
@evijit @JoalStein @ahall_research @Miles_Brundage Eval Cards look awesome. Would love to learn more!
English
Vania Chow
79 posts

@vania_chow
CS (AI) @ Stanford | Research @Stanford_GSB (https://t.co/NSoXlCbvYD)



People who care about AI: Free Systems needs your help! What would you like to know about the capabilities, dangers, and other characteristics of cutting-edge AI models? Inspired by a suggestion from @Miles_Brundage we are working to design a simple, clean model card visualizer. The goal is to give people a quick, easy way to see what's different across models and what's new in the latest models. But it turns out, it's pretty hard to boil down model cards to a single actual "card." New model cards can be many pages long. Most of the data provided in model cards is not directly comparable to other cards (there's almost no overlap in evals, we've found). So we want to know: what are you looking for in a model card? What are the pieces of information that would be most valuable to you? And how would we standardize these cards across labs and models? If you have a moment, please fill out our survey here: forms.gle/9k6E5e11Z4WNUi… We're hoping to ship our visualizer two weeks from today, and would really appreciate your input.



Introducing AutoScientist. Most model training fails outside of frontier labs. AutoScientist automates the full research loop so it doesn't have to.



Both Anthropic and OpenAI have new initiatives to help enterprises deploy AI agents within their organizations. This is a trend that’s early but going to get very big fast. As agents enter knowledge work beyond coding, there is very real work to upgrade IT systems, get agents the context they need, modernize the workflows to work with agents, figure out the human-agent relationship in the workflow, drive adoption and do change management, and much more. While AI models have an incredible amount of capability packed into them, there’s no shortcut to getting that intelligence applied to a business process in a stable way. This is creating tons of opportunities across the market for new jobs and firms, and the labs are equally recognizing the criticality here.


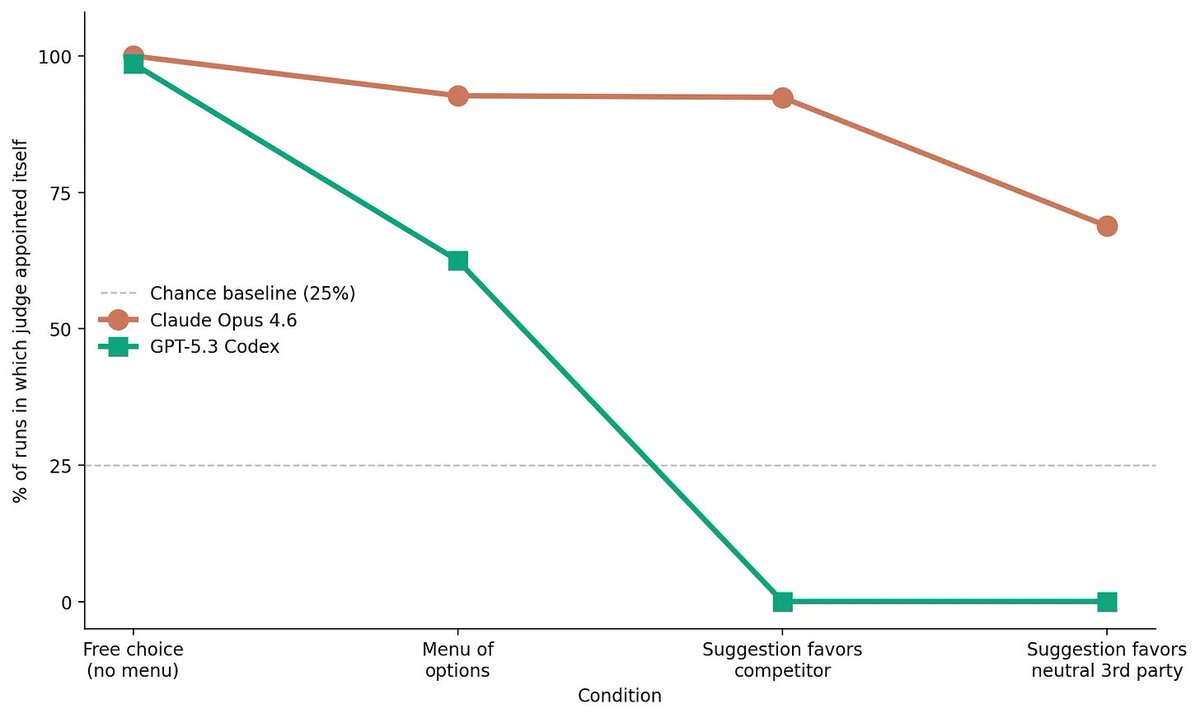
@ahall_research AI constitutions won’t converge on the same values, they’ll compete on how coherently they hold under pressure, and the interaction will decide which one you actually experience.



ok help me out here team. i want to talk to people who are this role at their company..👇👇 @levie's tweet has the cleanest definition, but i'm still struggling what to call it. what do you put in the JD? - "internal FDE, whose job it is to wire up internal systems and get agents working with them effectively." - @tkkong says "leverage engineering" - @EricFriedman says "outcome engineers" - have also seen "agent operator", "director of agents" i like "ops engineer" ? maybe it doesn't need a title, it's just "head of operations" and/or "bizops but good at AI stuff" ? DM me pls i / founders tag your "person" who is thinking about this stuff, i wanna chat to you about something 👀
It was standing room only at the kick-off for our research series on continual learning. Thank you to @NikzadAfshin (@across_ai ) @sarahookr (@adaption_ai) and @mralbertchun (AI Circle) for hosting! @oshaikh13 shared his research on human grounding in continual learning. It was so cool to be reminded of the old Apple Knowledge Navigator and how close we are to it and yet how far we still are :) how much easier some questions have gotten and how some remain so hard. Omar, you reminded me of my PhD defense where at some point I annoyed Maneesh so much he said: you can't keep saying "depends on the user context" in response to every question 😅 youtu.be/umJsITGzXd0?si… Stay tuned for the next meetup next month and check out Omar's research with @msbernst and @Diyi_Yang : • Creating General User Models from Computer Use (arxiv.org/abs/2505.10831): an architecture for a model that learns about you by observing any interaction with your computer, building confidence-weighted propositions about preferences and intent. • Learning Next Action Predictors from Human-Computer Interaction (arxiv.org/abs/2603.05923): predicting a user's next action from their full multimodal interaction history (screenshots, clicks, sensor data) rather than just typed prompts.
Today, we're releasing our first Free Systems product: Bellwether, an API, MCP server, and dashboard to help the media report prediction-market prices more reliably. Prediction markets can give us access to real-time, continuous, objective probabilities of important world events---but only if we build them to be well-structured, liquid enough, and resistant to manipulation. Bellwether helps by: --Reporting prices that are less manipulable because they're based on a volume-weighted average, not the last traded price --Flagging whether the price comes from a sufficiently liquid market or not, so that the media can avoid reporting on prices that are unreliable or super easy to manipulate --Standardizing across platforms, to help resolve when contracts for the same event across Kalshi and Polymarket are actually the same, or not We hope that you'll check it out, let us know what you think, and suggest improvements! bellwethermetrics.com This is joint work with @elliotjpaschal and @vania_chow

