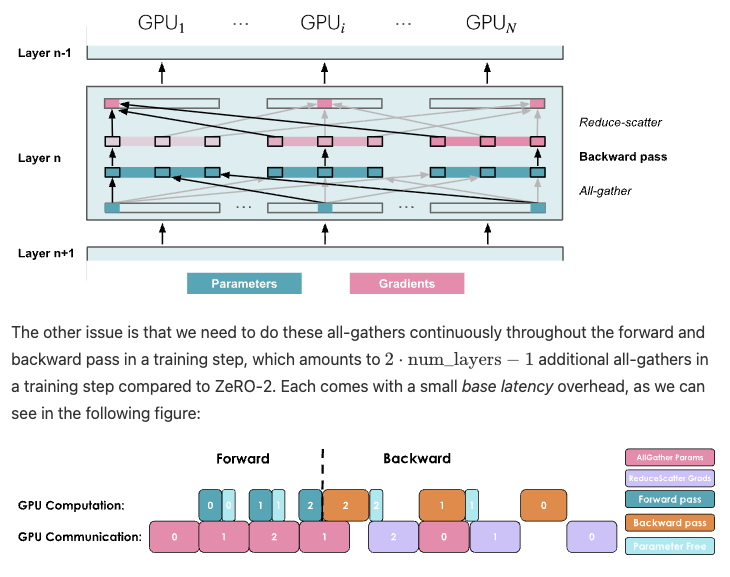
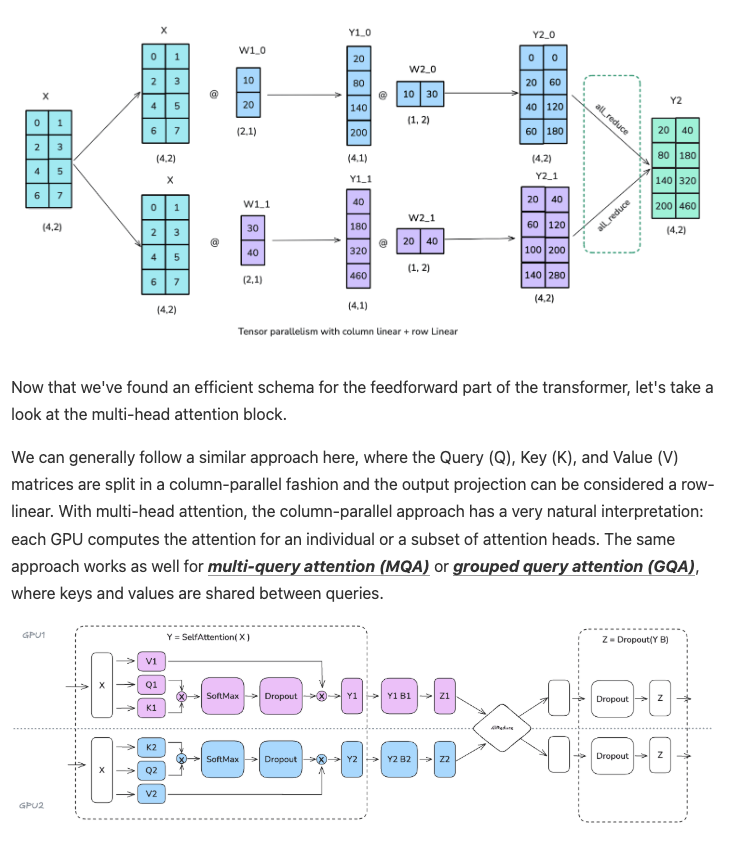
levi@levidiamode
Day 92/365 of GPU Programming Taking a closer look at disaggregated LLM inference today, which I've been wanting to survey more after listening to the Dean <> Daly discussion at GTC. The best resource I found on the topic was this great talk by @Junda_Chen_ on the past, present and future of prefill decode disaggregation. In the lecture, Junda goes through Nvidia's dynamo, the intrinsic tradeoff spectrum between throughput & latency, TTFT, TPOT, the "goodput" metric, distinct characteristics between prefill vs decode, chunking P&D, the problem of interference, pipeline parallelism, resource & parallelism coupling, disaggregation and DistServe.
English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi
🔥Introducing #AgentFlow, a new trainable agentic system where a team of agents learns to plan and use tools in the flow of a task.
🌐agentflow.stanford.edu
📄huggingface.co/papers/2510.05…
AgentFlow unlocks full potential of LLMs w/ tool-use.
(And yes, our 3/7B model beats GPT-4o)👇
🧩A team of four specialized agents coordinates via shared memory:
Planner: plan reasoning & tool calls 🧭
Executor: invoke tools & actions 🛠
Verifier: check memory status ✅
Generator: produce final results ✍️
💡The Magic:
🌀💫 AgentFlow directly optimizes its Planner agent live, inside the system, using our new method, Flow-GRPO (Flow-based Group Refined Policy Optimization). This is "in-the-flow" reinforcement learning.
📊The Results:
AgentFlow (7B backbone) outperforms top baselines on 10 benchmarks, with average gains of:
+14.9% on search 🔍
+14.0% on agentic 🤖
+14.5% on math ➗
+4.1% on science 🔬
🏆It even surpasses larger-scale models like Llama-3.1-405B and GPT-4o (~200B).
Try it yourself!
🛠️Code: github.com/lupantech/Agen…
🚀Demo: huggingface.co/spaces/AgentFl…
🤖Model: huggingface.co/AgentFlow/mode…
📊Visual: #visualization" target="_blank" rel="nofollow noopener">agentflow.stanford.edu/#visualization
💬Join our Slack: join.slack.com/t/agentflow-co…
#agentic #llms #RL #tooluse
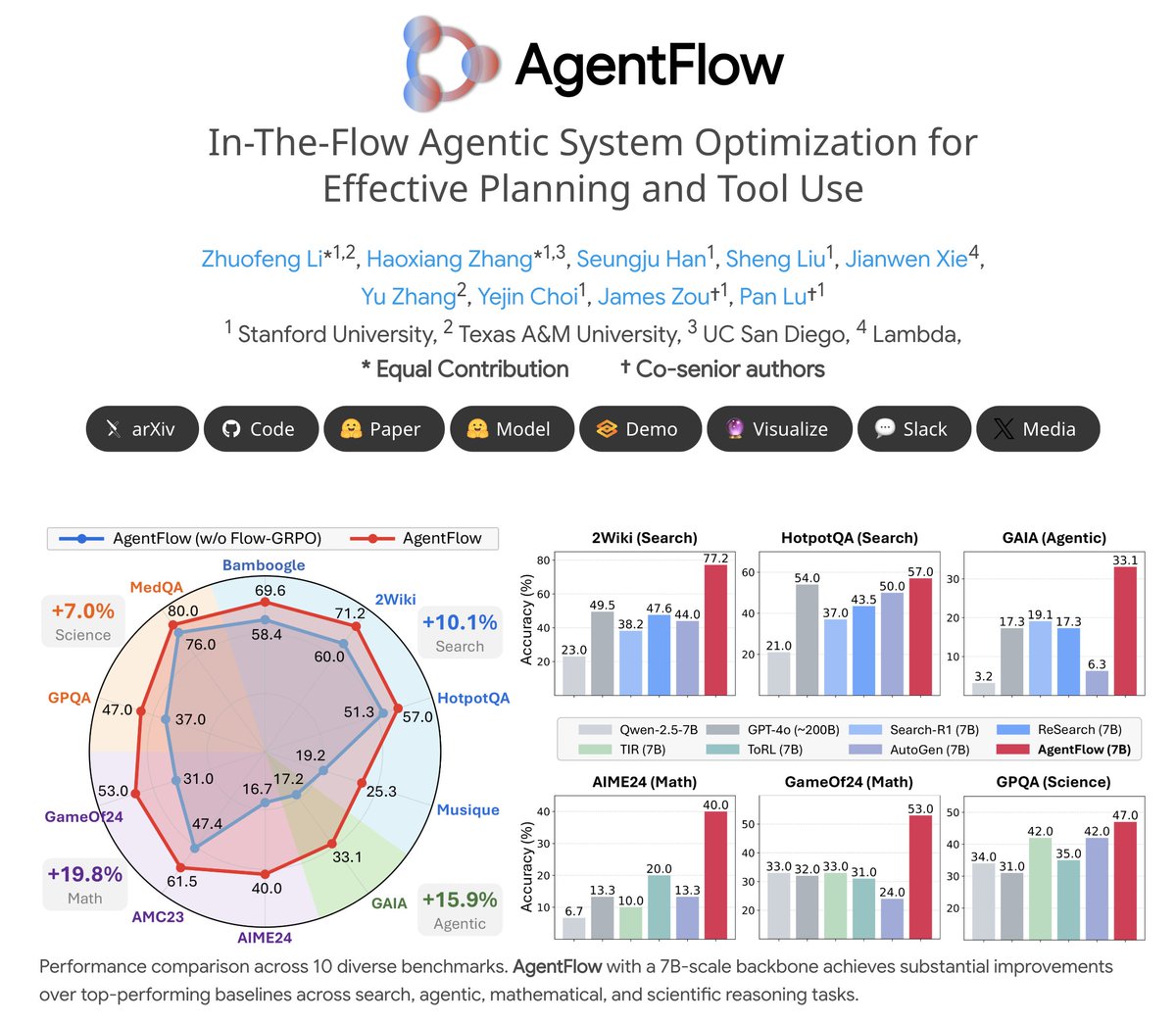


English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

Training multi-agent teams is hard.
#AgentFlow comes to the rescue. We introduce Flow-GRPO, an efficient method to train multi-agent teams. Improves planning and tool use.
Selected as an #ICLR2026 Oral (top 1%)🚀
Pan Lu@lupantech
🔥Introducing #AgentFlow, a new trainable agentic system where a team of agents learns to plan and use tools in the flow of a task. 🌐agentflow.stanford.edu 📄huggingface.co/papers/2510.05… AgentFlow unlocks full potential of LLMs w/ tool-use. (And yes, our 3/7B model beats GPT-4o)👇 🧩A team of four specialized agents coordinates via shared memory: Planner: plan reasoning & tool calls 🧭 Executor: invoke tools & actions 🛠 Verifier: check memory status ✅ Generator: produce final results ✍️ 💡The Magic: 🌀💫 AgentFlow directly optimizes its Planner agent live, inside the system, using our new method, Flow-GRPO (Flow-based Group Refined Policy Optimization). This is "in-the-flow" reinforcement learning. 📊The Results: AgentFlow (7B backbone) outperforms top baselines on 10 benchmarks, with average gains of: +14.9% on search 🔍 +14.0% on agentic 🤖 +14.5% on math ➗ +4.1% on science 🔬 🏆It even surpasses larger-scale models like Llama-3.1-405B and GPT-4o (~200B). Try it yourself! 🛠️Code: github.com/lupantech/Agen… 🚀Demo: huggingface.co/spaces/AgentFl… 🤖Model: huggingface.co/AgentFlow/mode… 📊Visual: #visualization" target="_blank" rel="nofollow noopener">agentflow.stanford.edu/#visualization
💬Join our Slack: join.slack.com/t/agentflow-co… #agentic #llms #RL #tooluse English
Assoc. Prof. Dr. M. Umut Demirezen retweetledi

Diffusion (stochastic SDE sampler): erratic Brownian trajectories zigzagging through noise.
Flow Matching (deterministic ODE integrator): clean, straight-line paths to the data modes.
Same start, radically different dynamics.
English