
Wei (Will) Feng
37 posts
Wei (Will) Feng
@weifengpy
PyTorch Distributed, FSDP, float8
United States Katılım Mart 2011
279 Takip Edilen104 Takipçiler

@weifengpy @axolotl_ai it worked great! just a few gotchas that was fixed in this PR:
github.com/axolotl-ai-clo…
English
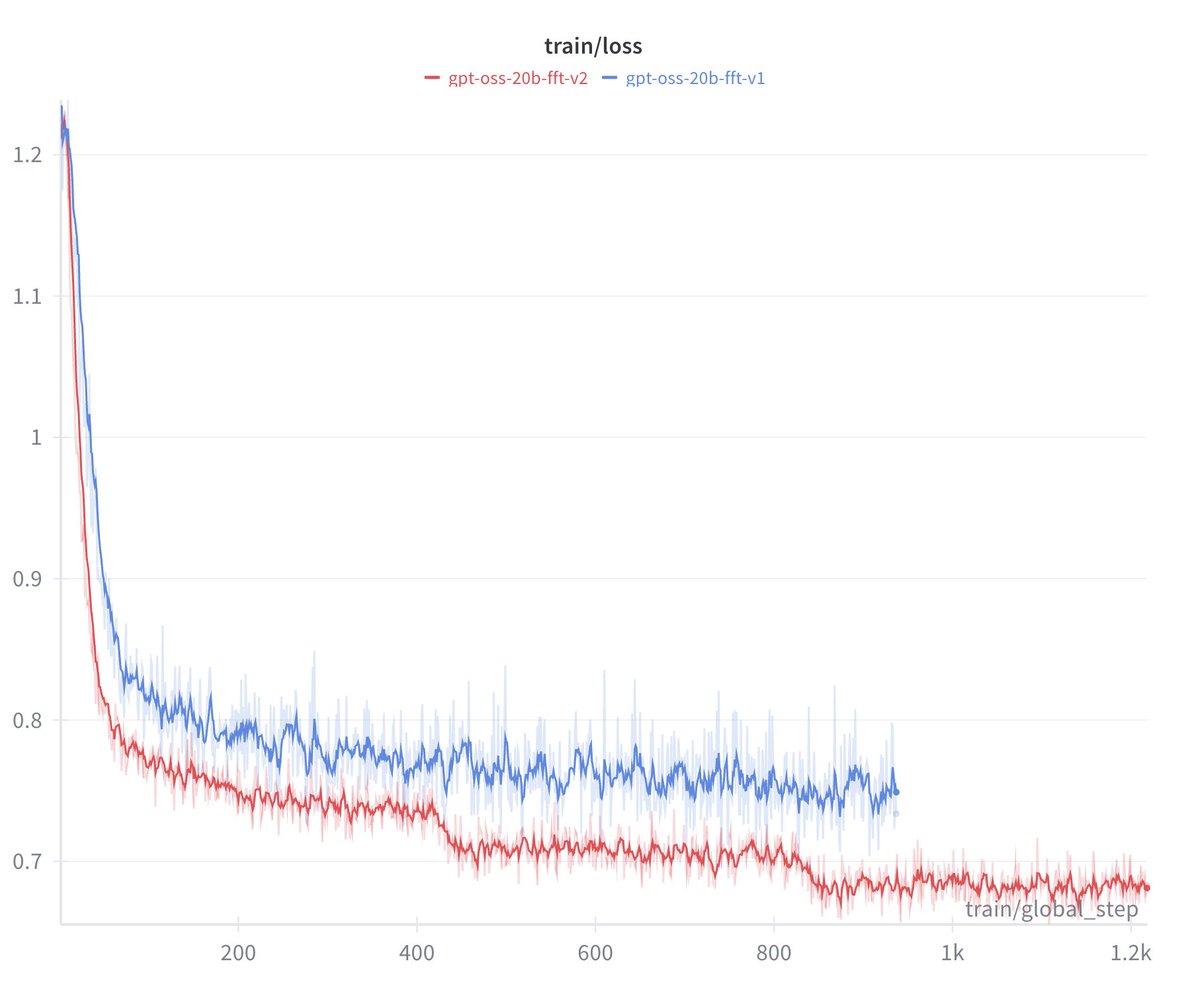
just wrapped a full fine-tuning test of gpt-oss 20b on medical reasoning datasets in @axolotl_ai, mainly to size up the resources needed for 20b in the future.
next up: 120b on a single H100, fsdp2, maybe even spectrum at 30%! LFG!🔥
Maziyar PANAHI@MaziyarPanahi
so, this is gonna be my evening! fine-tuning gpt-oss 120b in @axolotl_ai! LFG! 🔥
English
@iamgrigorev make a request at torchao nvfp4 and we can talk about this github.com/pytorch/ao/blo…
English

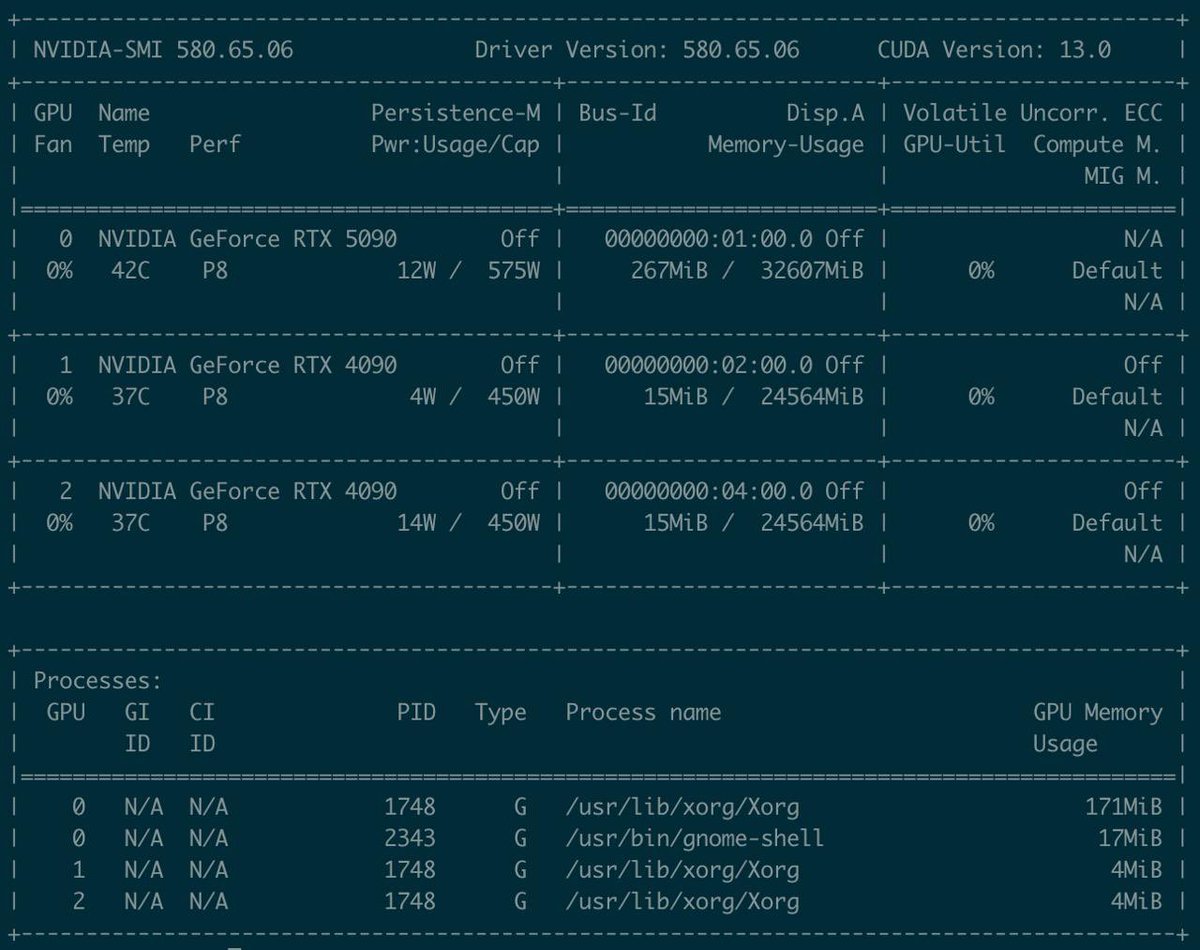
I wonder if I could push heterogeneity even further by training with fp4 on 5090 and fp8 on 4090 while sharding separately with FSDP2
English
@MaziyarPanahi verl uses torch==2.6.0 for fsdp2 but need some patch on state dict to address oom github.com/volcengine/ver…
English
the first bump!
"FSDP2 is not supported on torch version < 2.7.0"
😂
Maziyar PANAHI@MaziyarPanahi
so, this is gonna be my evening! fine-tuning gpt-oss 120b in @axolotl_ai! LFG! 🔥
English
@Infopulsed @maharshii the torchtitan way is apply AC, apply torch.compile, apply fsdp2. let fsdp2 hooks execute in eager and let forward execute in compile. but if you really need full graph capture, simplefsdp is our best offer #L92-L114" target="_blank" rel="nofollow noopener">github.com/pytorch/torcht…
English

@maharshii Try doing torch.compile with Fsdp2 on a base model, then you'll have a taste of it..
*Graph breaks
English

@EdmondD52582093 @HaHoang411 @_lewtun that's good to know. verl and nemo-rl both support fsdp2. might be helpful to you
English

@weifengpy @HaHoang411 @_lewtun I just started my from DDP to FSDP (SSL vision).
And a working example is a great place to start playing around, debugging and learning.
Really helped me get a footing.
English

It's been weeks, but I didn't notice. I've awaited this for so long.
TRL now supports FSDP2.
Thanks, @_lewtun.
Link: github.com/huggingface/tr…
English
English
@weifengpy @HaHoang411 @_lewtun A bit unrelated,
I just saw the example you added here: github.com/pytorch/exampl…
Really helpful as a ramp-up to the subject.
Thanks for that :)
English
@EthanBThoma @madhav1 which bug are you running into for fsdp2?
English

@madhav1 Fixing an issue with checkpoint loading with fsdp but I randomly decided to migrate to fsdp2 and I keep running into a pytorch bug skjsiwkw
English
@m_sirovatka @TheZachMueller sounds good. thanks for giving it a try on fsdp2
English

@weifengpy @TheZachMueller I just remember never being able to make it work, could as well be my skill issue, if I ever come across it again, I'll try to get you a repro
English

Early results show we’re doing a lesson on hooks
Zach Mueller@TheZachMueller
Quick poll, how familiar with @PyTorch hooks are you? do you understand the different types, their inputs, and how they differ/their use cases?
English
@TheZachMueller Last challenge - write a working pre-forward hook with kwargs on fsdp2 module 💀(never made it work)
English
@RameshArv1nd @intervitens the speedup is real when it’s compute bound
English

@intervitens Yeah I assumed there'd probably be no actual memory savings since it's casting to fp8 at each step. But I did notice pretty sizeable speedups at 8b / 32b. Was that not the case either? I guess with activation offloading and bz=1 it's probably less relevant
discuss.pytorch.org/t/distributed-…
English

Was fun working on, what seems to be, the first actual finetune of Qwen3-235B on HF. Had to learn, how to compile pytorch to get _grouped_mm support on sm100, and to use every single VRAM cope available in Torchtune to make it fit into the node.
🥭@MangoSweet78
huggingface.co/Aurore-Reveil/… Presenting one of the first Qwen3 large finetunes for RP - It's an experiment alright but it's... something. Trained mostly by @intervitens and his extreme knowledge about weird pytorch optims, Torchtune, Etc & Me (i sat in the corner and added hparams)
English
@danielhanchen @liloba994127 @UnslothAI Hi Daniel, let me know if you got any blockers around fsdp2. we can facilitate the enablement
English

@liloba994127 @UnslothAI We're working on it! But for now Accelerate should work hopefully
English
Gemma 3N quirks!
1. Vision NaNs on float16
2. Conv2D weights are large FP16 overflows to infinity
3. Large activations fixed vs Gemma 3
4. 6-7 training losses: normal for multimodal?
5. Large nums in msfa_ffn_pw_proj
6. NaNs fixed in @UnslothAI
Details: #fixes-for-gemma-3n" target="_blank" rel="nofollow noopener">docs.unsloth.ai/basics/gemma-3…

Unsloth AI@UnslothAI
You can now fine-tune Gemma 3n for free with our notebook! Unsloth makes Google Gemma training 1.5x faster with 50% less VRAM and 5x longer context lengths - with no accuracy loss. Guide: #fine-tuning-gemma-3n-with-unsloth" target="_blank" rel="nofollow noopener">docs.unsloth.ai/basics/gemma-3…
GitHub: github.com/unslothai/unsl… Colab: colab.research.google.com/github/unsloth… English
@bozavlado Hey Vlado, do you find fsdp2 code hard to understand?
English

@errantdata could I know more about 2) fsdp2 + autograd. is it resize_(0) that bothers you?
English
@Infopulsed @wanchao_ @giffmana @__kolesnikov__ @XiaohuaZhai we relaxed the assertion for int dtypes in pytorch nightly. if int dtypes paramters are not trainable, they can be mixed in a single all-gather
English
@wanchao_ @giffmana @__kolesnikov__ @XiaohuaZhai Yes, fsdp2 currently can't flatten int dtypes but can for float dtypes, there are issues already filed for this my bro🫡
English

hey all, couple quick notes:
1) yes, we will be joining Meta.
2) no, we did not get 100M sign-on, that's fake news.
Excited about what's ahead though, will share more in due time!
cc @__kolesnikov__ and @XiaohuaZhai.
English
@YouJiacheng @qsh_zh @JingyuanLiu123 @SeunghyunSEO7 @main_horse we are thinking about this. one possibility is customized reduce-scatter. perform GGT computation on unsharded gradients, and scatter them afterwards. probably will land some hooks into pytorch and examples to titan
English

@qsh_zh @JingyuanLiu123 @SeunghyunSEO7 @main_horse FSDP2 adopt a per layer sharding strategy so…
Need a custom FSDP I think.
English

I was intended to write a blog about Muon's infra scalability but basically it was what @SeunghyunSEO7 mentioned: it is caused by the zero 1 impl difference and dim 0 sharding is not scalable for Moonshot's impl.
So I just ended up writing some fun thoughts regarding Muon's concerns in Zhihu: zhihu.com/question/19271…
Seunghyun Seo@SeunghyunSEO7
@eliebakouch @JingyuanLiu123 @zxytim we've discussed this for a while. legacy megatron fsdp1 flatten all weights first and slice. but fsdp2 use per param sharding and it's useful for qlora like things. but moohshot's internel codebase is based on old megatron i guess so it does not match with fsdp2 well
English
@m_sirovatka Hi Matej, fsdp2 maintainer here. do you have script for repro?
English
On today's episode of obscure things happening to me in PyTorch (this is quickly becoming a serie I'm afraid):
FSDP2 submodule causes hang, impossible to debug as even having this submodule in locals causes the debugger to hang😭

English
@tokenpilled65B @andersonbcdefg @marksaroufim Hi Philippe, we just published FSDP2 tutorial docs.pytorch.org/tutorials/inte…
welcome your feedback
English

@andersonbcdefg @marksaroufim yeah PyTorch's documentation on FSDP is so poor
English

If you're interested in FSDP2, here's a minimal example courtesy of Andrew Gu
"""
torchrun --standalone --nproc_per_node=2 test_fsdp_basic.py
"""
import os
import torch
import torch.distributed as dist
from torch.distributed._composable.fsdp import fully_shard, MixedPrecisionPolicy
from torch.testing._internal.distributed._tensor.common_dtensor import (
ModelArgs,
Transformer,
TransformerBlock,
)
def main():
torch.manual_seed(42)
model_args = ModelArgs(
n_layers=12,
vocab_size=50304,
n_heads=32,
dim=2048,
max_seq_len=2048,
dropout_p=0.0,
)
model = Transformer(model_args)
mp_policy = MixedPrecisionPolicy(param_dtype=torch.bfloat16)
fsdp_cfg = {"mp_policy": mp_policy}
for module in model.modules():
if isinstance(module, TransformerBlock):
fully_shard(module, **fsdp_cfg)
fully_shard(model, **fsdp_cfg)
optim = torch.optim.AdamW(model.parameters(), lr=1e-2)
inp = torch.randint(0, model_args.vocab_size, (8, 1024), device="cuda")
model(inp).sum().backward()
optim.step()
if __name__ == "__main__":
dist.init_process_group(backend="nccl")
gpu_id = int(os.environ["LOCAL_RANK"])
device = f"cuda:{gpu_id}"
torch.cuda.set_device(device)
rank = gpu_id
main()
dist.destroy_process_group()
English
@andersonbcdefg @marksaroufim Hi Ben, we published FSDP2 tutorial docs.pytorch.org/tutorials/inte…
Thanks for reporting the problem to us
English

@marksaroufim any plans for a blog post akin to "getting started with DDP"? it's been a while since FSDP2 came out and still scant resources for getting up to speed with it :'(
English