Vallabh retweetledi

Vallabh
35 posts


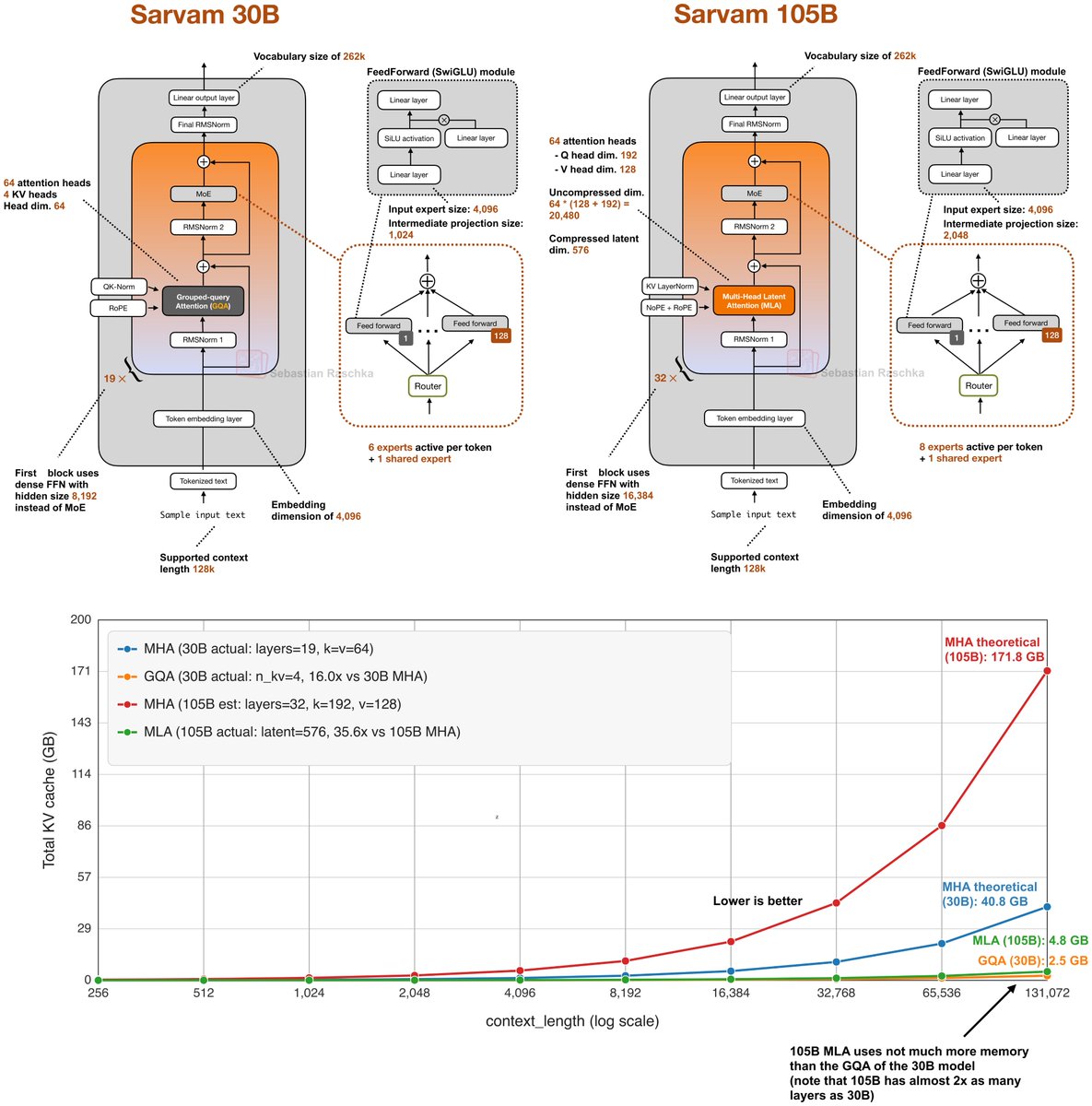
📢 Open-sourcing the Sarvam 30B and 105B models! Trained from scratch with all data, model research and inference optimisation done in-house, these models punch above their weight in most global benchmarks plus excel in Indian languages. Get the weights at Hugging Face and AIKosh. Thanks to the good folks at SGLang for day 0 support, vLLM support coming soon. Links, benchmark scores, examples, and more in our blog - sarvam.ai/blogs/sarvam-3…



For 50 yrs we treated the supremacy of asset-light businesses as a permanent economic law But if AI commoditizes asset-light businesses, we’d just be reverting to the historical mean where value accrued to atoms, infrastructure, energy It would be a 50 year blip. An anomaly






Zero brokerage firms - look at the profits @shyamsek



12 story rocket turns off its engines & does a controlled fall




