Sabitlenmiş Tweet

Merry Christmas to the half of the world right now while the other half is still counting down. 2025 has been an amazing year for @Gradient_HQ let’s carry on for something bigger and better for 2k26.


English
xTUBOL ./
243 posts




NEWS: xAI is reportedly using just 11% of its 550,000 NVIDIA GPUs, while Meta and Google squeeze 43-46% out of theirs. According to a report from The Information, xAI's massive Memphis and Colossus GPU clusters, packed with H100s and H200s including liquid-cooled setups, are running at only around 11% utilization. That works out to roughly 60,000 active GPUs out of the 550,000 installed. The issue is not unique to xAI. Running hundreds of thousands of GPUs efficiently is one of the hardest challenges in AI today. As clusters scale up, idle time piles up fast and software stacks struggle to keep up. Meta and Google have invested heavily in their software optimization, hitting 43% and 46% utilization respectively. xAI's distributed training network and software stack are still maturing, leading to longer idle times and bottlenecks in the data pipeline. xAI is targeting 50% utilization through future infrastructure and software upgrades. The company may also start renting out its GPU fleet as it shifts workloads to hardware better suited for agentic AI tasks. On top of this, Elon Musk is doubling down on the Terafab project, building in-house silicon and tapping Intel's 14A technology to power the next generation of xAI, SpaceX and Tesla compute needs. Source: The Information
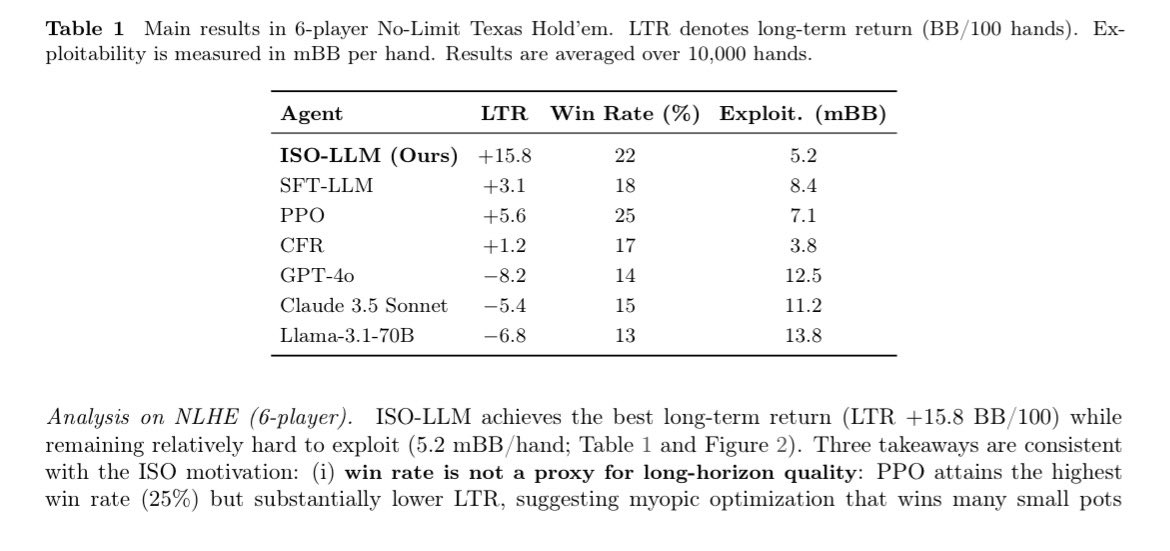
In long horizon adversarial decision making, the strategy comes from constantly evolving decisions in games like No-Limit Texas Hold’em. Standard RL training focuses on short term rewards mechanisms (short sightedness), which is powerful short term but collapses in a long term strategy (contextual blindness). ISO (Implicit Strategic Optimization) framework is designed to solve these issues by combining experts with a specialized long horizon reward system: A - Strategic Reward Model, the agent is trained using an SRM that prioritizes moves with high long term value, essentially teaching it "patience" and strategy. B - Contextual Mechanism, live interaction, a Context Predictor guesses hidden variables (like an opponent's hidden cards or playstyle). It then "routes" the decision to a specific Context Conditioned Policy optimized for that exact scenario, allowing the agent to adapt its strategy mid-game as new information is revealed. Combining these, the ISO agent can suppress impulsive, short term gains and instead prioritize high level strategies that lead to consistent long term success. @Gradient_HQ ✍️







⬜️⬜️⬜️ ⬜️ ⬜️ ⬜️ ⬜️⬜️ ⬜️⬜️⬜️ ⬜️⬜️⬜️ ⬜️⬜️⬜️ ⬜️ ⬜️ ⬜️ ⬜️ ⬜️ ⬜️ ⬜️⬜️⬜️ ⬜️⬜️⬜️ ⬜️ ⬜️ ⬜️⬜️⬜️ ◻️◻️ ./ training mode on… @Gradient_HQ
fairytale is imaginary. intelligence is forever. ./ asyncing echo rl… @Gradient_HQ

VeriLLM - Bringing Integrity and Verification to Distributed Intelligence. for less than 1% of the inference cost you can verify if the output is truly what you requested. engineering distributed inference with fully verifiable transparency. current solutions of - cross checking outputs introduces redundancy in multiplying cost from the comparisons for outputs. - zkp’s computational complexity which introduces significant latency making it impractical for on demand inference. both of which can significantly impact scalability and financial cost. @Gradient_HQ addresses the issues of models being swapped, output tampering and high cost with the introduction VeriLLM. both inference & verification are served in the same worker pool. reducing cost and maximizing utilization. here are the evaluations of VeriLLM serving inferences on heterogeneous machines table 3 compares the output of the Qwen2.5-7B-Instruct model running on an Mac M4 vs an RTX 5090. this establishes how much "natural" numerical variation exists between different machines: - low mean (near zero, ranging from -0.003 to 0.009) and predominance of small differences (most delta < 0.2) table 4 compares a compressed model (AWQ quantized) running on an RTX 5090 vs standard model running on a Mac M4. this tests if the verification protocol can still work when the "worker" uses a faster, lower precision version of the model: - exact matches are near zero, large delta (>0.2 and >5) dominate and scale with length and mean is consistently non-zero (up to 0.021) with alternating signs. table 4 highlights dishonest work from worker using quantization, which is exactly what VeriLLM aims to catch. models being swapped or substituted rigging the output. VeriLLM is able to identify honest full precision runs from quantized ones, across different machines.

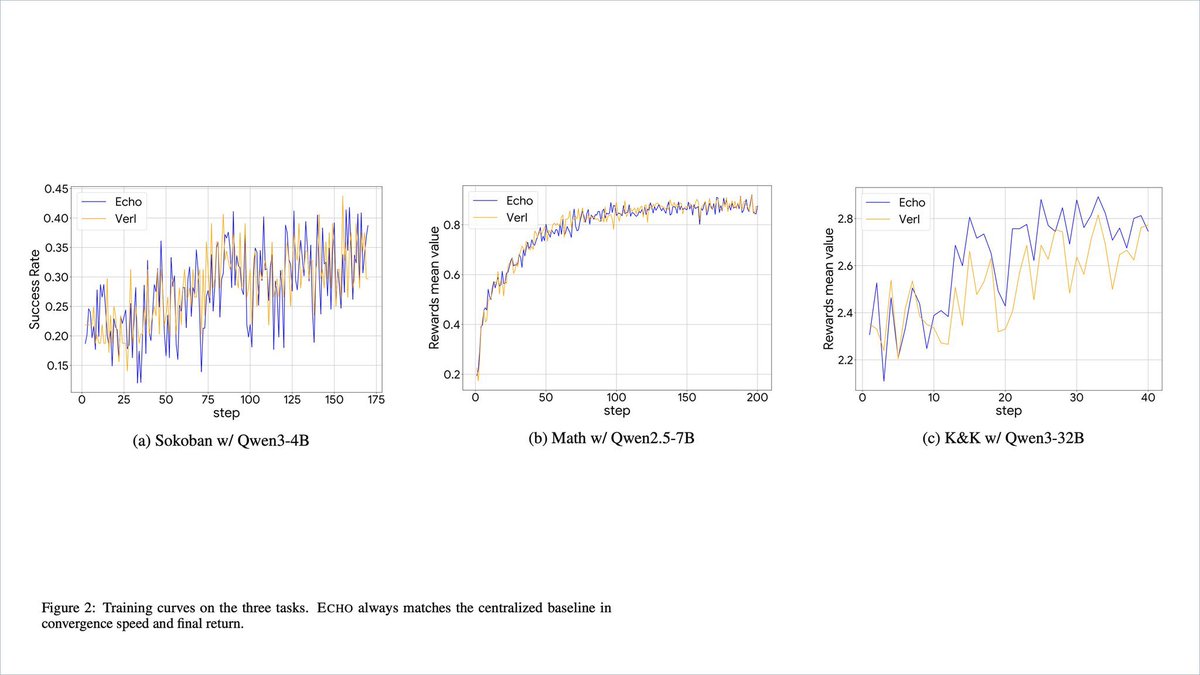
A previous display of Echo trained 30B Sokoban, leading performance against much larger model comparisons of DeepSeek R1 and GPT-OSS-120B ./ Echo by @Gradient_HQ scales reinforcement learning with consumer machines, drastically reducing the cost of building better intelligences







