Sabitlenmiş Tweet

this is the #1 mech interp paper submitted to ICLR, according to the ratings spreadsheet i posted 3 months ago, which stood uncontested.
work by @_MichaelPearce, @thomasdooms, myself, @jaom7, and @leedsharkey. cheers, it was a great collab. paper link: arxiv.org/abs/2410.08417
tdooms@thomasdooms
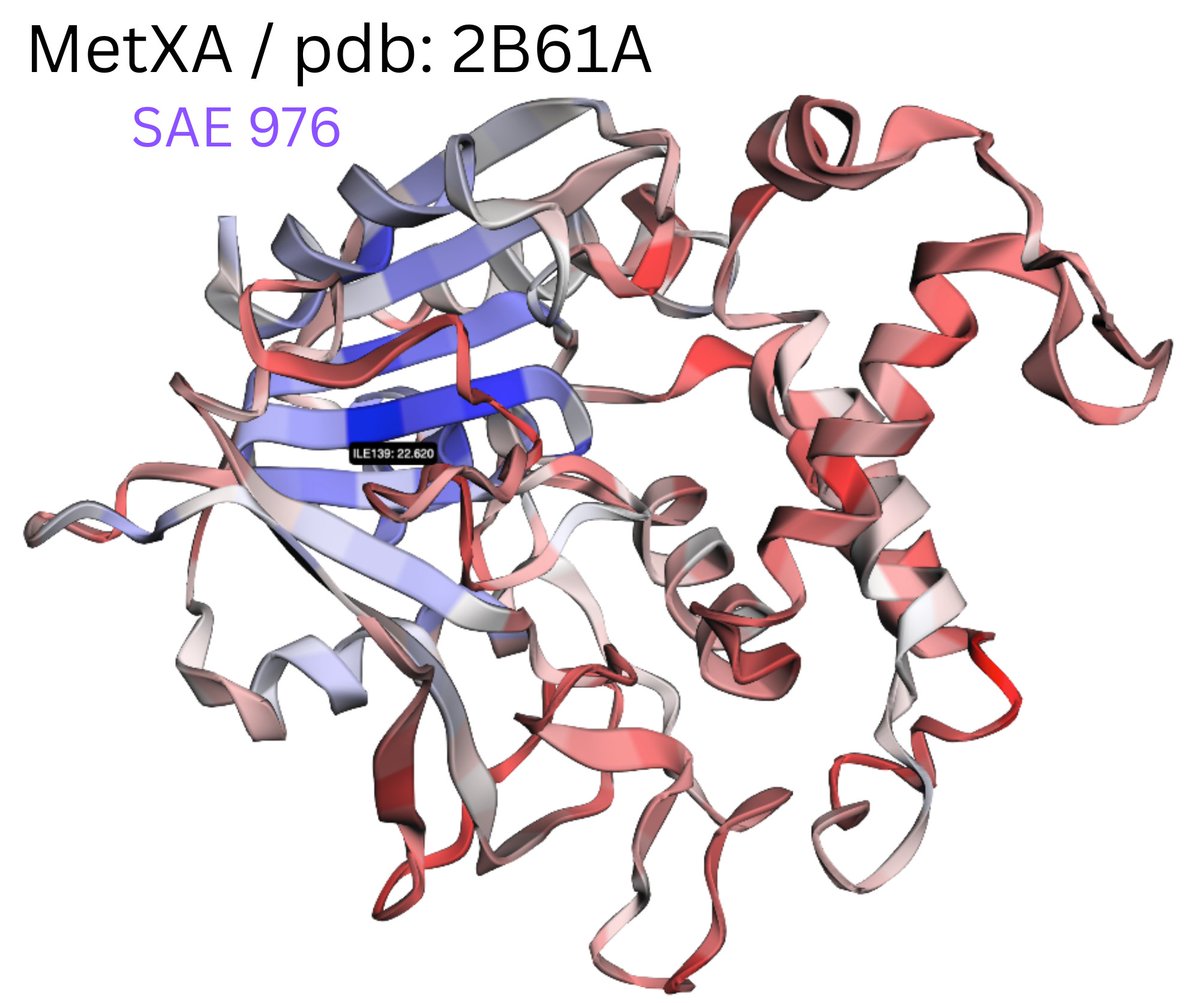
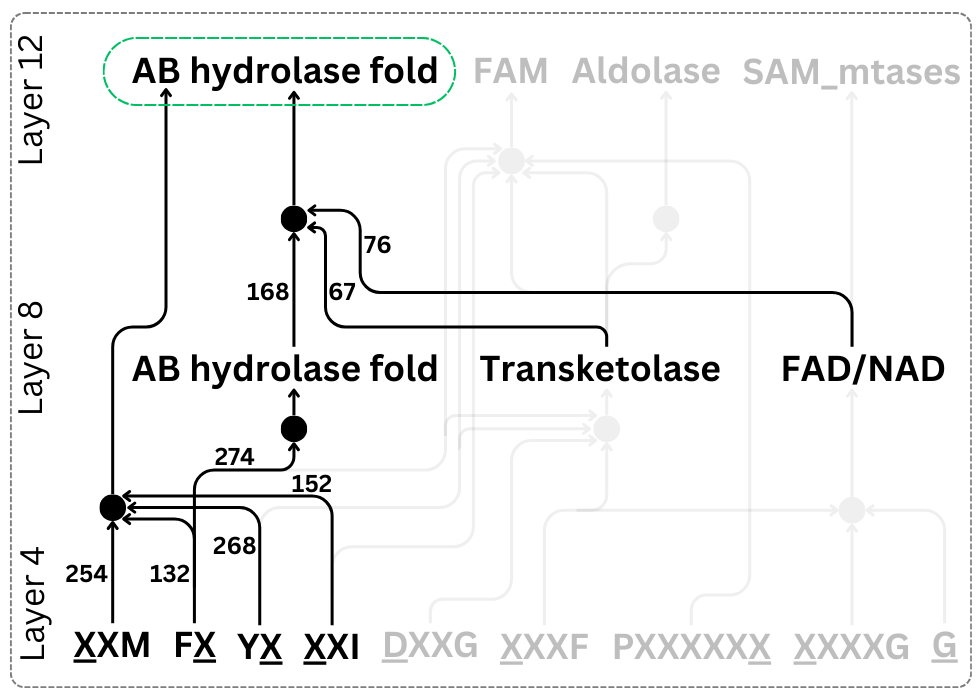
Can we understand neural networks from their weights? Often, the answer is no. An MLP's activation function obscures the relationship between inputs, outputs, and weights. In our new ICLR'25 paper, we study "bilinear MLPs", a special MLP that's performant AND interpretable! 🧵
English