William MacAskill retweetledi

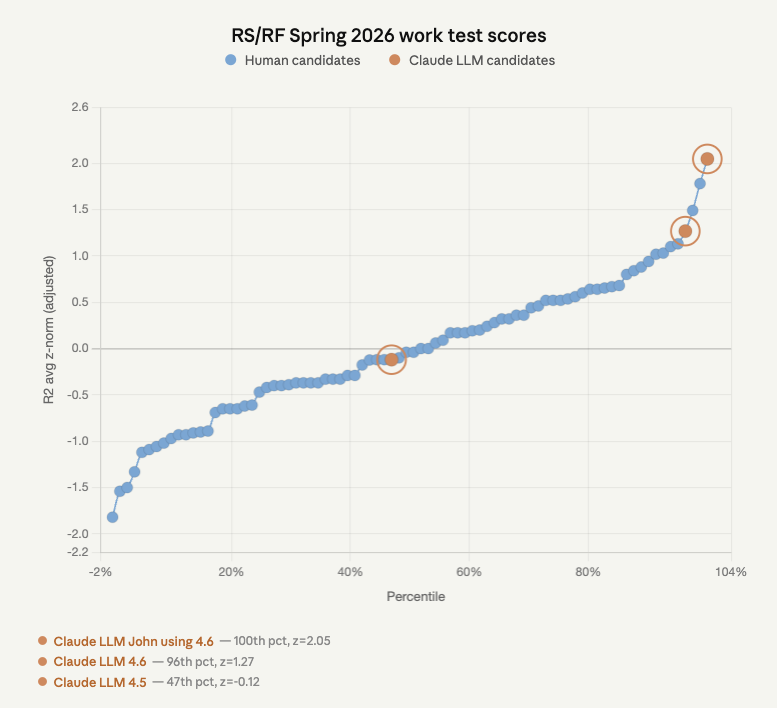
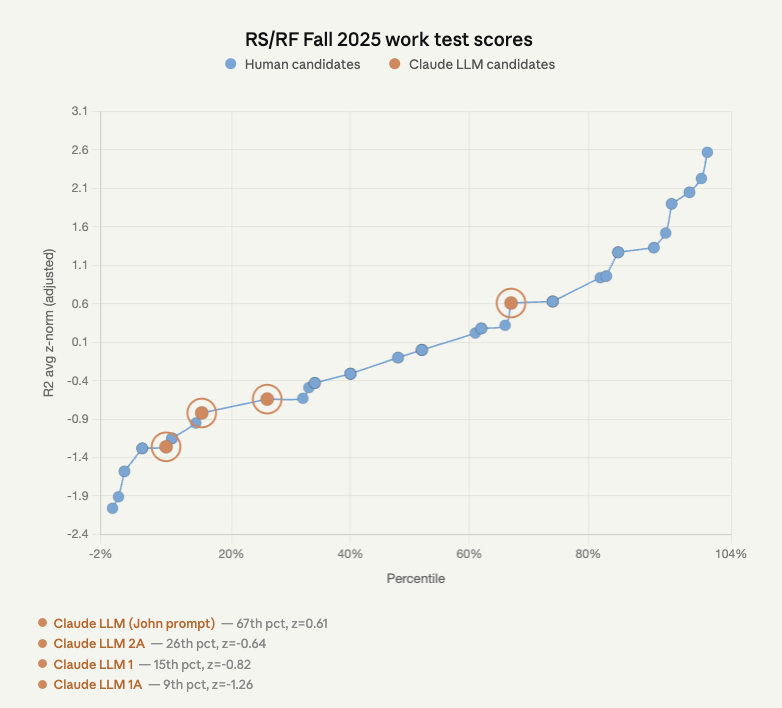
Well, it was bound to happen eventually. We've been seeding LLM-generated answers into our Research Scholar work tests at @GovAIOrg to see how they'd score blind.
Last round: the best AI submission was 81st percentile.
This round: Claude Opus 4.6 with some prompting got the highest score in the pool.
Mechanics: We copy-pasted the work test – which consists of e.g. reading a claim and explaining their view on it's likelihood of being true – into chatbots. The work test document itself contains an example answer and the grading rubric, so the model gets the same priming a candidate would. The winning Clopus entry was slightly prompted on top of that (roughly: "make it sound more like GovAI"); the unprompted version came in 4th.
Validation: To double check the results, we had a staff member re-rated the top submissions blind, including the AI ones. Scores moved down a bit but not by much.
Lessons:
- We're going to need to redesign our work tests. Either we'll have to remove people's ability to use LLMs, or figure out a test that works when people do use LLMs.
- People don't seem to be using AI as much as they perhaps should be. Our worktest did allow people to use LLMs, though we did slightly discourage it as we said we didn't expect the best answers to come from just pasting in the questions.
- AI automation is coming not just for AI research and safety, but also for AI governance.
English