what is a cybersecurity risk? I am just trying to download a reel and this pops up. Is downloading currently against Chatgpt TOS?

English
Ruirui Wan
167 posts



We’re releasing SWE-1.6, our best model in both intelligence & model UX. SWE-1.6 matches our Preview model on SWE-Bench Pro while dramatically improving on various behavioral axes. It’s available today in Windsurf in two modes: free tier (200 tok/s) and fast tier (950 tok/s).


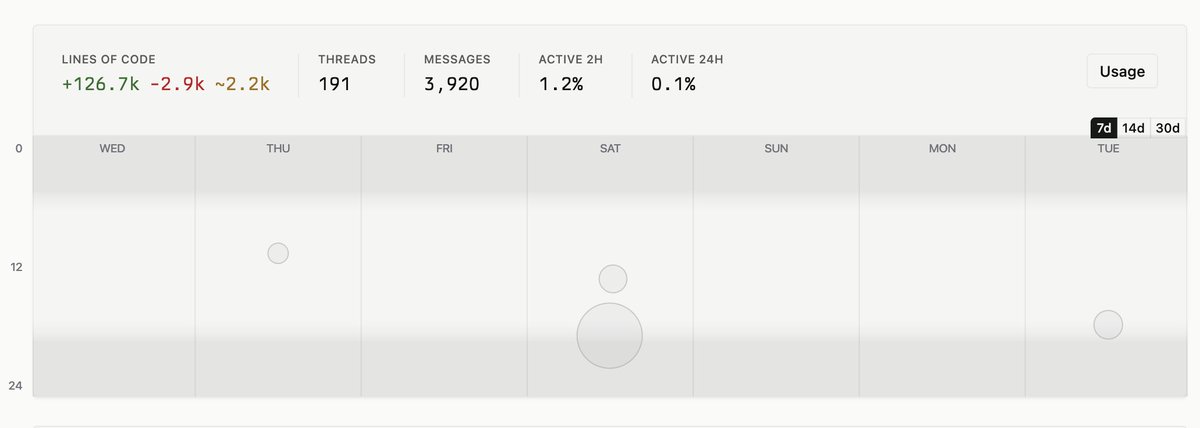
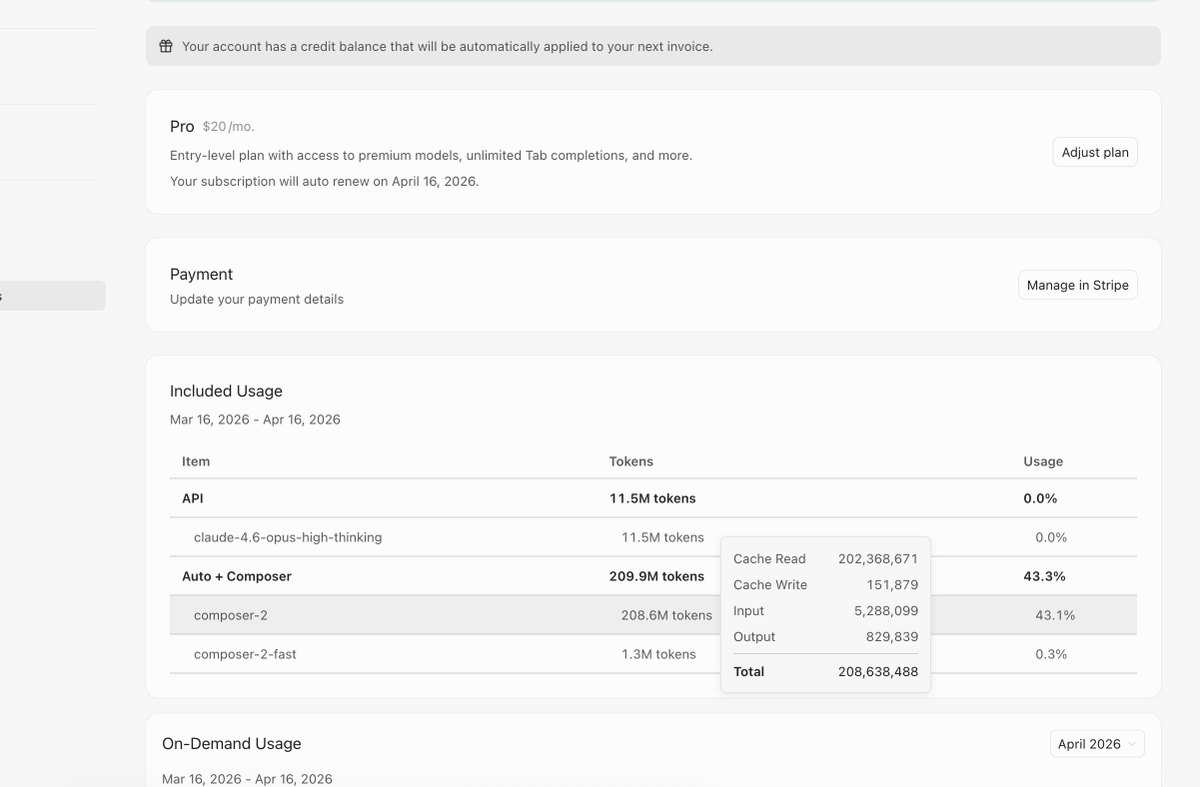
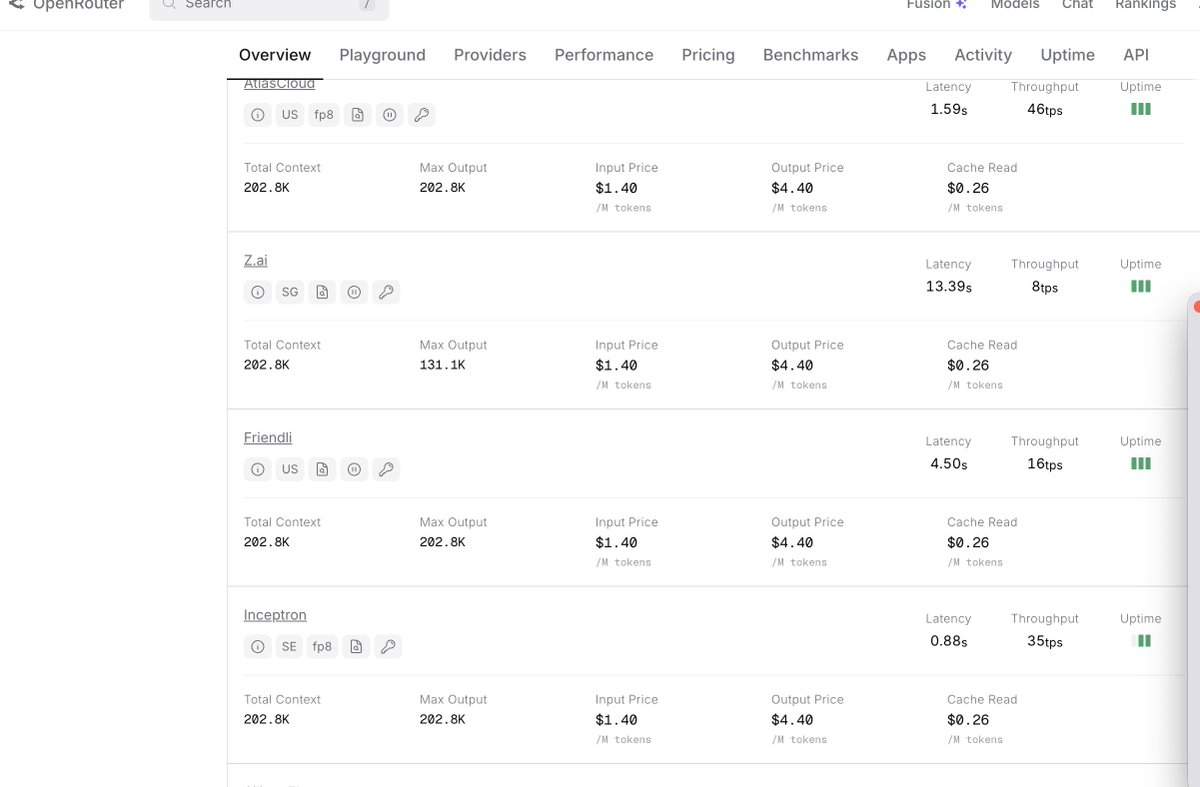
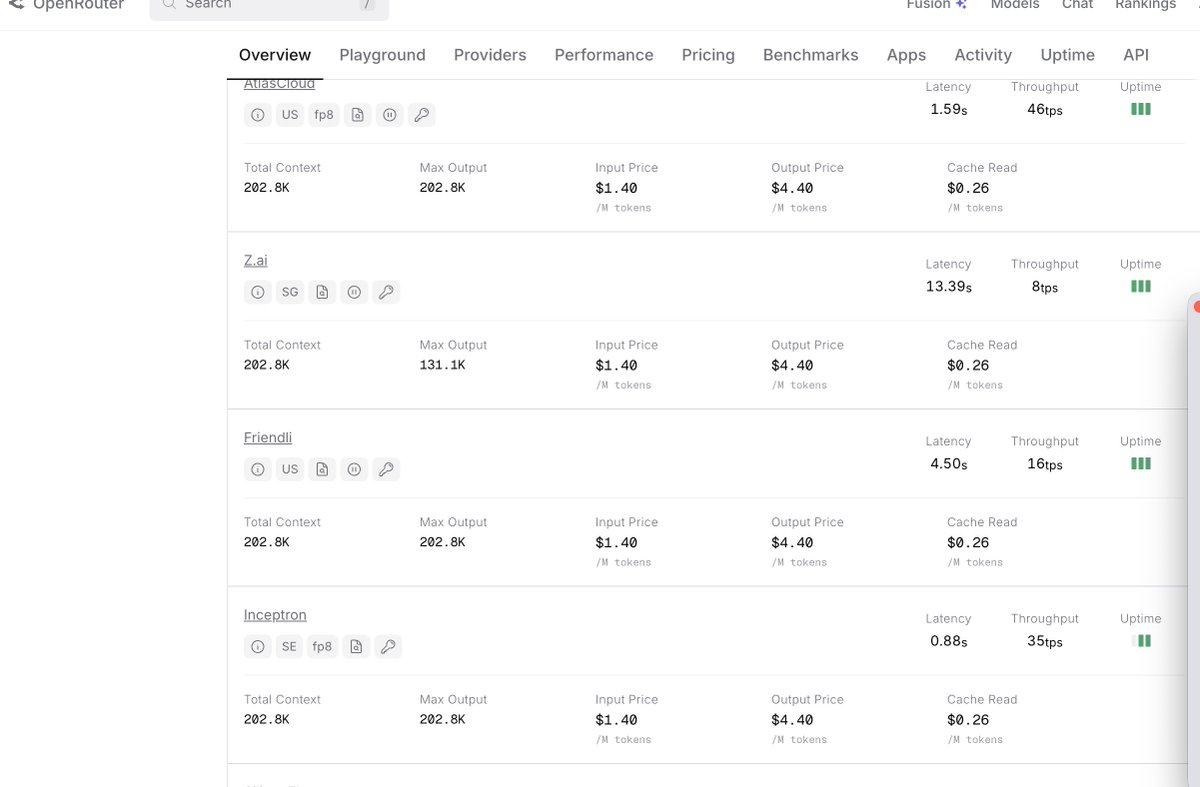

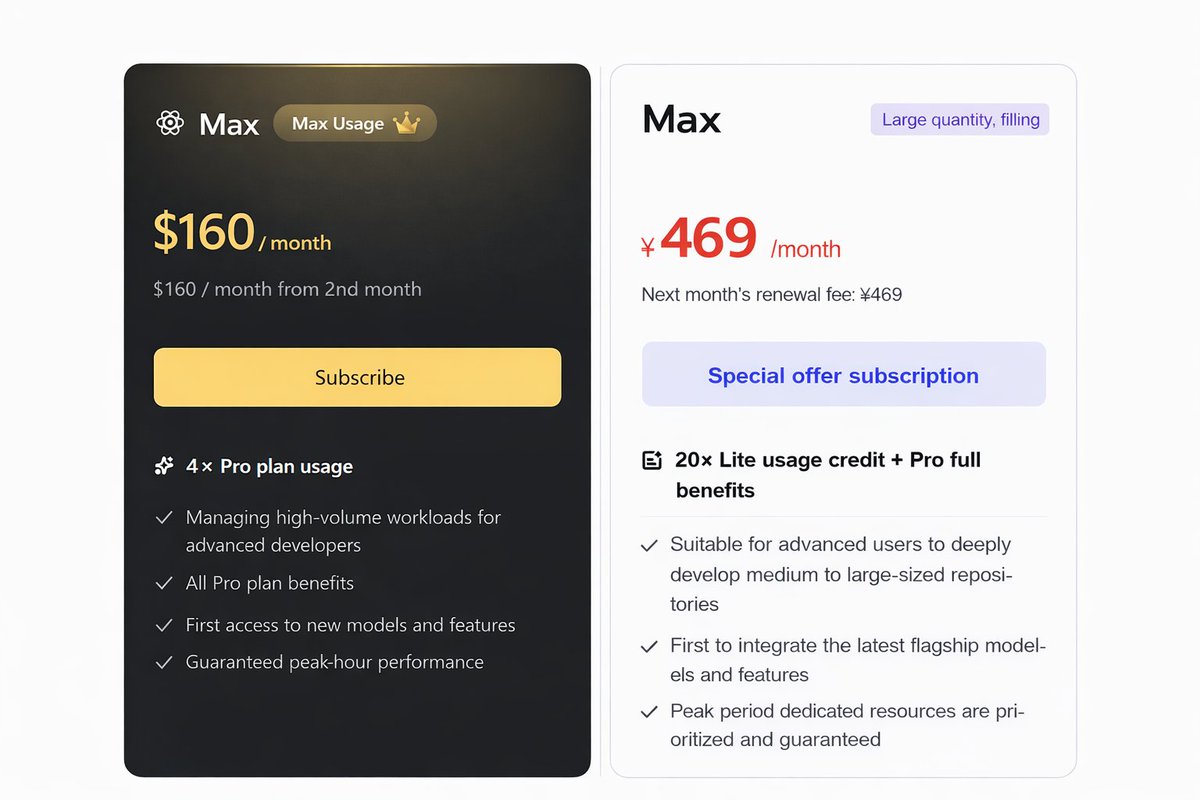

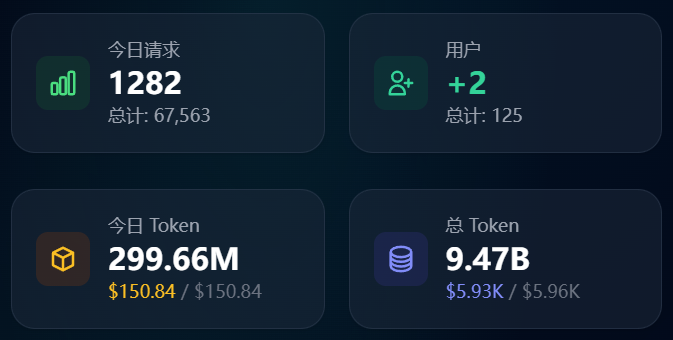
开放注册了:router.daoge.me 新注册送10刀额度🥰,不过为了防滥用目前暂时只允许qq和gmail邮箱注册🤔
We released Claude Opus 4.6 just two months ago. Today we're sharing some info on our new model, Claude Mythos Preview.