will hang
27 posts


OK, now I HAVE to fine tune a vision model for identifying our chickens
Turist@Turist
@simonw on vision fine tuning and using that to identify the right chicken! Video by Latent Space
English

USD 184.19 - cost of GPT-4o vision fine-tuning on 10k images
I'd say it's craaaaazy expensive!
"Creating this fine-tuning job would exceed your hard limit, please check your plan and billing details. Cost of job ftjob-iPG6LWpOs1WNa5K98yQL2WAC: USD 184.19. Quota remaining for org-sLGE3gXNesVjtWzgho17NkRy: USD 119.97."
SkalskiP@skalskip92
it's going to be a loooong night
English
@skalskip92 @OpenAI Read the blog & watched parts of the stream, really loved them ❤️
If you set "detail" "low", images get resized to 512 x 512 and only result in 85 tokens if that's enough for your use case (it might not be).
Would love to chat about the other perf issues, feel free to DM me!
English
@mengdi_en @OpenAI Nice!! Only half though?? I'll think about how we can do better.
English

I tried OpenAI's new vision fine-tuning and now it knows new Pokemons from Gen 9.
But... it's really more expensive than expected. Although it's free up 1M tokens, it's really easy to exceed that limit. 2583 small images costed 2,741,292 tokens and $43.53 after the discount.

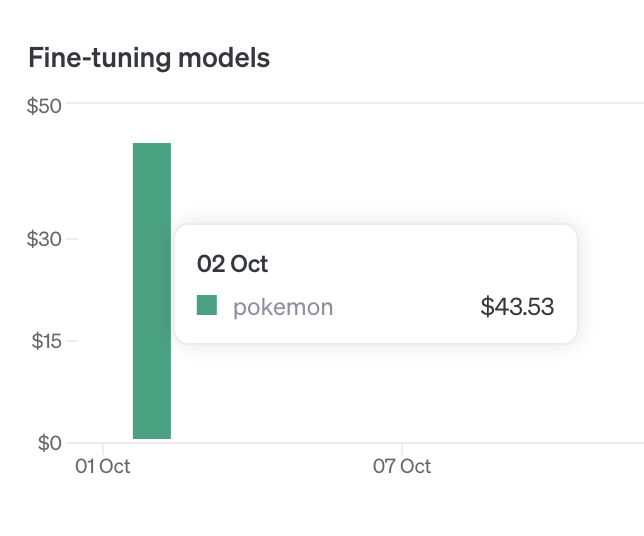
English
@mengdi_en @OpenAI I think it should still help because even for small images, we will turn them into 255 tokens at minimum. We'll be extra clear about this in our docs. See if for a dataset of 20 images (should be free) if you see a difference, and please DM me if you don't!
English
@willhang_ @OpenAI Hi will! I did not add that, but majority of the images are very small like this one raw.githubusercontent.com/PokeAPI/sprite…
Large ones are like this raw.githubusercontent.com/PokeAPI/sprite…
Would "detail": "low" still help reduce cost in this case?
English
@skalskip92 @OpenAI I don't recommend this for use cases where you need higher resolution images, but for the poker card use case, I think you can still get good perf at a lower price point.
English
@skalskip92 Hey @skalskip92! I lead vision fine-tuning at @OpenAI, thank you so much for the feature! I hear you on the cost and moderation front. Did you try "detail" "low" to reduce the token count for image inputs to make it cheaper?
English
I documented my GPT-4o fine-tuning in this blogpost.
- Dataset format
- Step-by-step instructions
- Cost and considerations for fine-tuning GPT-4o
link: blog.roboflow.com/gpt-4o-object-…
English
@MervinPraison @OpenAI @OpenAINewsroom @OpenAIDevs Hey @MervinPraison! I lead vision fine-tuning at @OpenAI, thank you so much for featuring us!
English

Fine-tune GPT-4o with images: Tutorial
🖼️ Improve vision capability
🔄 Fine-tuning for beginners
📊 No-code dashboard interface
🚀 Train model with custom data
🔗 Use trained model via API
📚 Prepare dataset with images
@OpenAI @OpenAINewsroom @OpenAIDevs #DevDay #DevDay2024 #OpenAIDevDay
English

shout out to @willhang_ who led development of this feature
English
will hang retweetledi
super excited to launch vision fine tuning today - it was the top feature request to the fine tuning team. keep those ideas coming!
OpenAI Developers@OpenAIDevs
🖼️ We’re adding support for vision fine-tuning. You can now fine-tune GPT-4o with images, in addition to text. Free training till October 31, up to 1M tokens a day. openai.com/index/introduc…
English
will hang retweetledi

realtime api (speech-to-speech): openai.com/index/introduc…
vision in the fine-tuning api: openai.com/index/introduc…
prompt caching (50% discounts and faster processing for recently-seen input tokens):
openai.com/index/api-prom…
model distillation (!!):
openai.com/index/api-mode…
English
will hang retweetledi

🖼️ We’re adding support for vision fine-tuning. You can now fine-tune GPT-4o with images, in addition to text. Free training till October 31, up to 1M tokens a day. openai.com/index/introduc…
English
will hang retweetledi

Welcome, AlphaChip!
Today, we are sharing some exciting updates on our work published in @Nature in 2021 on using reinforcement learning for ASIC chip floorplanning and layout. We’re also naming this work AlphaChip.
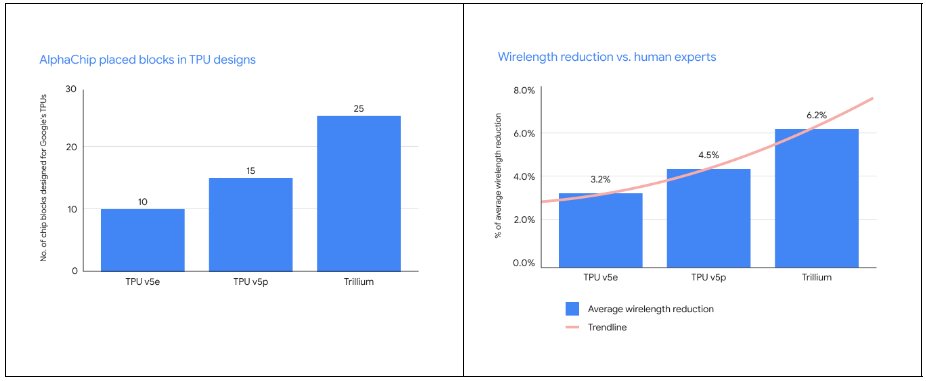
Since we first published this work, our use of this approach internally has grown significantly. It has now been used for multiple generations of TPU chips (TPU v5e, TPU v5p, and Trillium), with AlphaChip placing an increasing number of blocks and with larger wirelength reductions vs. human experts from generation to generation:
AlphaChip has also been used with excellent results for other chips across Alphabet, including Google’s Axion chip, an Arm-based general-purpose data center CPU.
In 2022, as a companion to the Nature paper, we open-sourced the code for the AlphaChip algorithms described in the Nature paper (see link below). Since then, external researchers could use this repository to pre-train on a variety of chip blocks and then apply the pre-trained model to new blocks, as was done and described in our original paper.
Today we’re also releasing a pre-trained AlphaChip checkpoint for the open source release that makes it easier for external users to get started using AlphaChip for their own chip designs.
Original Nature paper w/ wonderful joint first authors @Azaliamirh + @annadgoldie, and @mnyazgan, @joesmemory, @ESonghori, @ShenWangURC, @xylophi, @efjohnson, @pathomkar, @Azade_na, @PakJiwoo, Andy Tong, @kavyasrinivas23, @willhang_, @emretuncer, @quocleix, @JamesLaudon, @rh00, Roger Carpenter, and myself):
nature.com/articles/s4158… (PDF: rdcu.be/cmedX)
Today’s Addendum to the paper published in Nature: nature.com/articles/s4158… (same authors)
AlphaChip blog post: deepmind.google/discover/blog/…
Open source release: github.com/google-researc…
Pre-trained checkpoint: #PreTrainedModelCheckpoint" target="_blank" rel="nofollow noopener">github.com/google-researc…
Three things we have observed in the external community are described in the Nature Addendum: (1) not doing any pre-training (circumventing the learning aspects of our method by removing its ability to learn from prior experience) (2) not training to convergence (standard practice in ML methods), and (3) using fewer computational resources than described in our Nature paper (using fewer resources is likely to harm performance, or require running for considerably longer to achieve the same performance).
Pre-training the model for it to learn the craft of chip layout and to be able to generalize to new designs is an important part of our method. The pre-training process requires some effort to perform, since one has to find representative blocks and then run a lengthy computational process to pre-train the model to be good at placing those blocks. To avoid external users having to perform this process and make it easier for the external community to use AlphaChip, today we are releasing an AlphaChip model checkpoint pre-trained on 20 TPU blocks. This will enable users to get good zero-shot performance and faster convergence for novel blocks right out of the box. (For best results, however, we continue to recommend that developers pre-train on their own in-distribution blocks, and we provide a tutorial on how to perform pre-training with our open-source repository: see the Addendum).
Many organizations have used AlphaChip as a building block for their own chip design efforts. For example, MediaTek, one of the top chip design companies in the world, extended AlphaChip to accelerate development of their most advanced chips (e.g. the Dimensity Flagship 5G used in Samsung mobile phones), while improving power, performance and chip area.
We’re very excited about the increasing impact of AlphaChip internally and externally, and we look forward to continued work in this space to make custom higher performance, more efficient, and more capable chips dramatically easier to design and build.
Google DeepMind@GoogleDeepMind
Our AI for chip design method AlphaChip has transformed the way we design microchips. ⚡ From helping to design state-of-the-art TPUs for building AI models to CPUs in data centers - its widespread impact can be seen across Alphabet and beyond. Find out more → dpmd.ai/3ZDRtYY
English
will hang retweetledi

We are sharing some exciting updates about our work on AI for layout optimization, more than five years after its inception! First, we are announcing its new name: AlphaChip!
deepmind.google/discover/blog/…
English
will hang retweetledi
@john__allard huge thanks to the many others on the API team who helped with this launch: @andrwpng @michpokrass @oliviergodement @owencm @slessans @sherwinwu @willhang_
English
will hang retweetledi
@OpenAI huge shout-out to the fine-tuning eng team @john__allard @andrwpng @willhang_ and @slessans for sprinting all weekend to get this launched just days after the gpt-4o-mini launch
English
will hang retweetledi
Customize GPT-4o mini for your application with fine-tuning. Available today to tier 4 and 5 users, we plan to gradually expand access to all tiers. First 2M training tokens a day are free, through Sept 23.
platform.openai.com/docs/guides/fi…
English