AI-ML-UPDATES retweetledi

AI-ML-UPDATES
6.5K posts












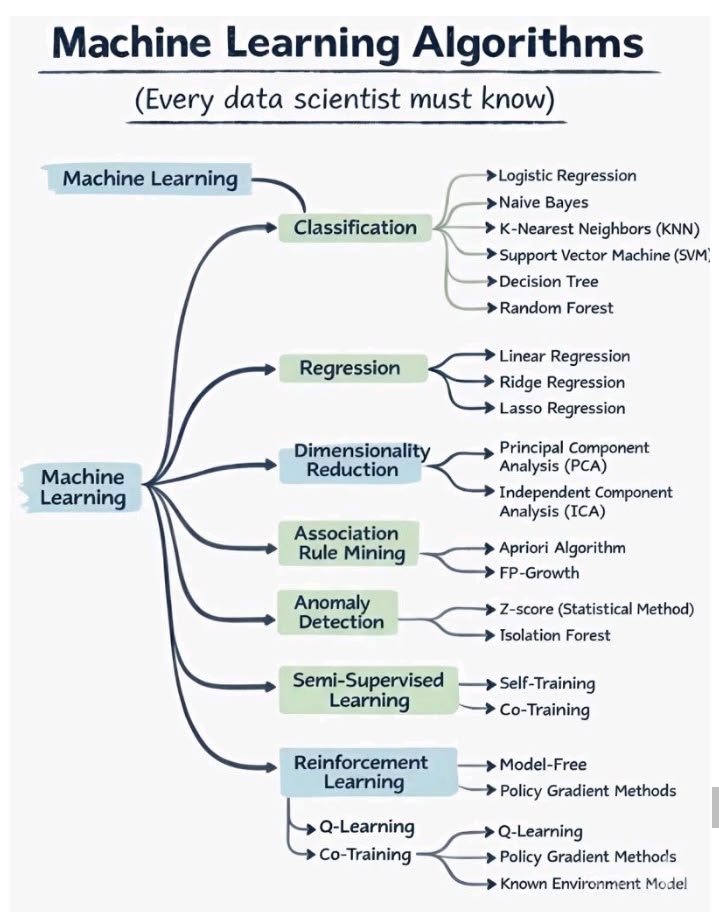
Meta just made byte-level LLMs 92% cheaper to run at inference. No tokenizer. No subword vocabulary. Just raw bytes — and now, parallel generation. Here's how BLT-Diffusion works: > Standard BLT generates 1 byte at a time (slow) > BLT-D generates a full block of bytes in parallel per step > BLT-S uses BLT's own decoder as a speculative drafter — no extra model > BLT-DV drafts via diffusion, verifies autoregressively — same weights Result: up to 92% memory-bandwidth reduction vs BLT. Translation quality holds. Full analysis: marktechpost.com/2026/05/11/met… Paper: arxiv.org/pdf/2605.08044 @AIatMeta @JulieKallini @ArtidoroPagnoni @TomLimi @gargighosh @LukeZettlemoyer @XiaochuangHan @sriniiyer88 @ChrisGPotts @stanfordnlp