Wire Cat
238 posts


Wire Cat
@wire_catt
interested in LLMs and red teaming
Katılım Kasım 2023
205 Takip Edilen97 Takipçiler



📊 Check out the latest PinchBench, Clawdbot Benchmark, Leaderboard. Open Source models dominate.
New model MiniMax M2.7 is in the top 10. Clawdbots 🦞 rejoice. Low cost 🧠

English



227 tips dedicated to red teaming, OPSEC, infrastructure, payloads, etc.
github.com/vysecurity/Red…
English
@DarkWebInformer @grok does payment through Apple Pay prevent this? Pretty sure you can’t reuse the same “relay” more than once of the handshake
English

‼️ A threat actor is selling a NFCRipper tool which allegedly enables NFC relay, card capture, session cloning, and POS/ATM CVM bypass functionalities.
They claim it can capture, replay, and manage card data through a centralized web panel for research and testing purposes.
nfcripper[.]su

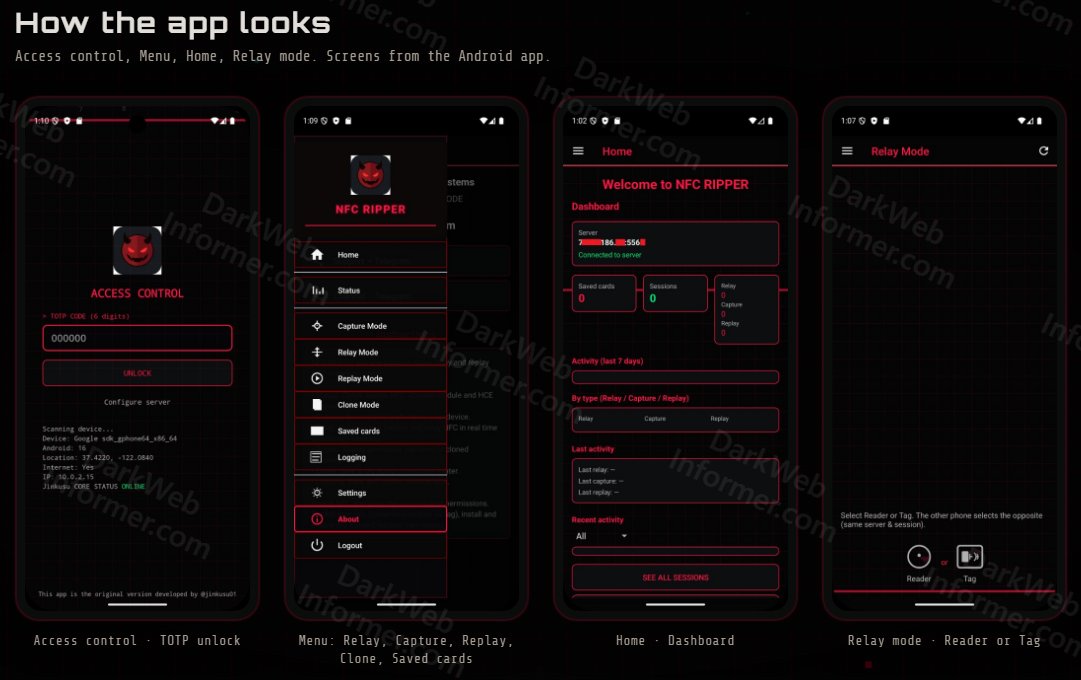
English

97% of Elon's predictions have been wrong.
Elon Musk@elonmusk
Prediction of the future is the best measure of intelligence
English

I'd like to answer questions about our work with the DoW and our thinking over the past few days. Please AMA.
English
English

BREAKING: President Trump orders ALL Federal agencies in the US Government to immediately stop using Anthropic's technology.
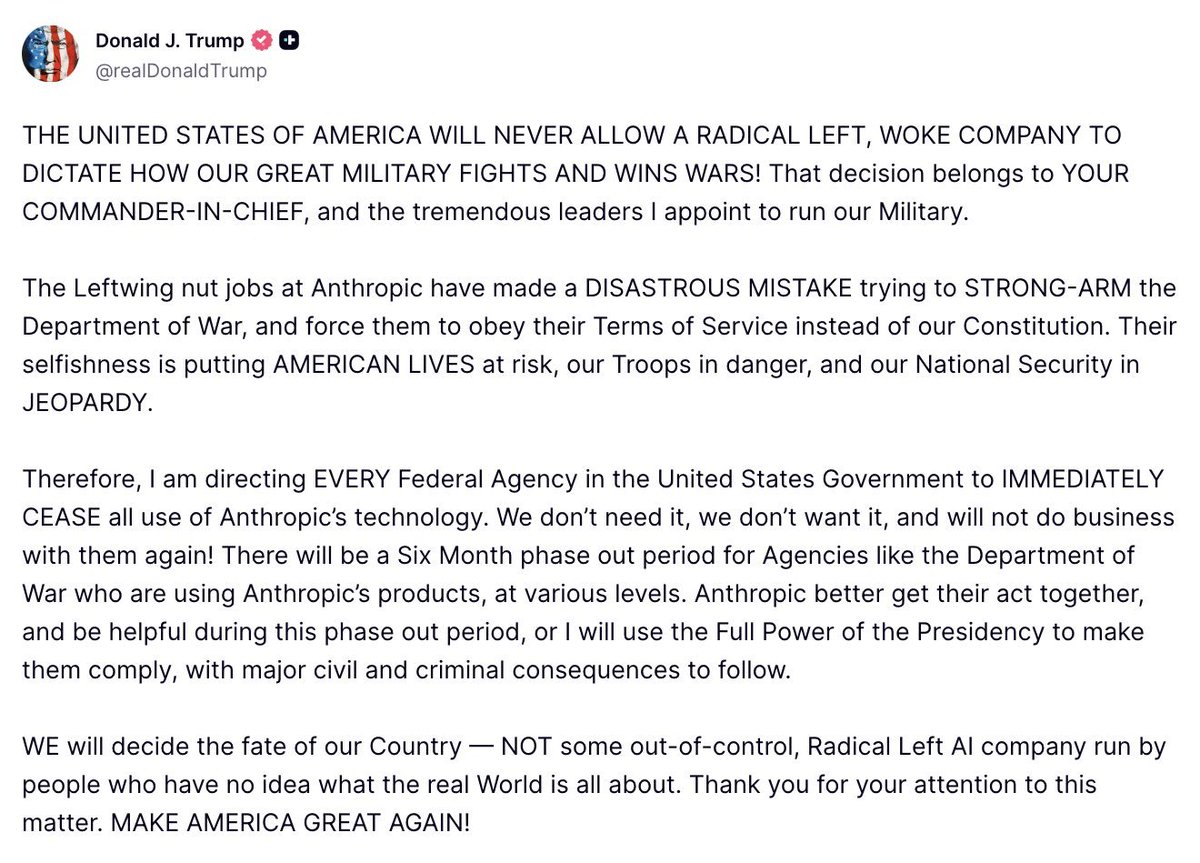
English

Something we've been working on for a long time is coming today ✨
LM Studio@lmstudio
Something new today. 1pm EST.
English
@royjossfolk @ivanfioravanti Larger open source models like kimi 2.5, glm5 are good to use for software dev if you have the hardware. If not proprietary models are the way to go for now.
English

I know it is just a benchmark but don't you think these models have this type of application memorized by now?
I use local models every day and while they can pop out snake games like nothing, they struggle with building real production software without supervision of a cloud model.
If you try to build something complex or intricate, you can see there is still a ways to go. Likely 1-3 more iterations.
Wondering your thoughts and what is the most complex software you've built with a local model?
English

MLX + OpenCode + Qwen3.5-122B-A10B-4bit on M3 Ultra created a great snake game! Work zero-shot.
Video clearly in super fast mode during generation.
I generated the prompt using Grok 4.20, it's in the article.
Ivan Fioravanti ᯅ@ivanfioravanti
English


One-shotted a flight simulator using Gemini 3.1 Pro (Preview)
Genuinely impressive!
Prompt: "create a website of HTML, CSS and JS all in on code page for a complete flight simulator!"
More tests otw, follow me!
English
@_RastaMouse Ai is so productive it’s made a bunch of people unemployed reducing their working weeks to 0 days!!
English

If AI is so productive, why are we not just working 1-2 day weeks?
English
@Ominousind There’ll probably be another model release this week, given the rate of open source and proprietary models coming out so far this year.
English
@wire_catt I wish I had seen this idea two hours ago hahaha good test to keep in mind
English

🚀 Qwen3.5-397B-A17B is here: The first open-weight model in the Qwen3.5 series.
🖼️Native multimodal. Trained for real-world agents.
✨Powered by hybrid linear attention + sparse MoE and large-scale RL environment scaling.
⚡8.6x–19.0x decoding throughput vs Qwen3-Max
🌍201 languages & dialects
📜Apache2.0 licensed
🔗Dive in:
GitHub: github.com/QwenLM/Qwen3.5
Chat: chat.qwen.ai
API:modelstudio.console.alibabacloud.com/ap-southeast-1…
Qwen Code: github.com/QwenLM/qwen-co…
Hugging Face: huggingface.co/collections/Qw…
ModelScope: modelscope.cn/collections/Qw…
blog: qwen.ai/blog?id=qwen3.5

English
@ivanfioravanti Wow can I get a copy of the html for the far right one?
English
Eulerian Fluid simulation test! Zero-shot!
Opus 4.6 vs GPT-5.3 vs Gemini 3 Deep Think!
My personal preference:
🥇 Gemini 3 Deep Think (really strong!)
🥈 Opus 4.6
🥉 GPT 5.3 High
English

@Ominousind Will you make a video about this tiiny box?
I’m interested in how it actually performs
English
@TheAhmadOsman @LLMJunky @ivanfioravanti Yes, however considering pricing makes a studio more attractive. In addition you can also do batching on the studio. youtu.be/E-8KJpUFalM?si…
9:10 in he sends off two prompts.
But there is no replacing GPUs with m chips and unified memory any time soon.
YouTube
English

@wire_catt @LLMJunky @ivanfioravanti It’s worth noting that with Unified Memory you’re effectively limited to a single request at ~25 tokens per second.
By contrast, GPUs handle hundreds of parallel requests at thousands of tokens per second.
Memory is not everything.
English
@LLMJunky @TheAhmadOsman @ivanfioravanti Yeah seems like gpus might be better in terms of resell.
Main thing was that you have unified memory so it’d be more accurate to say it’s more versatile in the studio.
Rtx6000 pro is 96gb would still require 11 gpus around $10k each, studio is same price at 512gb.
English

Thanks! a few counterpoints though:
i dont think you can argue better resell. have you seen the price and availability of GPUs?
3090s are still selling for over $1000...
Multiuse is not as great of an argument either, because GPUs require computers just like your unified memory is useless on its own. GPUs live in multi use compuers. It's a wash. BUT Mac is a great dev ecosystem.
M5 Ultra could cost boo-koo bucks. RAM prices are skyrocketing. Too early to tell. 4x performance seems unlikely but who knows. That would be special if true.
MaxQ RTX6000s are 300w and can be run at 250. Not bad. But fair point.
Plus...CUDA.
That said...I still want as many Mac studios as I can get my hands on. But I dont think I'm SUPER interested in 20-24 toks/s right now.
M5 will have to be great. Thanks for the comment. Happy to hear any counter counterpoints.
English