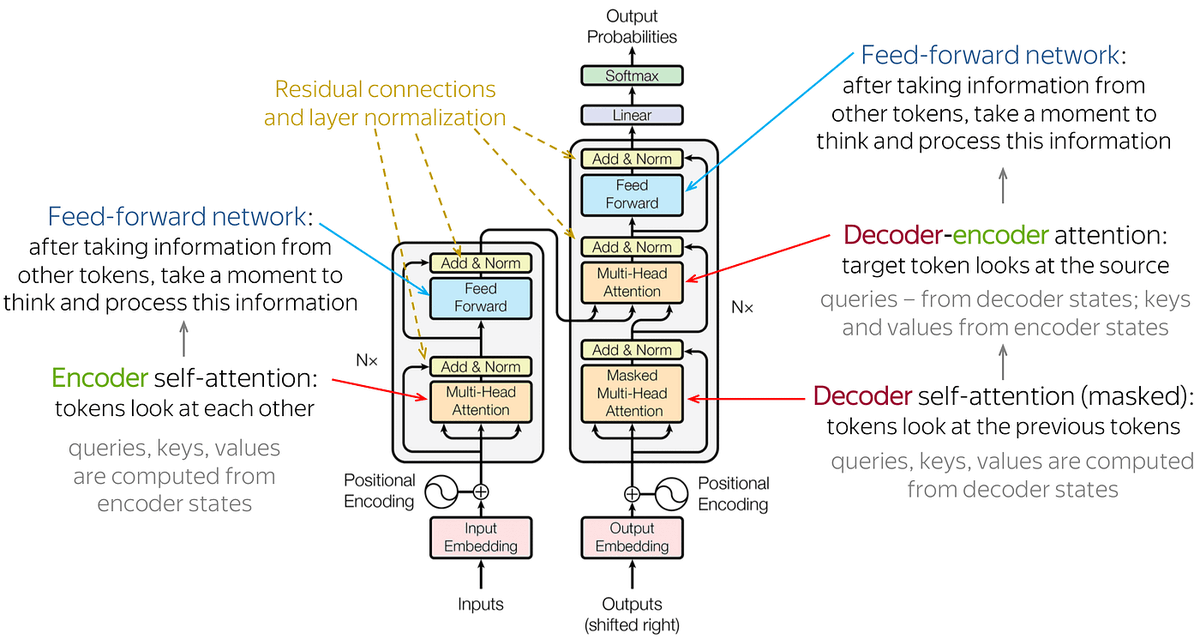
Amrita Chanda 🏳️🌈👩🏾💻🍸 retweetledi

"design tools continue to fall behind CSS" was a recurring theme at @CSSDayConf
- typography features (so many!)
- scroll animation
- meaningful math tricks
- layout capabilities
- container queries / responsive capabilities
- anchor positioning
- :has() and presence awareness
- quantity queries
- scroll snap
and so much more…
it seems like design tools are competing against each other to be the best Photoshop variant. meanwhile, the web's features are pushing fast into a mega capable future and designers are blissfully unaware. (i'm aware this isn't all teams, but it's def the majority)
web designers, sit with your web developers
web developers, sit with your web designers
also, someone (i wish i could work on this) make a tool that unlocks these features for designers. help them wield these capabilities, they're super fun and very meaningful.
the delta is growing too fast between CSS and design tools, someone or something close this gap!!
English